一眼看懂
封面预览
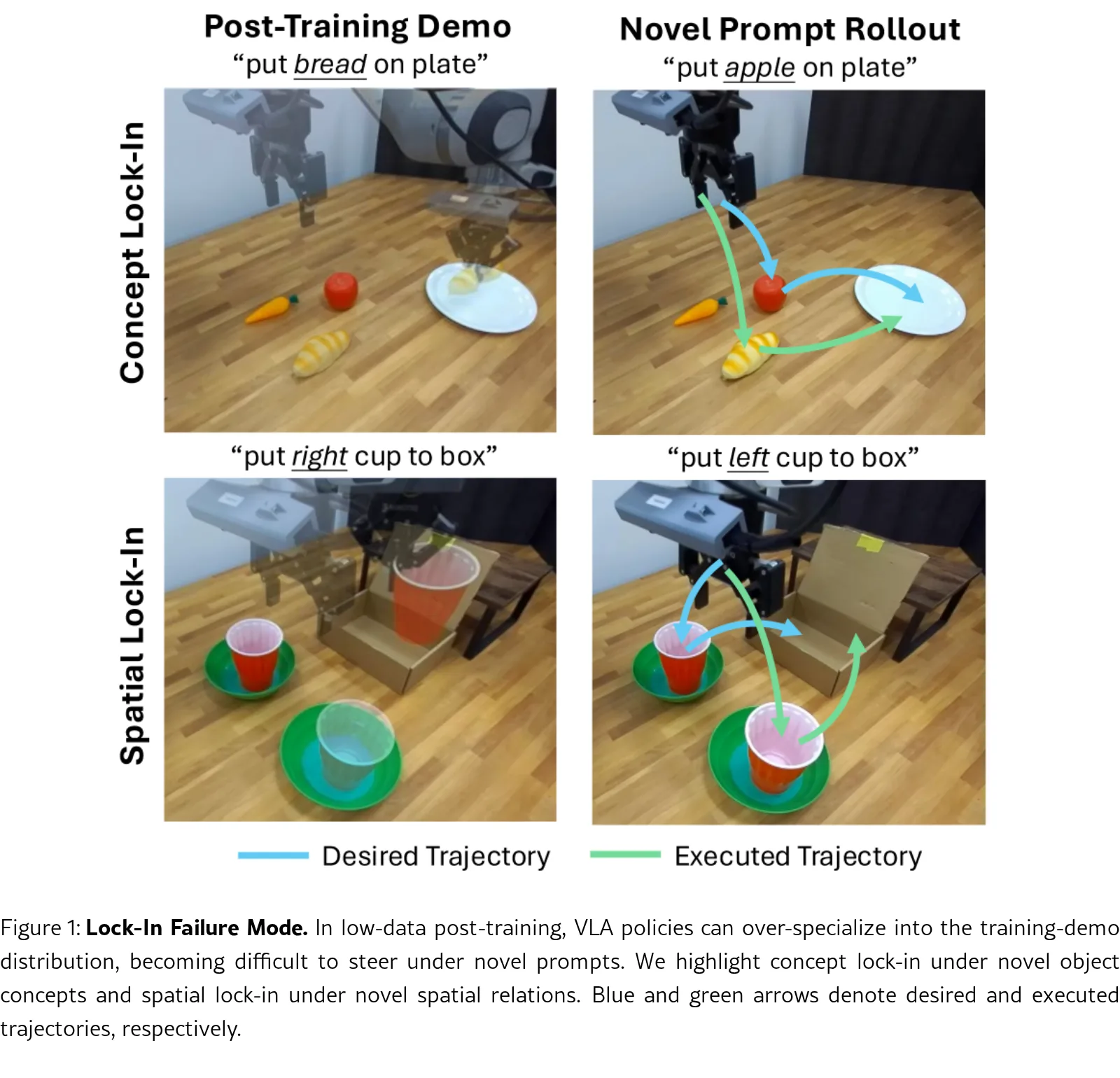
论文研究了在低数据量后训练(low-data post-training)场景下,视觉语言动作(VLA)策略容易出现的"锁入"(lock-in…
- 论文研究了在低数据量后训练(low-data post-training)场景下,视觉语言动作(VLA)策略容易出现的"锁入"(lock-in…
- 锁入表现为两种形式:概念锁入(对训练对象/属性的固守)和空间锁入(对训练空间目标的固守)
- 提出 DeLock 框架,通过视觉编码器权重漂移正则化保留预训练视觉接地能力,结合测试时对比提示引导(CPG)来引导动作生成
Card 01
研究单位
研究单位
- Stanford University(斯坦福大学)
Card 02
论文概述
论文概述
- 论文研究了在低数据量后训练(low-data post-training)场景下,视觉语言动作(VLA)策略容易出现的"锁入"(lock-in)失败模式,即策略过度专业化于训练数据,无法泛化到新的指令
- 锁入表现为两种形式:概念锁入(对训练对象/属性的固守)和空间锁入(对训练空间目标的固守)
- 提出 DeLock 框架,通过视觉编码器权重漂移正则化保留预训练视觉接地能力,结合测试时对比提示引导(CPG)来引导动作生成
Card 03
核心贡献
核心贡献
- 形式化定义了 VLA 在低数据后训练中的锁入失败模式,区分概念锁入和空间锁入两种类型
- 提出 DeLock 框架:视觉编码器 L2 正则化保留预训练接地能力,对比提示引导(CPG)在测试时引导策略
- 构建了新的评估基准,包含 4 个 LIBERO 仿真任务和 4 个 DROID 真实世界任务,系统性地评估锁入失败
- 实验表明 DeLock 在低数据条件下显著优于基线方法,性能达到甚至超越使用大量数据后训练的最先进策略
Card 04
方法描述
方法描述
- 视觉编码器权重漂移正则化:在标准 SFT 目标上增加 L2 惩罚项 λ\|\|θ_v - θ_v^pre\|\|²,防止视觉编码器偏离预训练参数,保留预训练的视觉接地能力
- 对比提示引导(CPG):在测试时利用正提示(novel prompt)和负提示(trained prompt)分别计算去噪向量场,通过 v_CPG = v_τ⁻ + w(v_τ⁺ - v_τ⁻) 引导动作生成,增强指令相关方向,抑制训练偏差
- 策略基于 Flow-Matching 条件去噪过程,通过 Euler 更新从噪声迭代到目标动作
Card 05
数据集与资源
数据集与资源
- 仿真数据集:4 个 LIBERO 任务,每个任务 100 条演示
- 真实世界数据集:4 个 DROID 任务,每个任务 80 条演示
- 基础模型:π0.5-BASE 预训练 VLA 模型(基于 PaliGemma 视觉语言骨干)
- 后训练设置:使用 LoRA 适配语言和动作模块,视觉编码器采用正则化训练
Card 06
评估与结果
评估与结果
- 评估基准:8 个任务,T1-T8,涵盖概念锁入、空间锁入和 OOD 位置泛化
- 主要结果:
- DeLock 在概念锁入任务上:Block-Stacking 19/20,Food-on-Plate 19/20
- 空间锁入任务上:Mug-on-Plate [S] 13/20,Cup-to-Box [S] 14/20
- 组合任务 Open-Labeled-Door [C+S]:13/20
- 对比基线:
- RETAIN 在所有新提示任务上几乎完全失败(0-6/20)
- π0.5-DROID 在空间推理任务上表现不佳(11/20),在组合任务上完全失败(0/20)
- 消融实验:移除视觉正则化或 CPG 均显著降低性能,证明两者的互补作用