一眼看懂
封面预览
论文提出一个名为 A₁ 的完全开源、透明、自适应且高效的截断视觉-语言-动作模型,旨在解决现有VLA模型部署成本高、推理延迟大,难以在普通硬件…
- 论文提出一个名为 A₁ 的完全开源、透明、自适应且高效的截断视觉-语言-动作模型,旨在解决现有VLA模型部署成本高、推理延迟大,难以在普通硬件…
- 核心设计理念是“预算感知自适应推理”,通过联合加速 VLM主干 和 动作头,在不牺牲操作成功率的前提下,实现低成本、高吞吐量的推理。
- 论文释放了完整的训练栈(代码、数据处理管道、中间检查点、评估脚本),以确保端到端的可复现性,并承诺将模型权重与所有相关组件开源。
Card 01
研究单位
研究单位
- SYSU (中山大学)
- MBZUAI (穆罕默德·本·扎耶德人工智能大学)
- Spatialtemporal AI
Card 02
论文概述
论文概述
- 论文提出一个名为 A₁ 的完全开源、透明、自适应且高效的截断视觉-语言-动作模型,旨在解决现有VLA模型部署成本高、推理延迟大,难以在普通硬件上实现实时控制的问题。
- 核心设计理念是“预算感知自适应推理”,通过联合加速 VLM主干 和 动作头,在不牺牲操作成功率的前提下,实现低成本、高吞吐量的推理。
- 论文释放了完整的训练栈(代码、数据处理管道、中间检查点、评估脚本),以确保端到端的可复现性,并承诺将模型权重与所有相关组件开源。
Card 03
核心贡献
核心贡献
- 提出一种联合加速方案:通过 动作一致性阈值 触发的早期终止来减少VLM冗余计算,并通过 跨层截断流匹配 进行热启动去噪,大幅降低端到端推理延迟。
- 进行了可扩展的多机器人预训练:利用开源机器人数据集及自收集的 15,951 条轨迹,在多种机器人平台上进行训练,以支持鲁棒的跨平台泛化。
- 取得了强大的实证结果:在 RoboChallenge 上达到平均 29.00% 的成功率,优于多个开源基线模型;并承诺完全开源模型权重、代码与评估协议。
