一眼看懂
封面预览
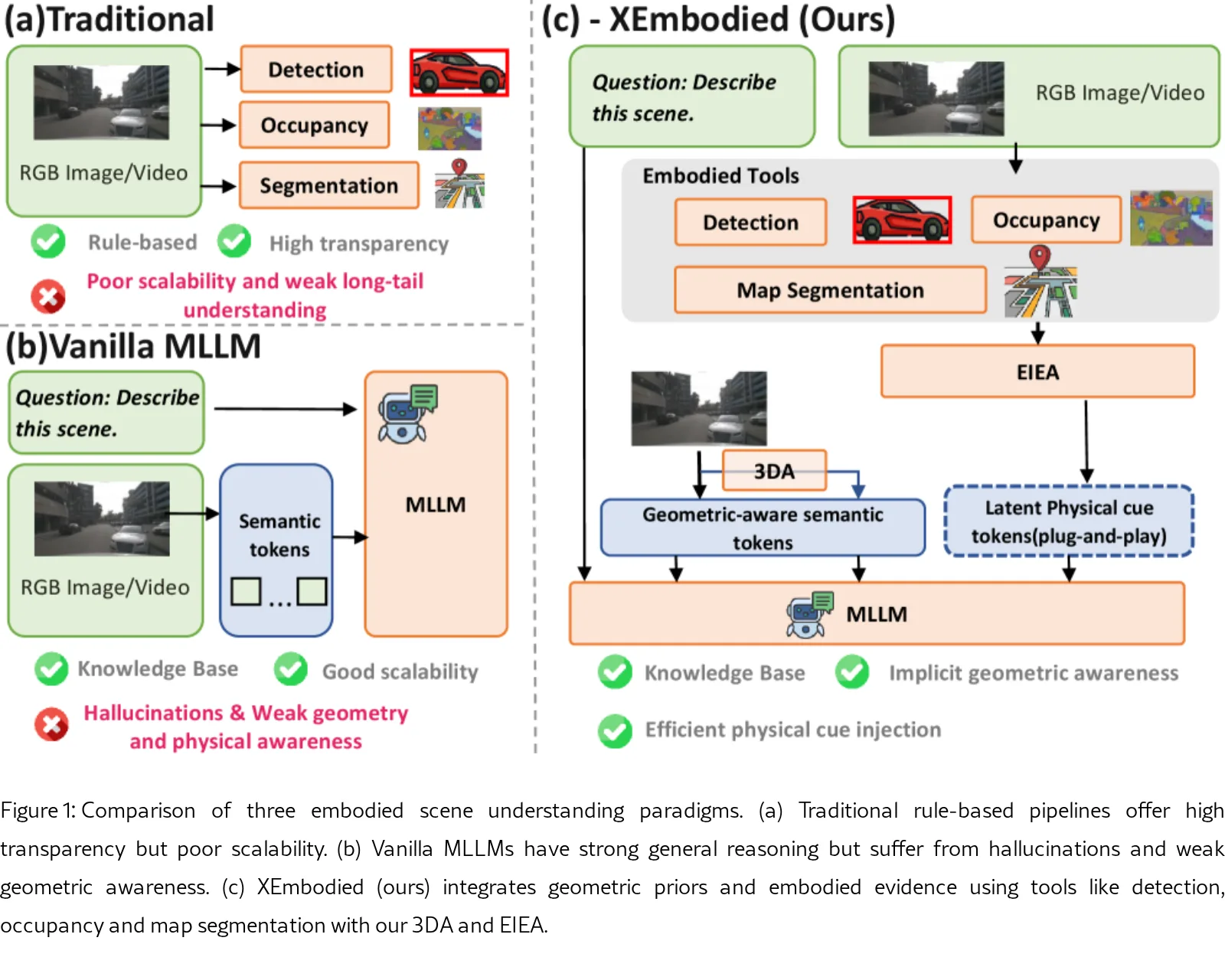
论文提出 XEmbodied,一个面向大规模具身环境(如自动驾驶与机器人)的云端基础模型。
- 论文提出 XEmbodied,一个面向大规模具身环境(如自动驾驶与机器人)的云端基础模型。
- 该模型旨在解决现有通用视觉语言模型(VLM)因2D图像-文本预训练而缺乏3D几何推理与领域语义的问题。
- 核心目标是通过增强内在的3D几何感知与物理线索交互能力,实现稳健的大规模场景挖掘与具身VQA任务。
Card 01
研究单位
研究单位
- 清华大学
- 小米公司 汽车与机器人部门
- 新加坡国立大学
- 麦吉尔大学
- 威斯康星大学麦迪逊分校
Card 02
论文概述
论文概述
- 论文提出 XEmbodied,一个面向大规模具身环境(如自动驾驶与机器人)的云端基础模型。
- 该模型旨在解决现有通用视觉语言模型(VLM)因2D图像-文本预训练而缺乏3D几何推理与领域语义的问题。
- 核心目标是通过增强内在的3D几何感知与物理线索交互能力,实现稳健的大规模场景挖掘与具身VQA任务。
Card 03
核心贡献
核心贡献
- 提出 XEmbodied,一个融合内在几何表征与物理线索交互的云端具身闭环VQA通用模型。
- 设计 3D Adapter (3DA) 与 Efficient Image-Embodied Adapter (EIEA),实现几何先验的注入与物理线索的高效整合。
- 开发一套基于空间熵评分与四级数据分类体系的 渐进式领域课程 与自动化数据治理管线,以缓解灾难性遗忘并提升分布外泛化能力。
Card 04
方法描述
方法描述
- 3D Adapter (3DA):通过一个语义流(基于Qwen3-VL)和一个几何流(基于VGGT)双流架构,利用交叉注意力机制将3D几何特征注入2D语义Token中,赋予模型内生3D能力。
- Efficient Image-Embodied Adapter (EIEA):通过模态专用特征提取、基于Mamba的多模态解释器与蒸馏压缩模块,将异构物理模态(如BEV占用、3D检测、地图分割)蒸馏为紧凑的物理线索Token,无缝注入MLLM上下文。
- 设计四阶段训练管线:依次完成领域语义对齐、3D几何对齐、端到端几何认知与EIEA训练,并结合GRPO强化学习进行后训练优化。
Card 05
数据集与资源
数据集与资源
- 训练数据涵盖自动驾驶数据集(如LingoQA、BDD100k、DriveBench)、机器人数据集(如RoboVQA、Ego3D-Bench)及通用数据集(如RefCOCO、VQAv2)。
- 模型基于 Qwen3-VL-30B-A3B-Instruct 进行微调。
- 实验在 128个 NVIDIA H20 GPU 上使用 ms-swift 框架完成。
Card 06
评估与结果
评估与结果
- 在 18个 公开基准上进行评估,涵盖空间与3D理解(如Ego3DBench、SURDS)以及语义与推理(如DriveBench、LingoQA)。
- 主要指标包括准确率(ACC)与均方根误差(RMSE)。
- 实验结果表明,XEmbodied 在多个基准上取得最佳或次佳成绩,尤其在SURDS(83.83%)、VLADBench(68.61%)和DriveLMM-o1(77.01%)等任务上显著优于现有开源模型及部分闭源模型,证明了其在空间推理、交通语义与具身能力方面的优势。