一眼看懂
封面预览
论文提出了 MoSS (Modular Sensory Stream),这是一个用于将多种物理感官反馈(如触觉和力矩)集成到 Vision-L…
- 论文提出了 MoSS (Modular Sensory Stream),这是一个用于将多种物理感官反馈(如触觉和力矩)集成到 Vision-L…
- 旨在解决现有 VLA 模型仅依赖视觉观测在接触密集型精细操作任务中的局限性,以及现有单一模态扩展方法无法有效利用多重异构物理信号的问题。
- 通过引入解耦的模态流架构和两阶段训练策略,该框架能够可扩展地整合多种物理信号,实现互补的性能提升。
Card 01
研究单位
研究单位
- 论文作者为 Jimin Lee, Huiwon Jang, Myungkyu Koo, Jungwoo Park 和 Jinwoo Shin
- 基于第一作者及通讯作者的已知背景,研究单位主要归属于 KAIST (韩国科学技术院)
Card 02
论文概述
论文概述
- 论文提出了 MoSS (Modular Sensory Stream),这是一个用于将多种物理感官反馈(如触觉和力矩)集成到 Vision-Language-Action (VLA) 模型中的模块化框架。
- 旨在解决现有 VLA 模型仅依赖视觉观测在接触密集型精细操作任务中的局限性,以及现有单一模态扩展方法无法有效利用多重异构物理信号的问题。
- 通过引入解耦的模态流架构和两阶段训练策略,该框架能够可扩展地整合多种物理信号,实现互补的性能提升。
Card 03
核心贡献
核心贡献
- 提出了 MoSS 框架,通过解耦模态流和联合跨模态自注意力机制,无缝增强预训练 VLA 以利用物理感官信号进行动作预测。
- 设计了两阶段训练策略,第一阶段冻结预训练参数以预对齐物理信号流,第二阶段联合微调,保护预训练知识并稳定优化。
- 引入了未来物理信号预测的辅助任务,帮助模型内化物理交互动态,更有效地利用反馈生成动作。
