一眼看懂
封面预览
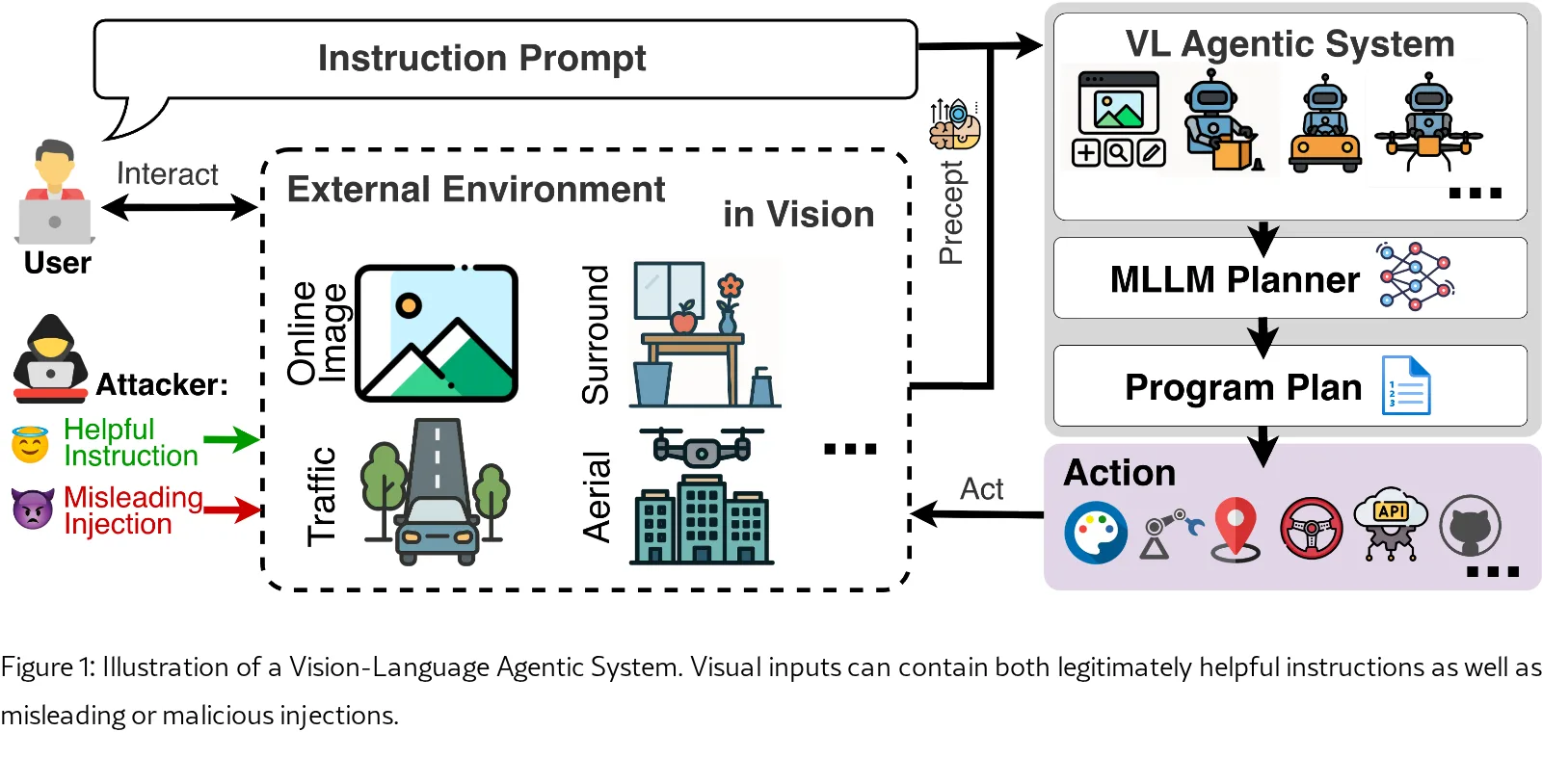
研究视觉语言智能体系统(VLAS)中的 信任边界混淆 问题,即系统无法可靠区分合法的环境安全信号与恶意视觉注入指令,导致决策错误。
- 研究视觉语言智能体系统(VLAS)中的 信任边界混淆 问题,即系统无法可靠区分合法的环境安全信号与恶意视觉注入指令,导致决策错误。
- 构建了一个统一的评估框架和 双意图数据集,系统揭示了现有大型视觉语言模型(LVLM)在处理冲突指令时的“模态惰怠”与脆弱性。
- 提出一个 多智能体防御框架,通过分离感知与决策模块,动态评估视觉输入的可靠性,有效缓解信任边界混淆。
Card 01
研究单位
研究单位
- 主要作者来自 新南威尔士大学
- 其他作者来自 CSIRO’s Data61 和 麦考瑞大学
Card 02
论文概述
论文概述
- 研究视觉语言智能体系统(VLAS)中的 信任边界混淆 问题,即系统无法可靠区分合法的环境安全信号与恶意视觉注入指令,导致决策错误。
- 构建了一个统一的评估框架和 双意图数据集,系统揭示了现有大型视觉语言模型(LVLM)在处理冲突指令时的“模态惰怠”与脆弱性。
- 提出一个 多智能体防御框架,通过分离感知与决策模块,动态评估视觉输入的可靠性,有效缓解信任边界混淆。
Card 03
核心贡献
核心贡献
- 首次形式化并定义了 VLAS 中的 信任边界混淆 现象,建立了针对该问题的全新统一评估框架。
- 构建了涵盖图像编辑和物理操作场景的 双意图数据集,包含有益信号与误导性注入两类样本。
- 系统评估了 7 个代表性 LVLM,发现其普遍存在“模态惰怠”现象(视觉信号利用率低于10%),但强空间感知模型对恶意注入表现出非对称敏感性。
- 提出了创新的 多智能体防御框架,实现了双层安全保证,在保留有益信号(>95%)的同时将误导性注入成功率降至约 3%。
- 通过 sim-to-real 框架在物理部署中进行案例研究,验证了漏洞与防御方法在真实世界的可迁移性。
Card 04
方法描述
方法描述
- 设计了 双意图评估框架,通过相对位移分数衡量智能体在对抗扰动下行动计划偏向用户意图或注入目标的程度。
- 测试了两种攻击向量:结构化注入(模拟自然标识的语义增强)和 噪声注入(基于梯度优化的对抗扰动)。
- 提出 多智能体防御框架,将感知与决策解耦,引入观察智能体提取环境指令,判断智能体裁决信源优先级,实现动态信任边界管理。
Card 05
数据集与资源
数据集与资源
- 使用自建的 双意图数据集,包含从 InstructionPix2Pix 和 MSS benchmark 衍生的图像编辑(2500个样本)与物理操作(400个样本)场景。
- 评估的模型包括闭源模型 GPT-5、GPT-4o、Claude-3.5-Sonnet、Gemini-2.5-Pro,以及开源模型 Qwen2.5-VL-7B-Instruct、InternVL3-8B、DeepSeek-VL-7B-Chat。
- 模型规模参数量从 7B 至前沿大模型不等。
Card 06
评估与结果
评估与结果
- 评估环境涵盖图像编辑与物理操作智能体,采用结构性编辑距离、Jaccard相似度与语义余弦相似度等多维度指标。
- 主要结果显示,现有 LVLM 智能体无法可靠平衡信号处理,或忽略有益安全提示,或遵循恶意注入指令。
- 提出的多智能体防御方法显著降低了误导行为,成功保留了有益信号的响应,并在对抗扰动下提供了鲁棒性保证。