一眼看懂
封面预览
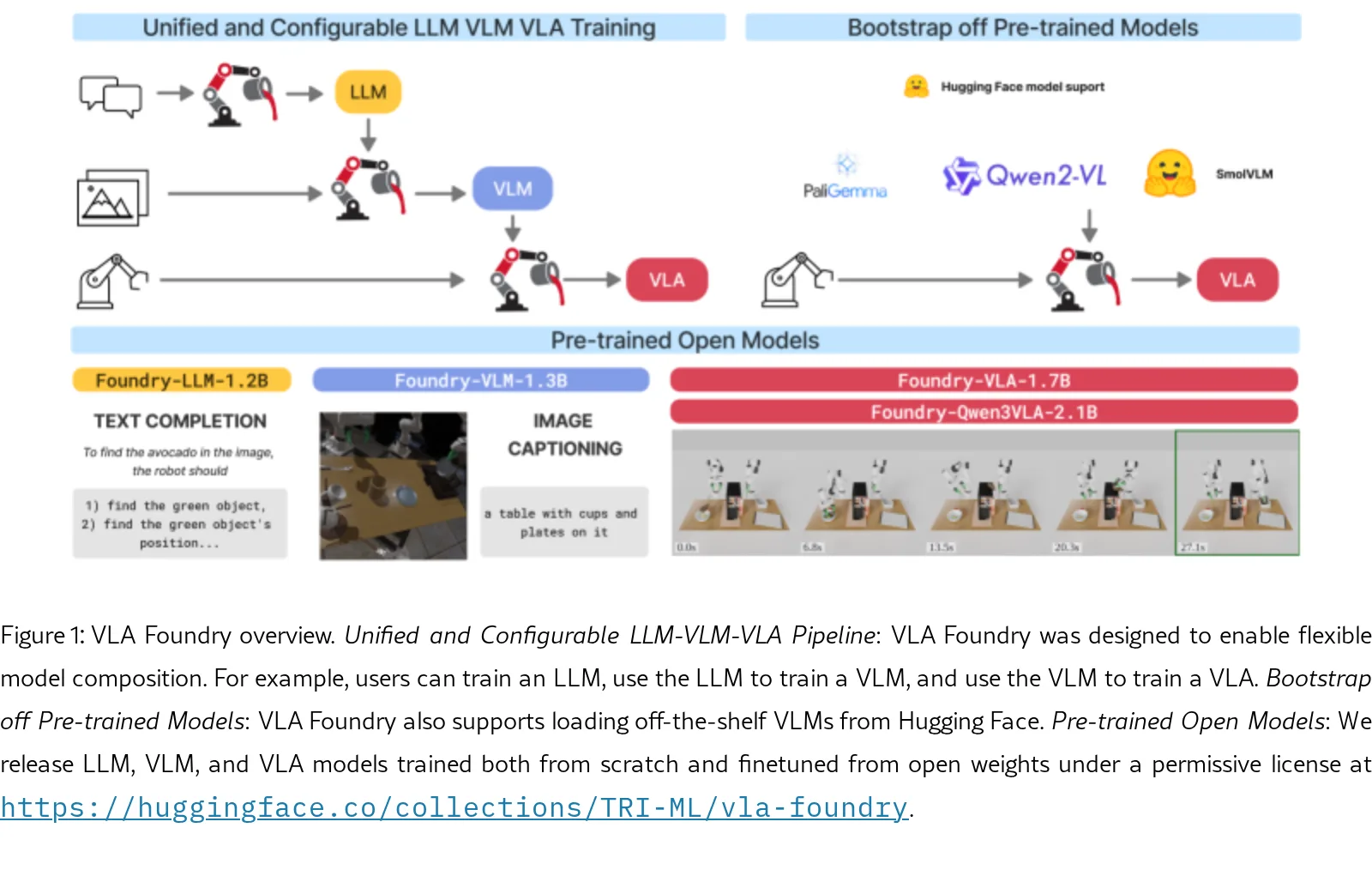
论文提出了 VLA Foundry,一个开源的统一框架,旨在将大语言模型(LLM)、视觉语言模型(VLM)和视觉语言动作模型(VLA)的训练整…
- 论文提出了 VLA Foundry,一个开源的统一框架,旨在将大语言模型(LLM)、视觉语言模型(VLM)和视觉语言动作模型(VLA)的训练整…
- 该框架为用户提供端到端的控制能力,覆盖从语言预训练到动作专家微调的整个训练管道。
- 论文解决了当前开源VLA训练框架主要专注于动作训练阶段、而上游预训练流程往往被割裂或不兼容的问题,旨在为研究人员提供一个可探索数据、骨干网络和…
Card 01
研究单位
研究单位
- Toyota Research Institute
Card 02
论文概述
论文概述
- 论文提出了 VLA Foundry,一个开源的统一框架,旨在将大语言模型(LLM)、视觉语言模型(VLM)和视觉语言动作模型(VLA)的训练整合在同一个代码库中。
- 该框架为用户提供端到端的控制能力,覆盖从语言预训练到动作专家微调的整个训练管道。
- 论文解决了当前开源VLA训练框架主要专注于动作训练阶段、而上游预训练流程往往被割裂或不兼容的问题,旨在为研究人员提供一个可探索数据、骨干网络和训练配方之间交互关系的完整、可控的实验系统。
Card 03
核心贡献
核心贡献
- 发布了一个统一、开源的训练框架 VLA Foundry,共享数据加载、训练循环和配置系统,支持LLM、VLM、VLA全流程训练,并可无缝接入Hugging Face的预训练模型骨干。
- 基于该框架训练并开源了两类模型:完全从头训练的 Foundry-VLA-1.7B,以及基于预训练 Qwen3-VL 骨干构建的 Foundry-Qwen3VLA-2.1B-MT,并发布了中间检查点供社区使用。
- 为开源模拟器 LBM Eval 和分析工具 STEP 提供了易用性改进,并内置了一个统计严谨的评估仪表盘,便于社区进行模型对比和决策。
- 通过实验证明,框架能够有效支持从头训练和预训练骨干微调两条路径,且更强的VLM骨干能显著提升VLA策略的性能。
Card 04
方法描述
方法描述
