一眼看懂
封面预览
研究目标:解决基于扩散策略的强化学习方法在测试时扩展(test-time scaling)时计算成本过高的问题- 核心问题:当前高性能RL算法…
- 研究目标:解决基于扩散策略的强化学习方法在测试时扩展(test-time scaling)时计算成本过高的问题- 核心问题:当前高性能RL算法…
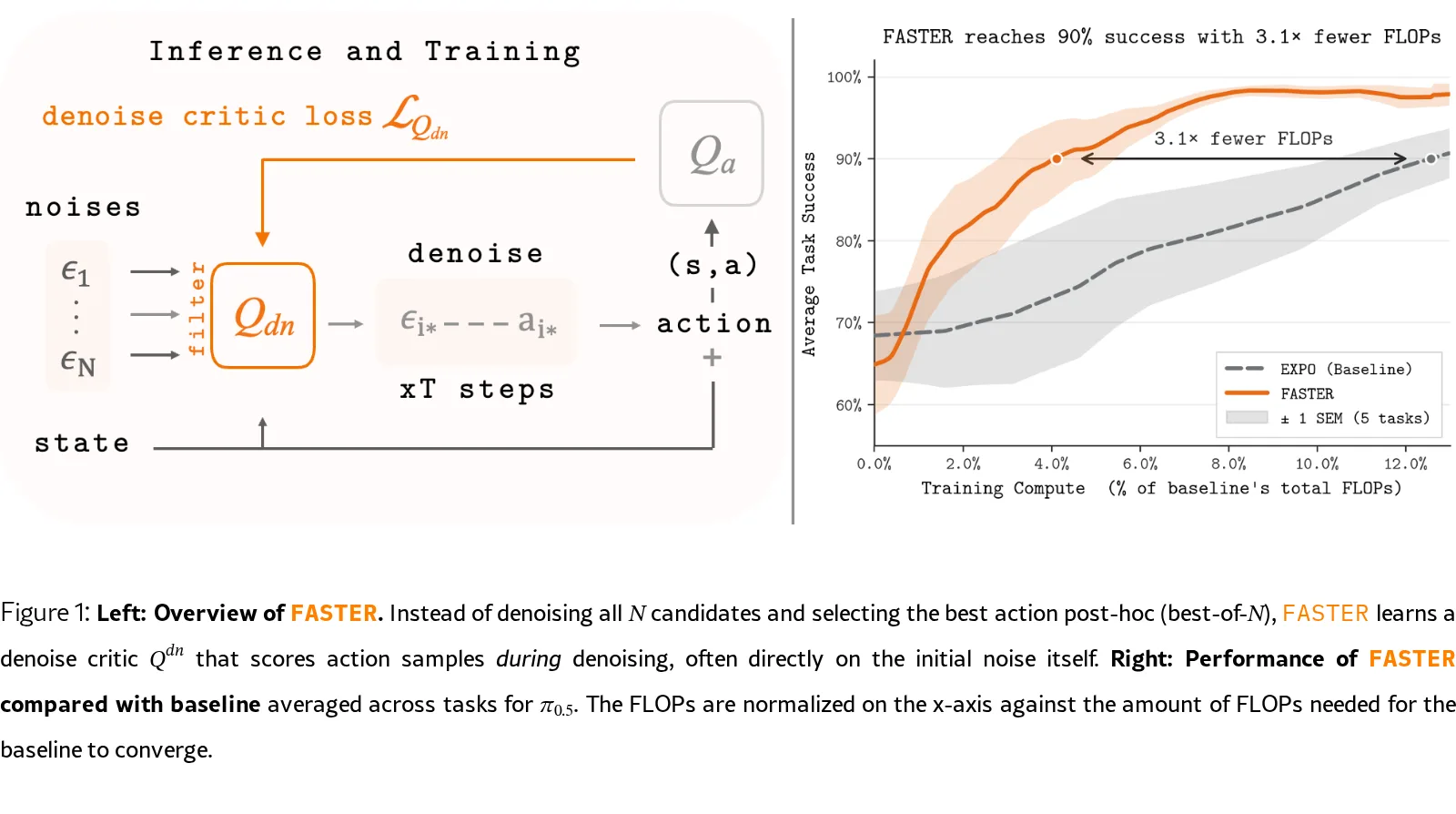
- 解决方案:提出FASTER方法,通过在去噪过程早期过滤动作候选,而非对所有候选完全去噪后再选择,从而获得采样扩展的性能增益而无需承担其计算成本
- 关键洞察:样本方差在去噪过程早期(尤其是初始噪声)就已确定,可以在完全去噪前预测动作质量
Card 01
研究单位
研究单位
- Stanford University(斯坦福大学)
- Perry Dong、Alexander Swerdlow、Dorsa Sadigh、Chelsea Finn
Card 02
论文概述
论文概述
- 研究目标:解决基于扩散策略的强化学习方法在测试时扩展(test-time scaling)时计算成本过高的问题- 核心问题:当前高性能RL算法需要对多个动作候选进行采样和去噪选择(如best-of-N),这在计算上非常昂贵,特别是对于大规模VLA模型
- 解决方案:提出FASTER方法,通过在去噪过程早期过滤动作候选,而非对所有候选完全去噪后再选择,从而获得采样扩展的性能增益而无需承担其计算成本
- 关键洞察:样本方差在去噪过程早期(尤其是初始噪声)就已确定,可以在完全去噪前预测动作质量
Card 03
核心贡献
核心贡献
- 提出将多个动作候选的去噪和选择过程建模为马尔可夫决策过程(MDP),学习一个过滤策略在去噪完成前逐步过滤候选动作
- 学习一个噪声级评论家(denoise critic)Q^{dn}(s,ε),直接从初始噪声预测下游返回值,避免对所有N个候选进行完整去噪
- 实现上简化为单步决策——仅在初始噪声级别过滤,将计算复杂度从O(TN)降低到O(T)(T为去噪步数,N为候选数)
- 方法是轻量级、模块化的,可以插入现有的生成式RL算法(如EXPO、IDQL)
