一眼看懂
封面预览
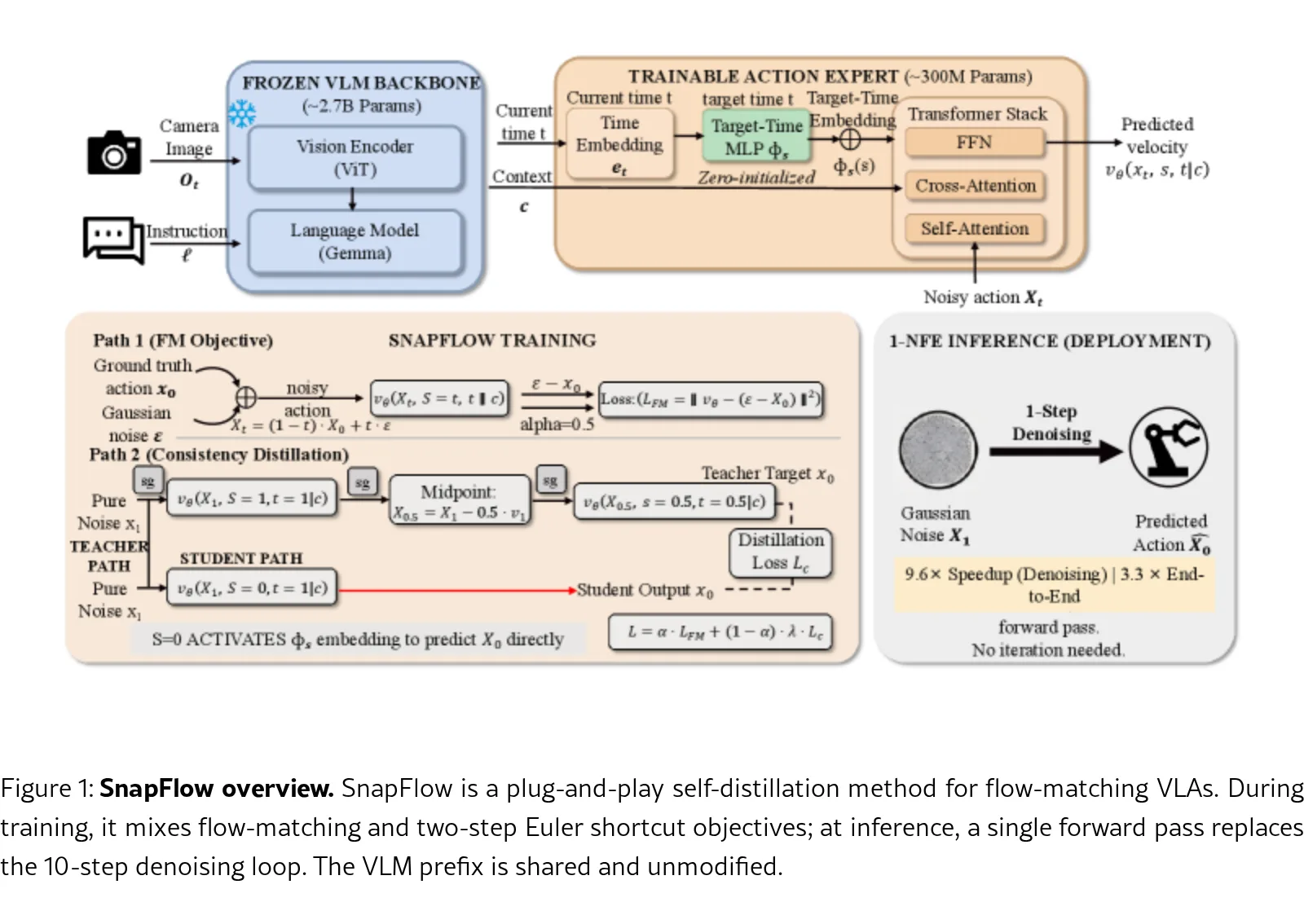
针对 Flow-Matching Vision-Language-Action (VLA) 模型(如 $\pi_0$、$\pi_{0.5}$…
- 针对 Flow-Matching Vision-Language-Action (VLA) 模型(如 $\pi_0$、$\pi_{0.5}$…
- 该方法旨在将多步迭代去噪过程(通常为 10 步 ODE)压缩为单次前向传播(1-NFE),实现实时机器人操作所需的推理速度
- 解决了简单减少推理步数导致性能下降的问题,通过修正的一致性目标避免了轨迹漂移,在提升速度的同时保持了甚至略微超越了原模型的生成质量
Card 01
研究单位
研究单位
- Jilin University
- Chongqing University
- University of Liverpool
- GenY
Card 02
论文概述
论文概述
- 针对 Flow-Matching Vision-Language-Action (VLA) 模型(如 $\pi_0$、$\pi_{0.5}$ 和 SmolVLA)推理延迟高的问题,提出了一种无需外部教师、无需架构更改的自蒸馏方法
- 该方法旨在将多步迭代去噪过程(通常为 10 步 ODE)压缩为单次前向传播(1-NFE),实现实时机器人操作所需的推理速度
- 解决了简单减少推理步数导致性能下降的问题,通过修正的一致性目标避免了轨迹漂移,在提升速度的同时保持了甚至略微超越了原模型的生成质量
Card 03
核心贡献
核心贡献
- 提出了 SnapFlow 框架:一种渐进式自蒸馏方法,通过混合 Flow Matching 和一致性样本实现 1-NFE 推理,仅需约 12 小时在单个 GPU 上训练
- 在质量-速度权衡上表现优异:在 LIBERO 基准上,单步 SnapFlow 达到 98.75% 成功率,略微超越 10 步基线(97.75%),同时实现了 9.6 倍的去噪加速
