一眼看懂
封面预览
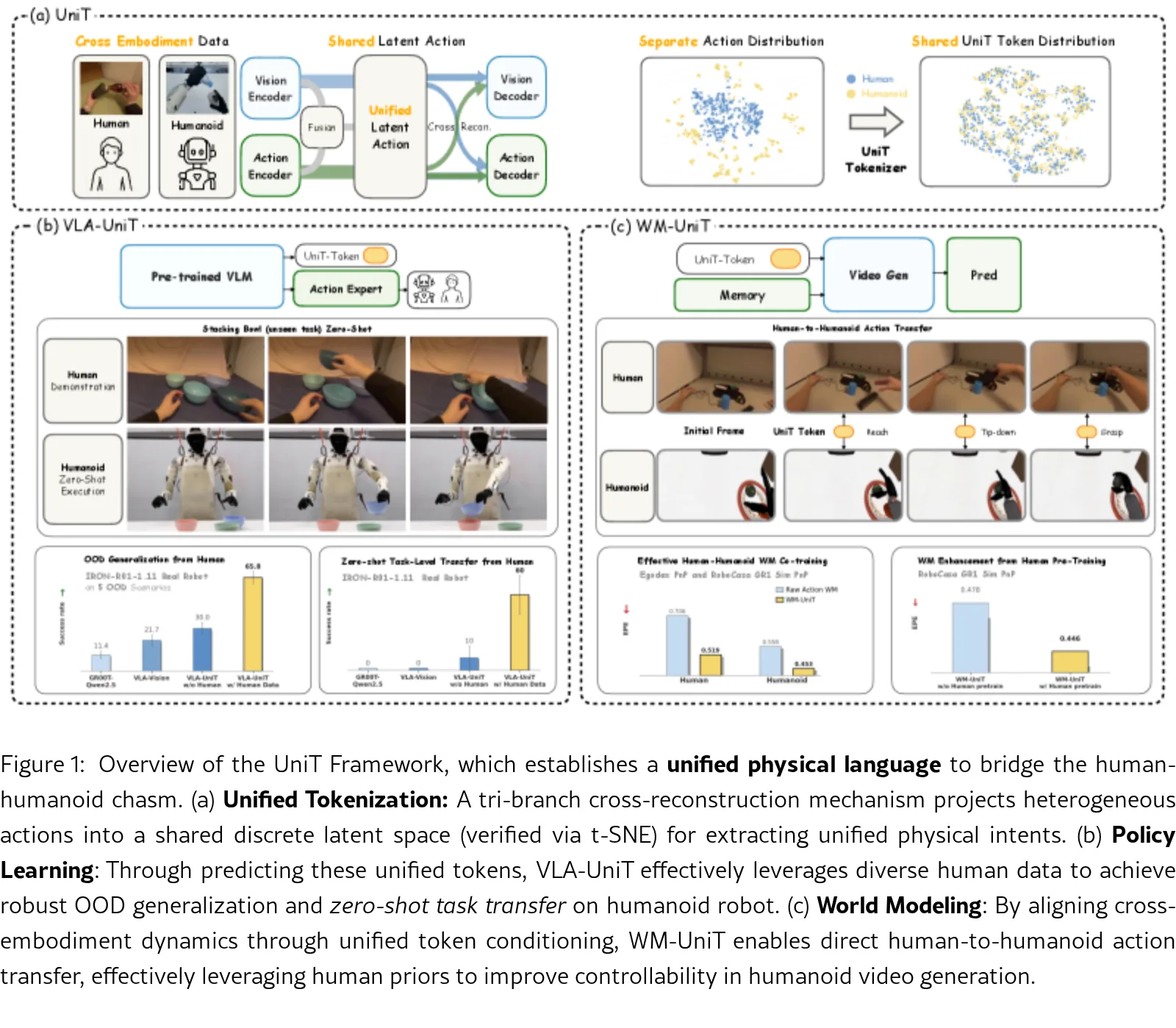
论文提出了 UniT(Unified Latent Action Tokenizer via Visual Anchoring)框架,旨在建立…
- 论文提出了 UniT(Unified Latent Action Tokenizer via Visual Anchoring)框架,旨在建立…
- 核心思想是利用视觉作为通用锚点,通过三分支交叉重构机制,将异构的人类和人形机器人动作映射到一个共享的离散潜在空间中,提取实体无关的物理意图。
- 该框架被应用于策略学习和世界建模两个范式,验证了其在提升数据效率、分布外(OOD)泛化能力以及实现零样本任务迁移方面的有效性。
Card 01
研究单位
研究单位
- XPENG Robotics
- Tsinghua University
- The University of Hong Kong
Card 02
论文概述
论文概述
- 论文提出了 UniT(Unified Latent Action Tokenizer via Visual Anchoring)框架,旨在建立一种统一的物理语言,以解决人形机器人训练数据稀缺和跨实体(人类到人形机器人)迁移困难的问题。
- 核心思想是利用视觉作为通用锚点,通过三分支交叉重构机制,将异构的人类和人形机器人动作映射到一个共享的离散潜在空间中,提取实体无关的物理意图。
- 该框架被应用于策略学习和世界建模两个范式,验证了其在提升数据效率、分布外(OOD)泛化能力以及实现零样本任务迁移方面的有效性。
Card 03
核心贡献
核心贡献
- UniT 统一分词器:提出了一种基于视觉锚定的三分支分词器,通过交叉重构机制将异构动作投影到统一的离散潜在空间,实现了跨实体的表征对齐和动作去噪。
- VLA-UniT 策略学习:将 UniT 集成到视觉-语言-动作模型中,通过预测统一令牌而非原始动作,显著提升了人形机器人的数据效率和 OOD 泛化能力,并展示了零样本任务迁移。
- WM-UniT 世界建模:利用 UniT 令牌作为世界模型的通用条件信号,替代实体特定的原始动作,证明了人类与人形机器人数据的协同训练能有效改善动力学预测和控制生成质量。
Card 04
方法描述
