一眼看懂
封面预览
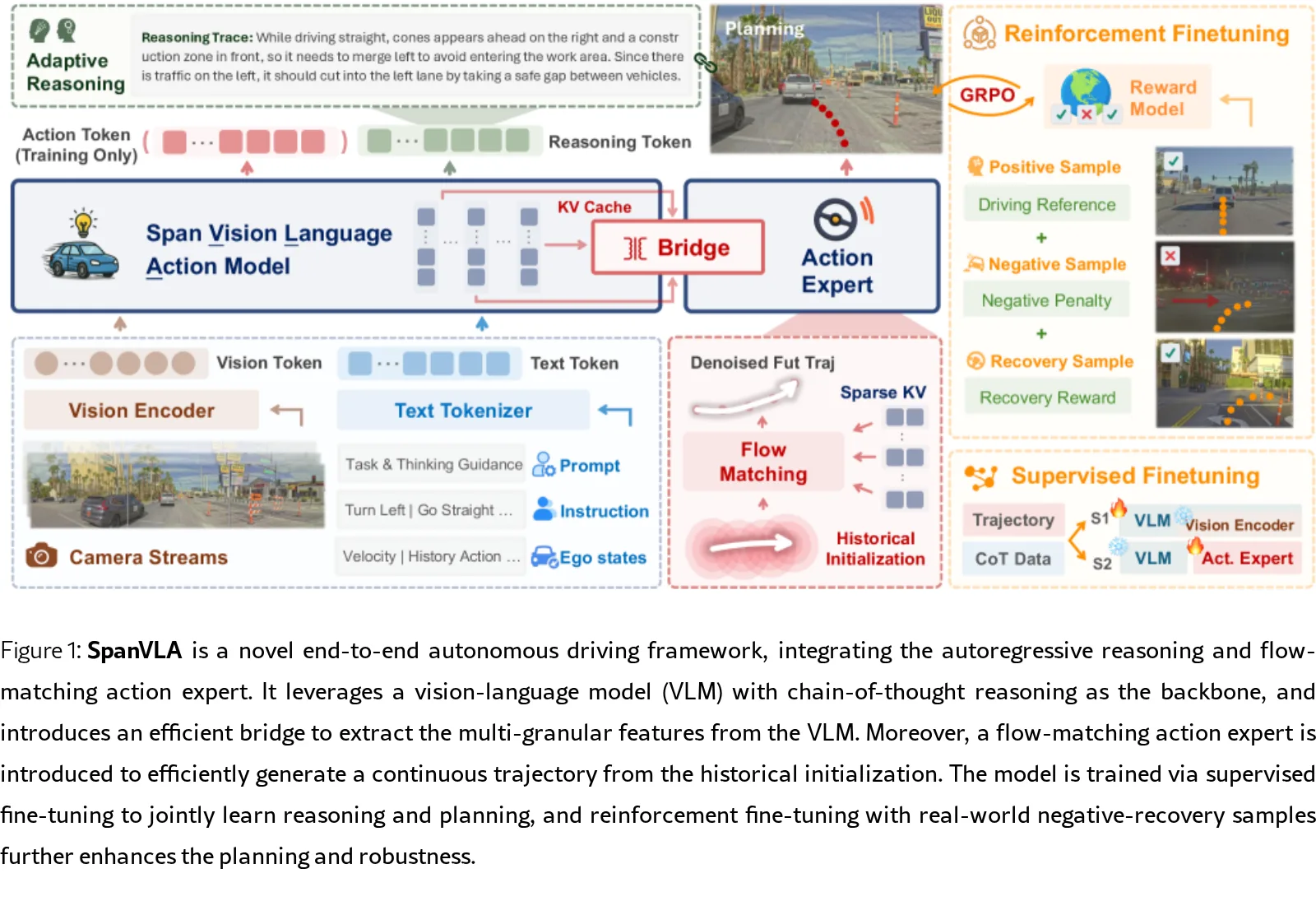
提出 SpanVLA,一种新型端到端自动驾驶框架,将视觉语言模型的推理能力与流匹配(flow-matching)动作专家相结合
- 提出 SpanVLA,一种新型端到端自动驾驶框架,将视觉语言模型的推理能力与流匹配(flow-matching)动作专家相结合
- 针对现有 VLA 模型的两大挑战:1) 自回归解码导致的高延迟动作生成;2) 仅从正样本学习导致鲁棒性有限
- 引入基于 GRPO 的强化微调方法,利用真实世界的负样本恢复数据(negative-recovery samples)提升模型性能和鲁棒性
Card 01
研究单位
研究单位
- University of California, Los Angeles, USA
- Motional, USA
- Northeastern University, USA
Card 02
论文概述
论文概述
- 提出 SpanVLA,一种新型端到端自动驾驶框架,将视觉语言模型的推理能力与流匹配(flow-matching)动作专家相结合
- 针对现有 VLA 模型的两大挑战:1) 自回归解码导致的高延迟动作生成;2) 仅从正样本学习导致鲁棒性有限
- 引入基于 GRPO 的强化微调方法,利用真实世界的负样本恢复数据(negative-recovery samples)提升模型性能和鲁棒性
- 在 NAVSIM v1 和 v2 基准测试上实现了最先进性能
Card 03
核心贡献
核心贡献
- 提出 SpanVLA 框架,集成了 VLM 主干与高效动作桥接模块,利用流匹配策略基于历史初始化高效规划未来轨迹
- 引入基于 GRPO 的后训练方法,使模型不仅从正样本学习,还能学习如何避免典型负样本行为和学习恢复行为
- 构建 mReasoning 数据集,包含 30K 推理样本和 3K+3K 负样本恢复样本,聚焦复杂推理场景
- 实现了 NAVSIM v1 和 v2 基准测试上的最先进性能,同时显著降低推理时间
Card 04
方法描述
方法描述
