一眼看懂
封面预览
论文提出一种名为 RL Token (RLT) 的轻量级方法,旨在利用预训练的 Vision-Language-Action (VLA) 模型…
- 论文提出一种名为 RL Token (RLT) 的轻量级方法,旨在利用预训练的 Vision-Language-Action (VLA) 模型…
- 核心思路是在 VLA 模型中引入一个紧凑的读出表示,即 RL Token,作为强化学习的状态接口,保留任务相关的预训练知识
- 论文要解决的问题是:如何在有限的机器人实践时间内(几小时),既保留 VLA 的泛化能力,又通过在线 RL 实现任务关键阶段在速度和成功率上的显…
Card 01
研究单位
研究单位
- 作者信息因匿名评审已隐去,具体研究机构未在原文中明确列出
Card 02
论文概述
论文概述
- 论文提出一种名为 RL Token (RLT) 的轻量级方法,旨在利用预训练的 Vision-Language-Action (VLA) 模型实现高效、快速的在线强化学习微调
- 核心思路是在 VLA 模型中引入一个紧凑的读出表示,即 RL Token,作为强化学习的状态接口,保留任务相关的预训练知识
- 论文要解决的问题是:如何在有限的机器人实践时间内(几小时),既保留 VLA 的泛化能力,又通过在线 RL 实现任务关键阶段在速度和成功率上的显著提升
Card 03
核心贡献
核心贡献
- 提出并实现了 RL Token,一个压缩的 VLA 内部表示,作为强化学习的紧凑状态,使其无需更新整个大模型即可高效学习
- 设计了在 RL Token 上训练轻量级 actor-critic 头的框架,actor 以 VLA 生成的参考动作块为条件并进行正则化,使在线 RL 变为对良好先验的局部优化而非无约束探索
- 在四个需要毫米级精度的真实机器人任务(螺丝安装、扎带紧固、以太网与充电器插入)上验证了方法的有效性,仅需几分钟至数小时的实践即可大幅提升性能
- 通过消融实验证明了方案中每个组件(RL Token、动作块预测、策略正则化、参考动作传入)的必要性
Card 04
方法描述
方法描述
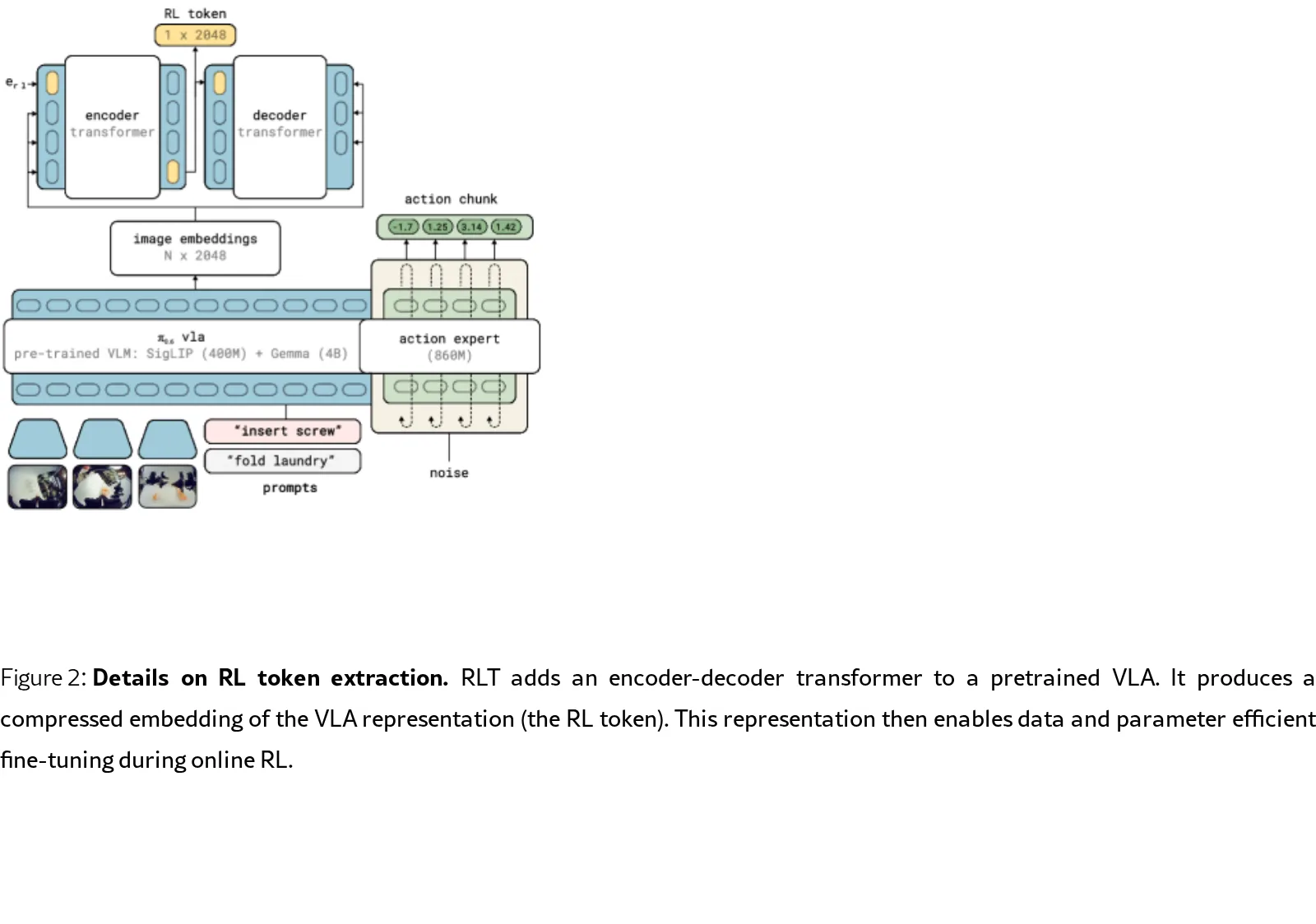
