一眼看懂
封面预览
研究 Vision-Language-Action (VLA) 模型在长程操作任务中失败的问题,尽管其在短程任务上表现优异
- 研究 Vision-Language-Action (VLA) 模型在长程操作任务中失败的问题,尽管其在短程任务上表现优异
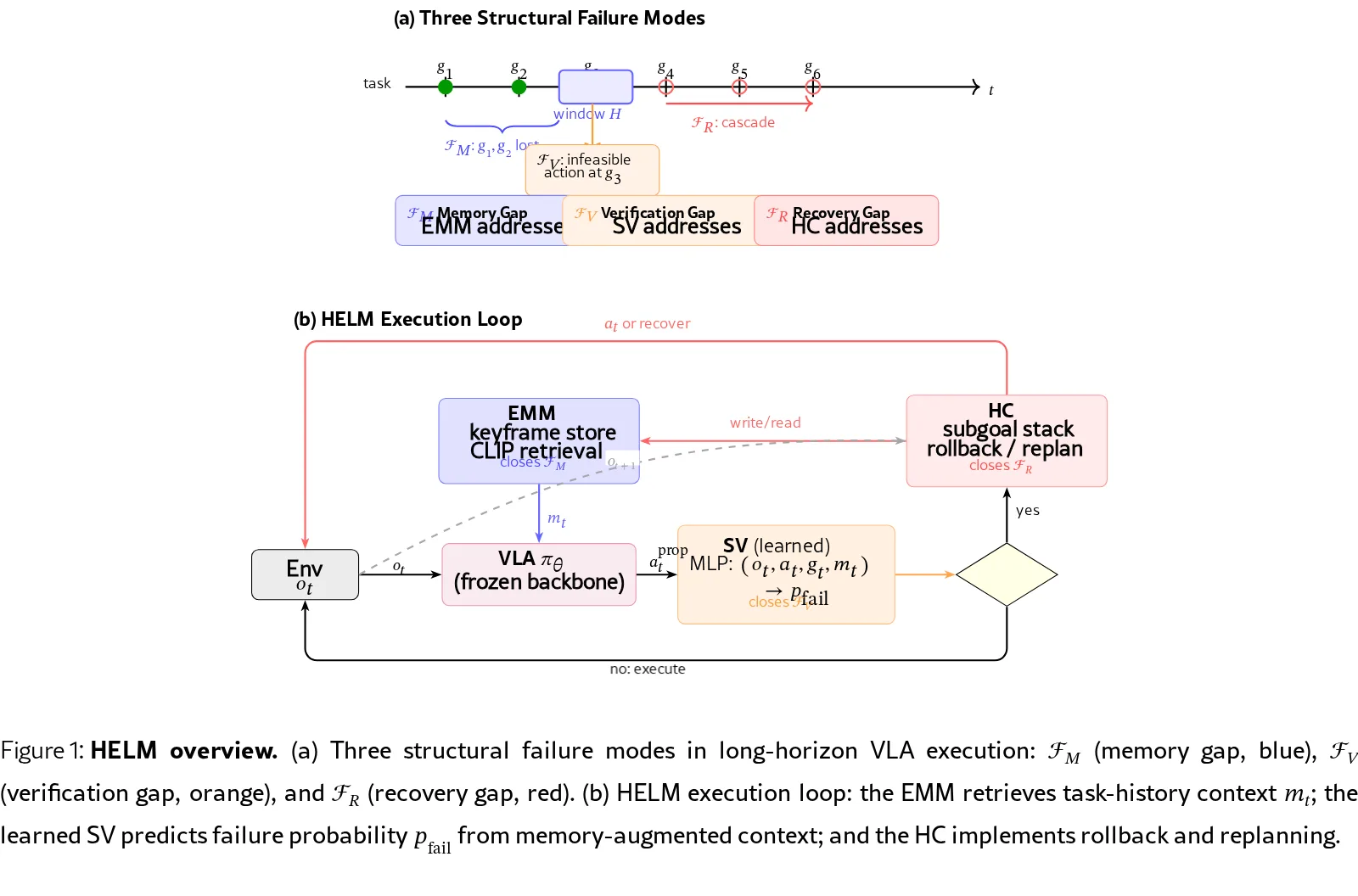
- 识别出三个执行循环缺陷:Memory Gap(跨阶段任务上下文丢失)、Verification Gap(执行前无动作验证)、Recovery…
- 提出 HELM 框架,包含三个组件: Episodic Memory Module (EMM)、State Verifier (SV)、Har…
Card 01
研究单位
研究单位
- 清华大学 (Zijian Zeng, Huiming Yang)
- 阿里巴巴集团 (Fei Ding)
- 蚌埠学院 (Xianwei Li)
Card 02
论文概述
论文概述
- 研究 Vision-Language-Action (VLA) 模型在长程操作任务中失败的问题,尽管其在短程任务上表现优异
- 识别出三个执行循环缺陷:Memory Gap(跨阶段任务上下文丢失)、Verification Gap(执行前无动作验证)、Recovery Gap(无故障检测或回滚)
- 提出 HELM 框架,包含三个组件: Episodic Memory Module (EMM)、State Verifier (SV)、Harness Controller (HC)
- 在 LIBERO-LONG 上,HELM 将任务成功率从 58.4% 提升至 81.5%(+23.1 pp),而扩展上下文窗口仅提升 +5.4 pp
Card 03
核心贡献
核心贡献
- 发现 VLA 长程失败无法仅通过更长上下文窗口解决,证实失败是结构性的
- 提出完整的 HELM 框架,包含 EMM(CLIP 索引的关键帧检索)、SV(学习的前置执行失败预测器)、HC(回滚与重规划控制器)
- SV 是核心学习贡献:一种内存条件化的前置执行失败预测器,在 12ms/step 推理延迟下表现优于规则验证器和集成不确定性方法
