一眼看懂
封面预览
研究大型多模态模型(LMMs)在城市空中空间进行目标导向具身导航的空间决策与行动能力
- 研究大型多模态模型(LMMs)在城市空中空间进行目标导向具身导航的空间决策与行动能力
- 构建了包含5,037条高质量导航轨迹的数据集,评估17个代表性模型(包括非推理LMMs、推理LMMs、基于智能体的方法和视觉-语言-动作模型)
- 揭示LMMs在关键决策分叉点(CDB)后错误非线性累积而是快速偏离的现象,系统分析LMMs与人类水平的空间行动差距
Card 01
研究单位
研究单位
- 清华大学深圳国际研究生院 (Shenzhen International Graduate School, Tsinghua University)
- 东北大学 (Northeastern University)
- 国防科技大学 (National University of Defense Technology)
- 山东大学 (Shandong University)
- 清华大学智能产业研究院 (BNRist, Tsinghua University)
Card 02
论文概述
论文概述
- 研究大型多模态模型(LMMs)在城市空中空间进行目标导向具身导航的空间决策与行动能力
- 构建了包含5,037条高质量导航轨迹的数据集,评估17个代表性模型(包括非推理LMMs、推理LMMs、基于智能体的方法和视觉-语言-动作模型)
- 揭示LMMs在关键决策分叉点(CDB)后错误非线性累积而是快速偏离的现象,系统分析LMMs与人类水平的空间行动差距
Card 03
核心贡献
核心贡献
- 构建了5,037条目标导向具身导航轨迹的高质量数据集,强调3D垂直动作和丰富城市语义信息
- 对17个流行模型进行全面评估,涵盖非推理LMMs、推理LMMs、基于智能体的方法和VLA模型
- 提出关键决策分叉(CDB)现象来表征LMM空间行动的失败模式
- 从CDB视角识别LMM的四大核心缺陷:几何感知不足、跨视角理解有限、空间想象力缺乏、长期记忆缺陷
- 实验探索四个有前景的改进方向:几何感知增强、跨视角理解增强、空间想象力、稀疏记忆
Card 04
方法描述
方法描述
- 采用三种评估范式:Action-as-Language(动作作为语言)、Action-as-Reasoning(动作作为推理)、Action-as-Token(动作作为Token)
- 使用EmbodiedCity模拟器(基于Unreal Engine + AirSim)构建真实城市环境
- 通过三阶段数据收集流程:场景选择、目标导向指令生成、专业无人机飞行员执行导航
- 引入关键决策分叉(CDB)分析方法,追踪导航完成进度随步骤的变化曲线
Card 05
数据集与资源
数据集与资源
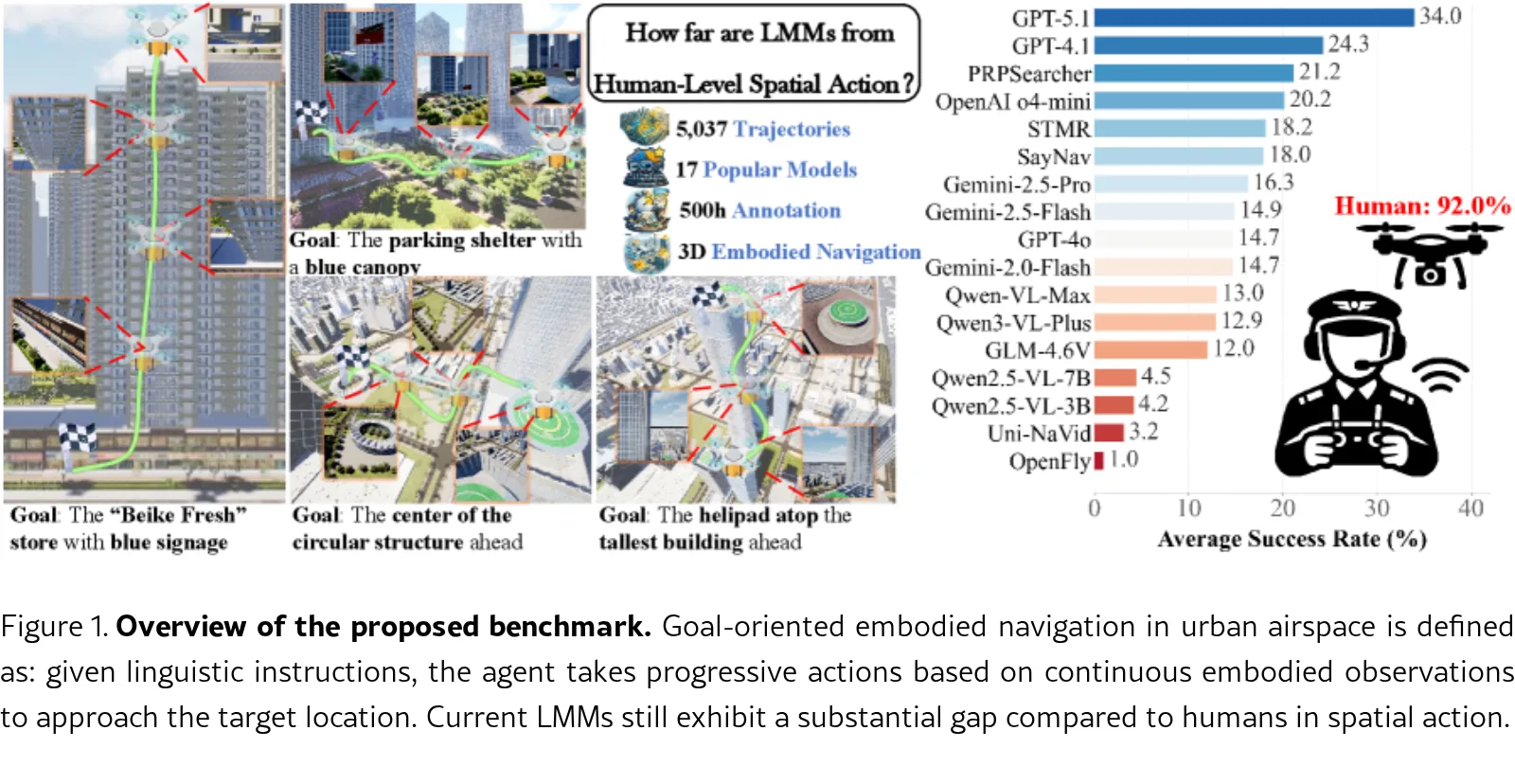
- 数据集规模:5,037条高质量目标导向导航样本,平均轨迹长度约203.4米
- 动作分布:水平移动45.0%、垂直移动28.2%、旋转动作26.8%(平衡的3D动作分布)
- 数据收集:10名志愿者,超过500人时的手动标注工作
- 评估模型:包括GPT-4o、GPT-5.1、Gemini-2.5系列、Qwen2.5-VL系列、OpenAI o4-mini等17个模型
Card 06
评估与结果
评估与结果
- 评估指标:成功率(SR)、路径长度加权成功率(SPL)、到目标的距离(DTG)
- 主要结果:
- 人类表现:SR 92.0%,SPL 90.4%
- 最佳LMM(GPT-5.1):SR 34.0%,SPL 32.0%,显著落后于人类
- 推理增强LMMs在中长距离导航中表现更优,展现更好的规划和错误纠正能力
- VLA模型(OpenFly、Uni-NaVid)表现甚至差于随机基线,存在严重的域外泛化问题
- 关键发现:LMMs在关键决策分叉点后错误快速累积,而非线性增长;几何感知增强可带来SR提升9.5%(从14.7%到24.2%)