- VLM 主干:使用 Qwen2.5VL-3B 作为主干,处理多帧多视角图像输入和语言指令,进行自回归解码生成推理结果和动作标记
- 高效动作桥接:从 VLM 的稀疏层提取多粒度特征,结合历史轨迹嵌入,通过流匹配生成连续轨迹,避免纯噪声初始化
- 监督微调 (SFT):联合训练推理和规划能力,使用 LM 损失和动作损失
- 强化微调 (RFT):采用 GRPO 算法,结合三种奖励——驾驶奖励、负样本惩罚、恢复奖励和 CoT 惩罚
Card 05
数据集与资源
数据集与资源
- 训练数据:nuPlan (Open-Scene) 数据集的 navtrain split(100K 场景)+ mReasoning 数据集(30K 场景)
- mReasoning 数据集:包含 30K 推理样本、3K 负样本、3K 恢复样本,涵盖换道、VRU、施工区、停车标志等场景
- VLM 主干:Qwen2.5VL-3B
- 训练硬件:8 张 NVIDIA A100 GPU
- RFT 配置:学习率 3×10⁻⁵,组样本大小 64,使用 LoRA 进行高效微调
Card 06
评估与结果
评估与结果
- 评估基准:NAVSIM v1 (navtest)、NAVSIM v2 (navtest 和 navhard)
- 主要评估指标:PDMS (Predictive Driver Model Score)、NC (No Collision)、DAC (Drivable Area Compliance)、EP (Ego Progress)、TTC (Time-To-Collision)、Comfort
- NAVSIM v1 结果:
- SpanVLA (Post-RFT): PDMS 90.3,NC 99.1%,DAC 97.1%,EP 86.3%,Comfort 100.0%
- 超越所有 SOTA 方法,在 PDMS 和 NC 指标上达到最高分
- NAVSIM v2 结果:在 navtest 和 navhard 基准上均展现 SOTA VLA 驾驶性能
- 消融实验:验证了历史初始化和稀疏层对动作桥接的效果,验证了负样本惩罚和恢复奖励对 RFT 的提升效果