- 方法分为两个阶段:第一阶段,通过在预训练的 VLA 模型后附加一个小的 encoder-decoder transformer,训练其输出一个压缩嵌入作为 RL Token,训练目标为自回归重建原始的 VLA 嵌入
- 第二阶段,冻结 VLA 和 RL Token 模块,训练轻量级的 actor-critic 网络。Actor 以 RL Token 和 VLA 的参考动作块为输入,输出一个 Gaussian 分布以优化动作,并使用正则化损失使输出接近参考动作
- 引入“参考动作 dropout”技术,在训练中随机将部分参考动作置零,防止 Actor 简单复制而未学习改进
- 整体算法采用 off-policy actor-critic 架构(类似 TD3),利用包含 VLA 滚动、在线 RL 和人工干预的混合数据回放缓冲池
Card 05
数据集与资源
数据集与资源
- 使用四个真实世界机器人操作任务,每个任务需毫米级或亚毫米级精度:螺丝安装、扎带紧固、以太网插入、充电器插入
- 为每个任务收集了 1–10小时 的遥操作演示数据用于初始 VLA 微调和 RL Token 训练
- 基础 VLA 模型为预训练的 π0.6 模型
- RL policy 输入包括 RL Token(由2个腕部相机和1个基座相机图像生成)及本体感知状态(如关节位置或末端执行器姿态)
- 动作空间为14维,控制频率为 50 Hz,动作块长度为10步,对应140维输入
- 实验实际产生了大约 15分钟至5小时 的机器人数据,具体 GPU/TPU 资源未明确说明
Card 06
评估与结果
评估与结果
- 评估环境为真实机器人,任务执行时长为30–120秒,关键阶段时长为5–20秒
- 基线方法包括 HIL-SERL、Probe-Learn-Distill (PLD)、DSRL、DAgger
- 主要评估指标为 成功率(由人工提供二值奖励)和 吞吐量(每10分钟内成功完成的任务数量)
- 关键结果:RLT 在所有任务上均提升了性能,在关键阶段将速度提升最高达 3×,在螺丝安装任务上将成功率从20%提升至65%
- 在以太网插入任务上,最终 RL 策略的速度超越了专家遥操作演示,并能发现比人类演示更高效的策略
- 消融实验显示,移除 RL Token(用 ResNet 替代)、去除动作块(C=1)、移除 BC 正则化器(β=0)或移除参考动作传入,都会导致吞吐量显著下降或学习不稳定