- 方法具有通用性和正交性:在 $\pi_{0.5}$ (3B) 和 SmolVLA (500M) 两种不同架构上验证了有效性,且可与层级蒸馏等加速方法叠加
Card 04
方法描述
方法描述
- 基于理论分析(定理 1-3),指出使用条件速度替代边际速度会导致轨迹漂移,提出了修正的一致性目标,使用模型自身的边际速度预测
- 采用 Two-Step Euler Shortcut Target:通过计算两个时间点($t=1$ 和 $t=0.5$)的速度平均值作为训练目标,避免了昂贵的梯度计算
- 引入 Progressive FM/Consistency Mixing:按比例 $\alpha$ 混合标准 Flow Matching 损失和 Shortcut 损失,以稳定训练并保持速度估计器的准确性
- 设计了 Target-Time Embedding:一个零初始化的 MLP,添加到时间嵌入中,使网络能在同一架构内区分局部速度估计和全局单步生成模式
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO 基准(包含 4 个套件,共 40 个任务,400 个测试回合)和 PushT 数据集进行评估
- 评估模型包括 $\pi_{0.5}$ (3B 参数) 和 SmolVLA (500M 参数),覆盖了不同规模的 VLA 架构
- 训练资源为单张 A800-80G GPU,训练时长约 12 小时(30k 步),仅训练动作专家部分(约 10% 参数)
Card 06
评估与结果
评估与结果
- 在 LIBERO 闭环评估中,$\pi_{0.5}$ + SnapFlow 单步推理成功率达到 98.75%,端到端延迟从 274ms 降低至 83ms(3.3 倍加速)
- 在离线指标分析中,SnapFlow 显著降低了尾部误差(P95 MSE 降低 29.4%),提升了动作预测的稳定性
- 在 SmolVLA 上,MSE 降低 8.3%,CosSim 提升 6.9%,实现了 3.56 倍的端到端加速
- 实验表明 SnapFlow 在不同执行视界下均保持优势,在长视界任务中表现更稳健