- 在大规模3.3B参数VLA模型上验证,显著降低训练和推理计算需求
Card 04
方法描述
方法描述
- 过滤MDP建模:状态包括环境状态s、去噪时间步t、存活候选集C_t、部分去噪的中间动作;动作是保留或丢弃每个候选
- 噪声级评论家学习:使用TD学习目标,训练Q^{dn}预测动作的最终Q值;奖励使用动作级评论家Q^{a}的输出
- 实际实现:简化MDP为单步决策,仅在t=T(初始噪声)时过滤,避免多步过滤的计算开销
- 推理过程:采样N个噪声候选→用Q^{dn}评分→选择最高分→仅对选中候选去噪→执行动作
- 两种变体:FASTER-EXPO(基于EXPO的编辑策略)、FASTER-IDQL(直接执行去噪动作)
Card 05
数据集与资源
数据集与资源
- 数据集/任务:
- Robomimic:Lift、Can、Square、Tool Hang四个任务
- LIBERO:libero_90任务的子集
- 预训练VLA模型:pi05_libero(3.3B参数)来自OpenPI
- 模型规模:
- 扩散策略:标准 actor-critic 架构
- VLA实验:critic 20M参数 vs actor 3.3B参数
- 训练资源:
- 在线RL设置与批量在线(batch-online)RL设置
- Delta系统(NCSA)进行实验
Card 06
评估与结果
评估与结果
- 评估环境:9个挑战性操作任务(Robomimic + LIBERO)
- 基线方法:EXPO、IDQL、RLPD、QSM、DSRL、QAM、FQL
- 主要结果:
- FASTER-EXPO在在线和批量在线设置中均达到最佳整体性能
- 匹配best-of-N采样的性能,同时大幅降低计算成本
- 计算效率:
- 推理时间:566ms → 335ms(1.7x加速)
- 训练更新:11.6s → 2.5s(4.5x加速)
- VLA推理FLOPs:3.75×10^13 → 4.70×10^12(8x减少)
- 消融实验:
- critic规模:Q^{dn}可以比Q^{a}小很多而不影响性能
- 过滤时间步:在不同去噪步骤过滤性能一致,初始噪声过滤效果最佳
- 完整MDP vs单步过滤:性能相当,单步简化是有效的近似