Card 04
方法描述
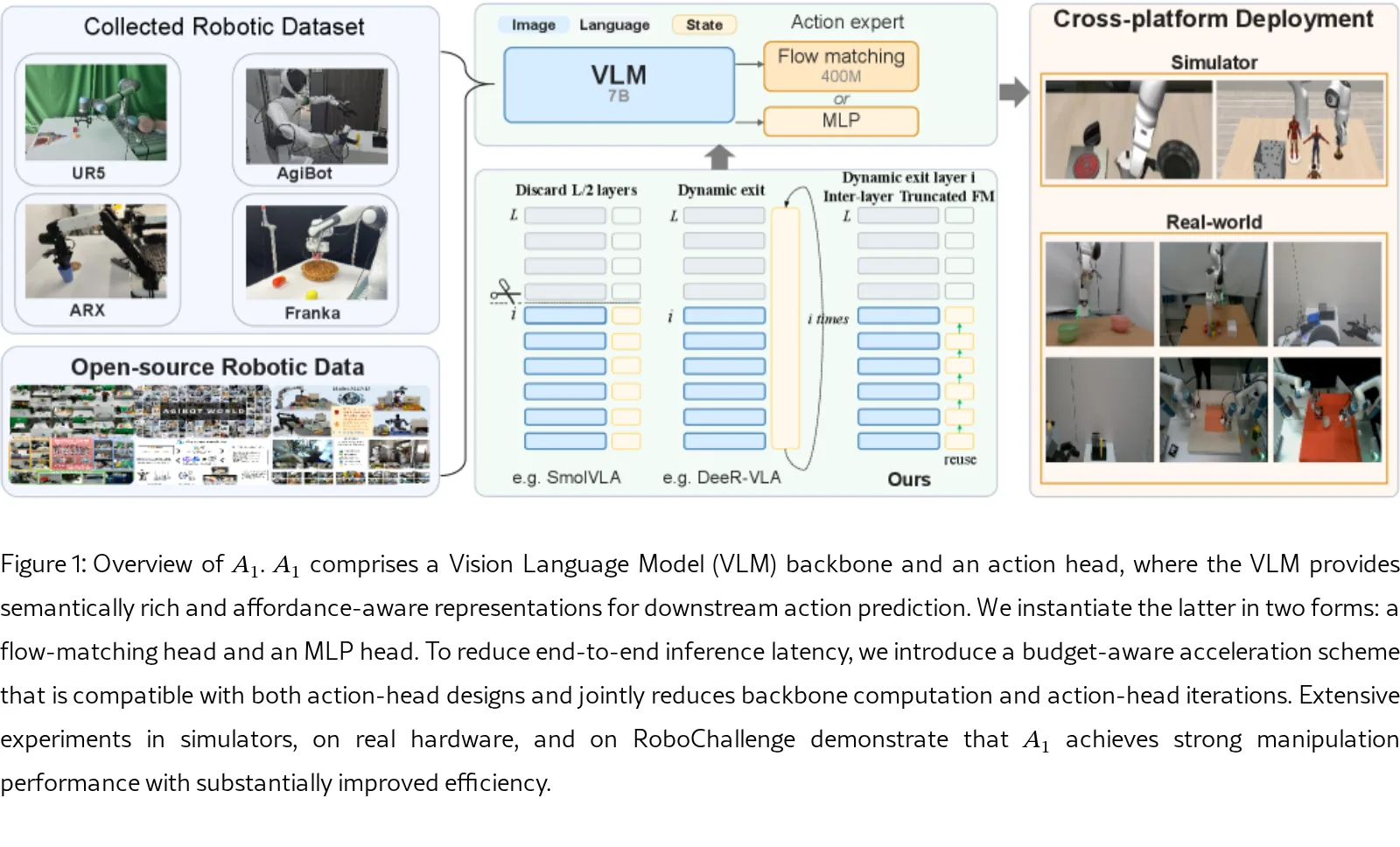
方法描述
- 模型架构包含一个基于 Molmo 的VLM主干和一个动作头,动作头可实例化为 流匹配(FM) 头或 MLP 头。
- 创新点在于自适应推理加速:在推理过程中,计算各中间VLM层的动作并进行 动作一致性测试,若满足阈值则提前终止,避免完整深度的主干计算。
- 为避免加速主干时导致FM动作头成为新瓶颈,提出 跨层截断流匹配:每层仅执行少量去噪步骤(如δ=2),并将当前层的输出作为下一层的初始条件,实现去噪过程的“热启动”。
Card 05
数据集与资源
数据集与资源
- 预训练数据集包括开源数据集:DROID、AgiBot、RoboCOIN、RoboMind、GM-100、RoboChallenge。
- 额外收集了 15,951 条真实世界轨迹,涵盖 ARX、Franka、UR5、Agibot 等多种机器人平台。
- 模型主干采用 Molmo-7B VLM(约11.07 TFLOPs),动作头采用 Qwen3-400M 参数量的流匹配专家或轻量MLP头。
- 训练资源未在文中详细说明,但提供了计算成本分析(如FLOPs和推理时间)。
Card 06
评估与结果
评估与结果
- 评估环境包括模拟基准:LIBERO 和 VLABench;以及真实机器人平台:Franka、AgiBot、WuJie-Arm、Dobot-Arm 和 RoboChallenge。
- 主要评估指标为操作任务的 成功率。
- 关键结果:在 LIBERO 上平均成功率达 96.6%,在 VLABench 上达 53.5%;在真实世界多机器人实验中平均成功率为 56.7%,显著优于基线;在 RoboChallenge 上平均成功率为 29.00%,排名第六并超越了 π₀、X-VLA 等开源基线。