一眼看懂
封面预览
论文提出了 HY-Embodied-0.5 系列,这是一组专为真实世界具身智能体设计的基础模型。
- 论文提出了 HY-Embodied-0.5 系列,这是一组专为真实世界具身智能体设计的基础模型。
- 旨在弥合通用视觉语言模型(VLM)与具身智能需求之间的差距,解决精细视觉感知和具身推理/规划问题。
- 发布了两个主要版本:面向边缘部署的高效模型 MoT-2B 和面向复杂推理的强力模型 MoE-A32B。
Card 01
研究单位
研究单位
- 腾讯 Robotics X 实验室
- HY Vision Team(混元视觉团队)
Card 02
论文概述
论文概述
- 论文提出了 HY-Embodied-0.5 系列,这是一组专为真实世界具身智能体设计的基础模型。
- 旨在弥合通用视觉语言模型(VLM)与具身智能需求之间的差距,解决精细视觉感知和具身推理/规划问题。
- 发布了两个主要版本:面向边缘部署的高效模型 MoT-2B 和面向复杂推理的强力模型 MoE-A32B。
Card 03
核心贡献
核心贡献
- 引入 Mixture-of-Transformers (MoT) 架构,实现模态自适应计算,解耦视觉和语言参数以增强视觉建模能力。
- 设计 Visual Latent Tokens(视觉潜在 Token)连接视觉与语言模态,提升感知表征能力。
- 提出迭代式自演化后训练范式,结合强化学习(RL)和拒绝采样微调(RFT)提升深层推理能力。
- 采用 Large-to-Small On-Policy Distillation(在策略蒸馏),将大模型的能力高效迁移至边缘小模型。
Card 04
方法描述
方法描述
- 视觉编码器采用 HY-ViT 2.0,支持原生分辨率输入,通过知识蒸馏优化以适配边缘设备(400M 参数)。
- MoT 架构为视觉分支设计了独立的双向注意力机制和 FFN 层,避免重度视觉训练削弱语言能力。
- 在视觉输入序列末尾附加可学习的视觉潜在 Token,并使用全局特征监督辅助训练。
- 强化学习阶段设计了任务感知奖励机制,涵盖定位、回归、轨迹和文本推理四类任务。
Card 05
数据集与资源
数据集与资源
- 预训练数据量超过 600B tokens,包含通用理解和具身/感知数据。
- 中期训练使用约 25M 高质量样本,涵盖 Omni-Detection(62M)、深度估计(36M)、分割(5M)等数据。
- 模型规模:MoT-2B(激活 2B/总参数 4B),MoE-A32B(激活 32B/总参数 407B)。
Card 06
评估与结果
评估与结果
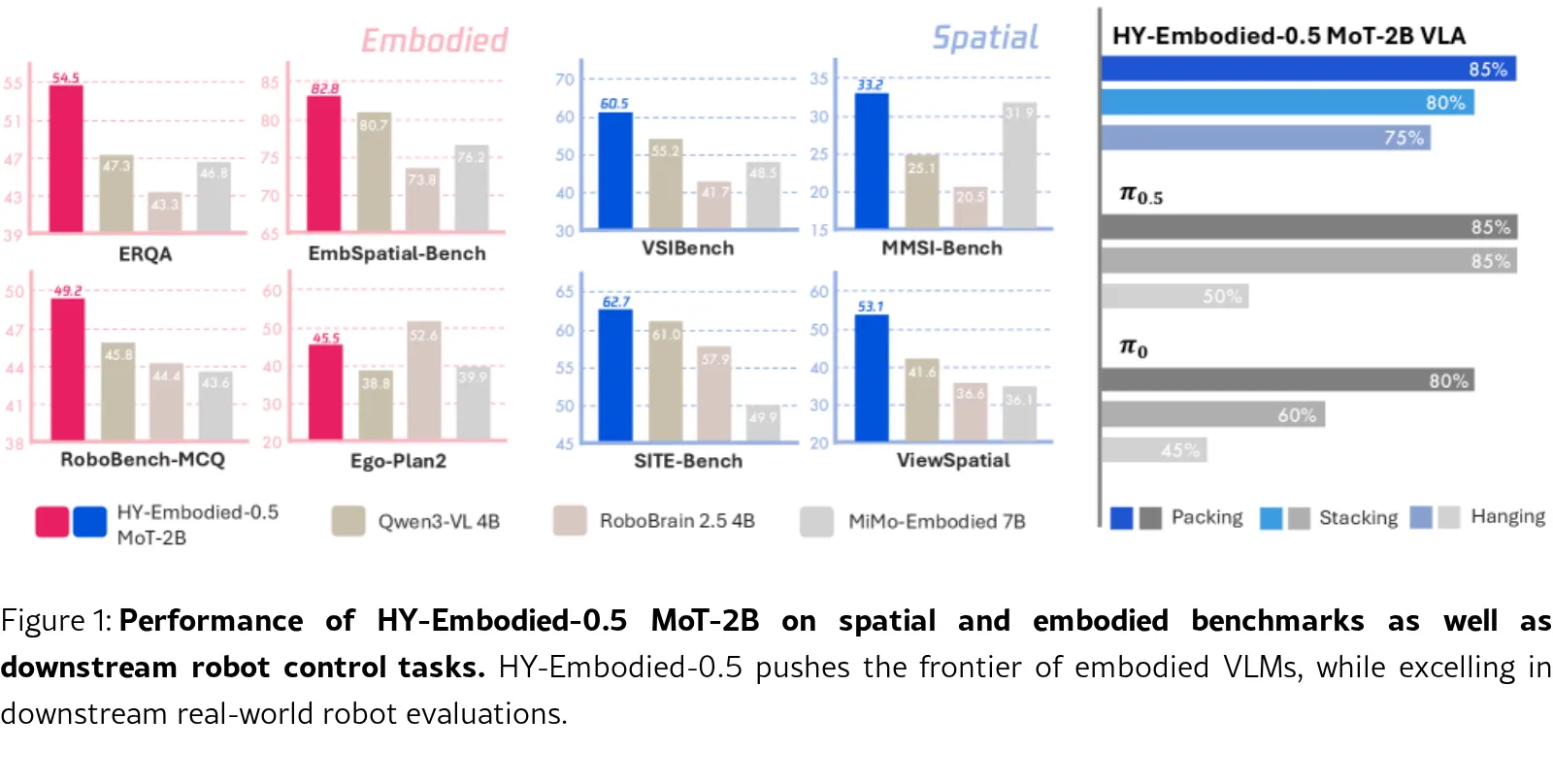
- 在涵盖视觉感知、空间推理和具身理解的 22 个基准 上进行了全面评估。
- MoT-2B 模型在 16/22 基准上取得最佳表现,平均分 58.0%,超越参数量更大的 Qwen3-VL-4B 和 RoboBrain2.5-4B。
- MoE-A32B 模型平均分达到 67.0%,超越了前沿模型 Gemini 3.0 Pro(63.6%)和 Seed 2.0(66.2%)。