一眼看懂
封面预览
论文提出 OneVL(One-step latent reasoning and planning with Vision-Language…
- 论文提出 OneVL(One-step latent reasoning and planning with Vision-Language…
- 核心论点是:现有潜在CoT方法因仅压缩语言符号抽象而非因果动态,导致性能不及显式CoT。OneVL通过引入视觉世界模型辅助解码器,监督潜在to…
- 论文目标是:实现 单步潜在推理(推理速度快)、视觉语言解释(推理可解释)与轨迹规划的统一,在保证低延迟的同时超越显式CoT性能。
Card 01
研究单位
研究单位
- Xiaomi Embodied Intelligence Team(小米具身智能团队)
Card 02
论文概述
论文概述
- 论文提出 OneVL(One-step latent reasoning and planning with Vision-Language explanations)框架,旨在解决自动驾驶中 VLA模型使用显式链式思维(CoT)推理时推理延迟过高 的关键问题。
- 核心论点是:现有潜在CoT方法因仅压缩语言符号抽象而非因果动态,导致性能不及显式CoT。OneVL通过引入视觉世界模型辅助解码器,监督潜在token编码未来场景动态,弥补此缺陷。
- 论文目标是:实现 单步潜在推理(推理速度快)、视觉语言解释(推理可解释)与轨迹规划的统一,在保证低延迟的同时超越显式CoT性能。
Card 03
核心贡献
核心贡献
- 提出 OneVL框架,采用双模态辅助解码器(语言解码器+视觉世界模型解码器)联合监督潜在token,并设计三阶段训练流程确保稳定优化。
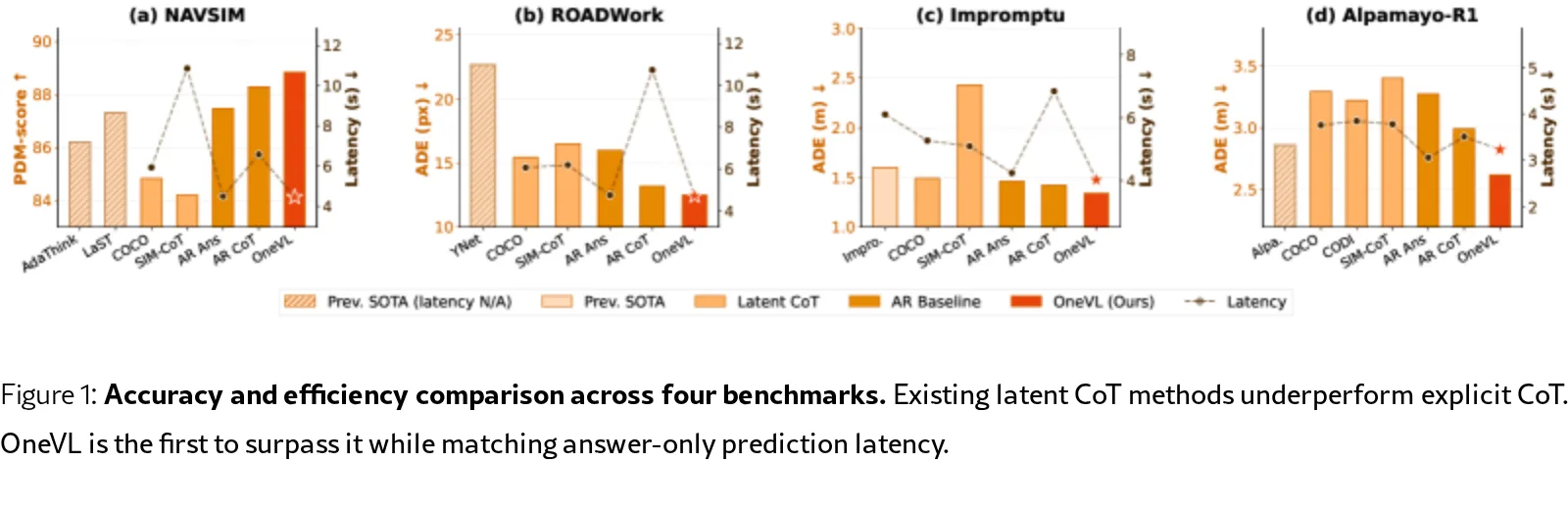
- 在四个基准(NAVSIM、ROADWork、Impromptu、APR1)上实现最优性能,成为首个超越显式CoT的潜在CoT方法,验证“紧致压缩驱动泛化”的理论假设。
- 设计 Prefill推理机制,在推理时丢弃辅助解码器,将潜在token一次性并行填充,实现与纯答案预测相当的延迟(NAVSIM上比显式CoT快1.5×)。
- 提供可解释输出:语言解码器恢复CoT文本,视觉解码器生成未来帧token,实现双模态解释。
Card 04
方法描述
方法描述
- 核心架构:基于 Qwen3-VL-4B-Instruct,引入两类潜在token:语言潜在token(编码语言推理)和视觉潜在token(编码未来场景动态)。
- 关键创新:引入 视觉辅助解码器 作为世界模型辅助,预测未来0.5s和1.0s的视觉token,迫使潜在空间内化驾驶场景的因果动态。
- 训练流程:包含预备自监督预训练和三阶段训练——Stage 0主模型预热,Stage 1辅助解码器预热(主模型冻结),Stage 2联合端到端微调。
- 推理机制:采用 Prefill推理,潜在token在prefill阶段一次性并行填充,随后自回归生成轨迹,匹配纯答案预测延迟。
Card 05
数据集与资源
数据集与资源
- 使用四个基准:NAVSIM(nuPlan衍生)、ROADWork(道路施工区域)、Impromptu(极端场景)、APR1(因果链标注)。
- 模型规模:基于 Qwen3-VL-4B-Instruct,参数量 4B。
- 训练资源:具体资源未在正文中明确提及,但附录提供了详细训练配置。
Card 06
评估与结果
评估与结果
- 评估基准与指标:NAVSIM使用PDM分数(复合指标);ROADWork、Impromptu、APR1使用ADE、FDE和L2误差。
- 主要结果:OneVL在所有基准上均取得最优性能。例如,在NAVSIM上PDM分数最高;推理延迟与纯答案预测相当,比显式CoT快1.5×-2.3×。
- 关键发现:消融研究证实视觉和语言解码器均有贡献,三阶段训练不可或缺;先前潜在CoT方法因缺乏视觉监督而在自动驾驶上失效。