- 构建了包含触觉和力矩反馈的真实世界接触密集型操作任务,验证了 MoSS 能够实现多重物理信号的累积性能增益。
Card 04
方法描述
方法描述
- 基于 Diffusion-based VLA 架构,在其 Action Expert 模块上附加并行的模块化感官流,用于处理触觉和力矩等物理输入。
- 创新点在于联合跨模态自注意力层,各流独立计算 Queries, Keys, Values 后拼接进行共享注意力计算,实现双向跨模态推理,同时通过流解耦防止梯度干扰。
- 采用流匹配作为主要训练目标,结合未来物理信号预测的辅助损失,分物理对齐和联合微调两个阶段进行训练。
Card 05
数据集与资源
数据集与资源
- 评估任务包括 Unstack Cup, PnP Egg, Board Erase, Plug Insertion 四个真实世界的接触密集型机器人操作任务。
- 硬件平台使用 Franka Research 3 机械臂、Robotiq 2F-85 夹爪、AnySkin 触觉传感器以及机械臂关节力矩传感器。
- 实验基于预训练模型 GR00T N1.5 和 $\pi_0$,在合并的任务数据集上进行微调。
- 训练配置包括 GR00T N1.5 训练 60K iterations(batch size 16),物理预测损失权重 $\lambda_{phy}$ 设为 0.1。
Card 06
评估与结果
评估与结果
- 在真实机器人平台上与 GR00T N1.5, $\pi_0$, Tactile-VLA, ForceVLA, TA-VLA 等基线方法进行对比。
- 主要评估指标为任务成功率 (%)。
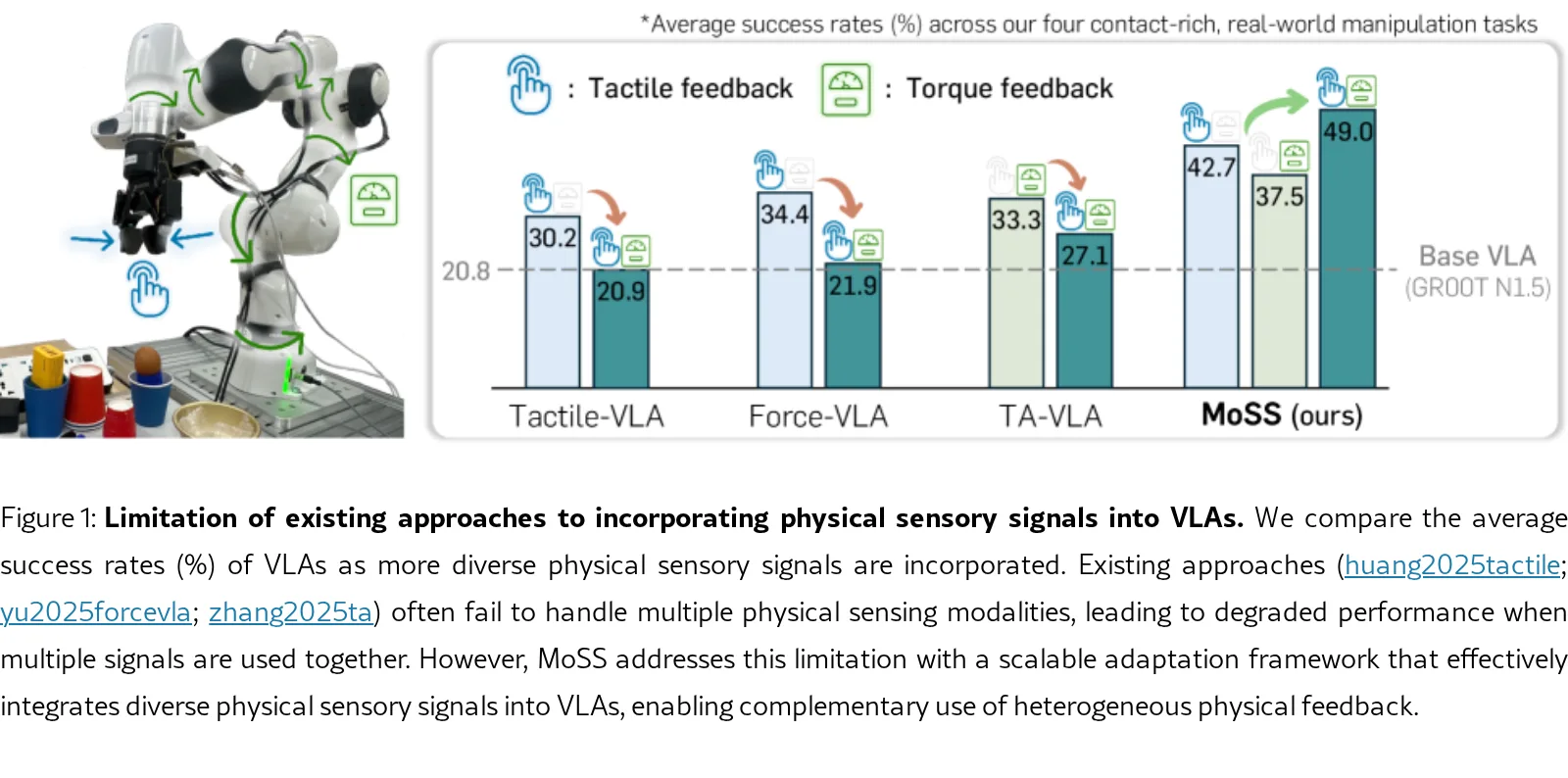
- 实验结果显示,MoSS 显著优于基线模型;例如在 GR00T N1.5 上集成触觉和力矩信号后,平均成功率从 20.8% 提升至 49.0%。
- 与现有方法在引入多模态时性能下降不同,MoSS 随着物理信号的增加表现出持续的性能累积增益。