- 框架采用基于YAML的模块化配置系统(Draccus),通过注册表机制实现模型和数据管道的灵活组装与替换,保持训练循环的模型无关性。
- 训练栈支持FSDP2分布式训练、混合精度、梯度累积和检查点同步,专为中等规模算力设计,并在多达128个GPU上进行了吞吐量基准测试。
- 机器人数据处理模块包含专门的 RoboticsNormalizer,支持全局和分时步的归一化方案,使用t-digest进行百分位估计与合并;动作表示支持绝对和相对坐标,并可配置动作块的时间窗口。
- 模型架构采用流匹配作为动作头,VLA输入序列包含图像、任务描述文本和一个新增的观察token,其隐藏状态用于条件化一个流Transformer以去噪动作序列。
Card 05
数据集与资源
数据集与资源
- LLM训练:使用 DCLM 数据集(500M样本,约1T tokens)。
- VLM训练:使用 DataCompDR-1B 数据集(200M样本)。
- VLA训练:使用内部 LBM 项目提供的混合数据,包含42个模拟任务和361个真实世界任务的遥操作演示数据。
- 模型规模:从头训练的模型总参数量约1.7B(LLM骨干1.2B,Vit编码器86M,动作头325M);基于Qwen3-VL的模型总参数量约2.1B。
- 训练资源:使用AWS SageMaker上的P5节点(每个节点8个 Nvidia H100 GPU)进行多节点多GPU分布式训练。
Card 06
评估与结果
评估与结果
- 评估环境:在开源模拟器 LBM Eval 上进行闭环策略评估,包含16个已见模拟任务和3个未见任务。
- 主要评估指标:任务成功率,并通过 STEP 工具进行贝叶斯估计和显著性分析,提供小提琴图和紧凑字母显示(CLD)以进行严谨的统计比较。
- 关键实验结果:
- 在标准评估设置下,完全从头训练的 Foundry-VLA-1.7B 模型性能与先前的闭源 LBM-MT 模型相当。
- 基于 Qwen3-VL 骨干的 Foundry-Qwen3VLA-2.1B-MT 模型性能显著优于其他模型,平均领先超过20个百分点。
- 多任务训练与微调实验表明,更强的VLM骨干能带来更好的策略泛化与性能提升,验证了框架在探索骨干网络与策略性能关联方面的有效性。