一眼看懂
封面预览
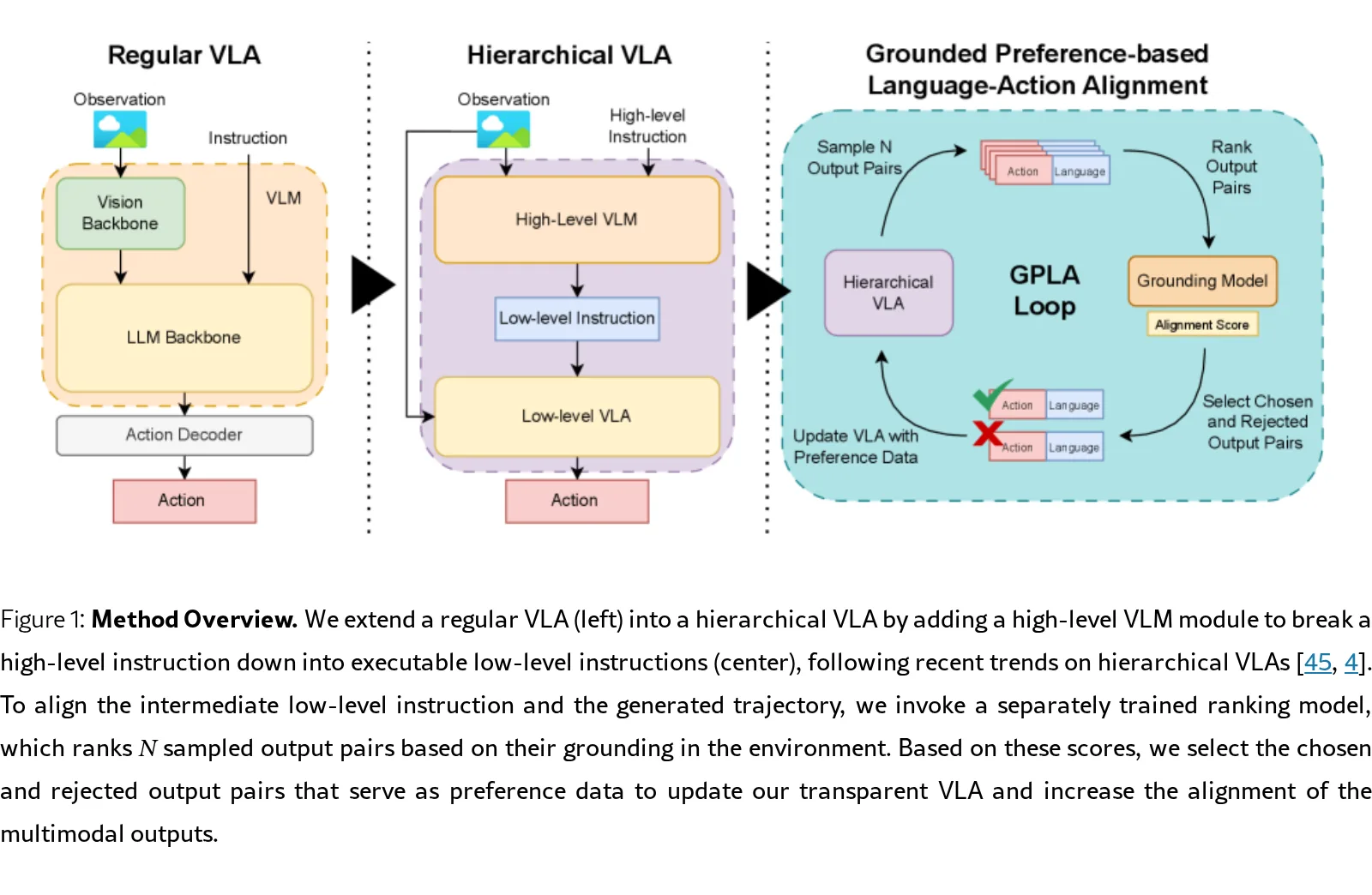
针对现有分层视觉-语言-动作模型在生成自然语言子任务描述和底层动作时缺乏显式对齐的问题,提出了一种新的训练框架以增强机器人的透明性
- 针对现有分层视觉-语言-动作模型在生成自然语言子任务描述和底层动作时缺乏显式对齐的问题,提出了一种新的训练框架以增强机器人的透明性
- 旨在解决语言模态与动作模态在训练过程中的分离问题,确保生成的语言能够真实地反映视觉观察和动作轨迹
- 提出了名为 GPLA 的框架,通过对比模型评估语言与动作的对齐程度,并利用偏好学习来优化分层 VLA 模型
Card 01
研究单位
研究单位
- The University of Manchester
Card 02
论文概述
论文概述
- 针对现有分层视觉-语言-动作模型在生成自然语言子任务描述和底层动作时缺乏显式对齐的问题,提出了一种新的训练框架以增强机器人的透明性
- 旨在解决语言模态与动作模态在训练过程中的分离问题,确保生成的语言能够真实地反映视觉观察和动作轨迹
- 提出了名为 GPLA 的框架,通过对比模型评估语言与动作的对齐程度,并利用偏好学习来优化分层 VLA 模型
Card 03
核心贡献
核心贡献
- 提出了 GPLA (Grounded Preference-based Language-Action Alignment) 框架,通过偏好学习直接将分层 VLA 的中间语言输出与视觉观察和动作进行对齐,减少了对昂贵人工标注的依赖
- 构建了一个动作条件化的接地模型,能够将视觉、动作和文本映射到共享的嵌入空间,用于生成显式的接地评分以排序不同的语言-轨迹配对
- 在 LanguageTable 操控基准测试上验证了该方法的有效性,证明其能够达到与完全监督微调相当的性能,同时提供了对多模态接地表示的关键见解
Card 04
方法描述
方法描述
- 构建分层 VLA 模型:高层使用 Gemma3-4B-IT VLM 将指令分解为底层指令,底层使用 SmolVLA 根据底层指令生成动作轨迹
- 设计动作条件化接地模型:基于 SigLIP 2 初始化视觉和文本编码器,使用 Transformer 编码动作,通过 FiLM 层将动作特征调制到视觉特征中,利用 InfoNCE 损失进行对比学习
- GPLA 训练流程:采样多个语言-动作候选,利用接地模型计算评分,选择最高和最低评分构建偏好对,使用 SimPO 损失函数对高层 VLM 进行微调
Card 05
数据集与资源
数据集与资源
- 使用 LanguageTable 数据集,包含 Franka 机械臂推动物体的轨迹及人类语言标注
- 高层 VLM 模型为 Gemma-3-4B-IT,底层 VLA 模型为 SmolVLA
- 训练资源:使用单个 NVIDIA A100 GPU
Card 06
评估与结果
评估与结果
- 评估基准:LanguageTable 操控任务,测试集为训练期间未使用的片段
- 评估指标:语言生成指标 (BLEU, ROUGE, METEOR, BERTScore) 和轨迹生成指标 (MSE, MAE, Cosine Similarity)
- 关键结果:GPLA 在轨迹生成任务上取得了与监督微调基线相当的性能 (MSE ~0.045),且无需依赖中间输出的真实标签;嵌入空间可视化显示该模型比 CLIP 或 SigLIP 2 更有效地融合了视觉和语言特征