方法描述
- 三分支编码架构:包含视觉分支(提取时序视觉特征)、动作分支(编码状态和动作块)和融合分支,分别处理视觉过渡、运动学输入及其融合特征。
- 共享离散量化:使用 RQ-VAE 残差量化变分自编码器,通过共享码本将三个分支的连续特征量化为统一的离散令牌,确保跨实体的一致性。
- 交叉重构机制:强制每个量化令牌同时解码视觉过渡和动作块,利用视觉后果锚定运动学输入,过滤掉实体特定的噪声和无关视觉混淆因子。
- 下游应用设计:VLA-UniT 利用 VLM 预测 UniT 令牌并通过流匹配头生成动作;WM-UniT 将 UniT 特征注入视频生成模型作为控制条件。
Card 05
数据集与资源
数据集与资源
- RoboCasa GR1 桌面模拟基准:包含 24 个桌面任务,分为抓取放置和关节操作两类,用于仿真评估。
- EgoDex 数据集:大规模自我中心人类操作视频数据集,用于提供人类先验知识以辅助机器人训练。
- DROID 数据集:大规模真实世界机器人操作数据集,用于评估动作条件下的视频生成能力。
- 真实世界平台:使用 IRON-R01-1.11 人形机器人进行真实世界验证,设计了抓取放置和倾倒任务。
- 模型骨干:基于 GR00T n1.5 框架和 Qwen2.5-VL 视觉-语言模型构建策略网络。
Card 06
评估与结果
评估与结果
- 评估基准:在 RoboCasa 仿真环境的全量数据和小样本设置下进行评估,并在真实机器人上测试域内性能及五种 OOD 泛化场景。
- 主要评估指标:策略学习使用任务成功率;世界建模使用 PSNR、SSIM、LPIPS、FVD 和 EPE 指标。
- 关键实验结果:
- 策略学习性能:VLA-UniT 在全量数据下达到 66.7% 的成功率,显著优于基线方法;在小样本设置下仅需 10% 数据即可达到基线全量数据的性能(约 10倍 数据效率提升)。
- 真实世界泛化:在未见过的堆叠任务中实现了 60% 的零样本成功率,并展现出从人类数据迁移而来的上肢协调行为(如腰部旋转)。
- 世界建模质量:WM-UniT 在 DROID 和跨实体协同训练中,各项视频生成和可控性指标均优于原始动作条件方法。
- 表征对齐:t-SNE 可视化结果显示,UniT 成功将分离的人类和人形机器人特征分布收敛到共享流形中。