- 9 个基线的综合实验,包括 Oracle Memory、Long-context、Rule Verifier、Ensemble、LoRA、Reflexion 等
- 发布 LIBERO-Recovery 评估协议,用于故障恢复测试
Card 04
方法描述
方法描述
- EMM (Episodic Memory Module):基于 CLIP ViT-B/32 嵌入的关键帧存储器,在子目标完成、检测到失败或每 20 步时写入,通过余弦相似度检索 top-3 相关帧
- SV (State Verifier):3 层 MLP [1024→512→256→1],以内存增强的观察 $\hat{o}_t = [\phi(o_t); k_{top-1}]$、动作 $a_t$、子目标 $g_t$ 为输入,预测失败概率 $p_{fail}$
- HC (Harness Controller):维护子目标栈,在 $p_{fail} > \theta_v = 0.65$ 时触发回滚或重规划,最大恢复尝试次数 $R_{max}=3$
Card 05
数据集与资源
数据集与资源
- LIBERO-LONG:10 个任务,平均 5-6 个子目标,500 个评估回合
- CALVIN ABC→D:在未见环境中的平均完成链数(最多 5 个)
- LIBERO-Recovery:新提出的扰动注入评估协议
- 基础模型:OpenVLA 和 Octo
- SV 训练数据:50K VLA rollout 样本(约 2 小时单卡 A100 训练)
Card 06
评估与结果
评估与结果
- LIBERO-LONG 任务成功率 (TSR):
- OpenVLA: 58.4%
- OpenVLA H=32: 63.8%(仅 +5.4 pp)
- HELM: 81.5%(+23.1 pp)
- SV 与替代方法对比:
- Rule Verifier: +6.8 pp
- Ensemble (×5): +9.5 pp(5× 推理成本)
- SV: +8.4 pp(1× 推理成本)
- 消融实验:去除 EMM 降低 11.2 pp,去除 SV 降低 8.4 pp,SV 无内存上下文降低 6.1 pp
- 模型无关性:HELM (Octo) 从 51.2% 提升至 72.8%(+21.6 pp),与 OpenVLA 上效果相似