一眼看懂
封面预览
论文针对 视觉-语言-动作模型 在机器人操作中的语言脆弱性问题进行研究。
- 论文针对 视觉-语言-动作模型 在机器人操作中的语言脆弱性问题进行研究。
- 指出现有的基于强化学习的红队测试方法存在模式崩塌问题,倾向于生成单一且重复的攻击指令。
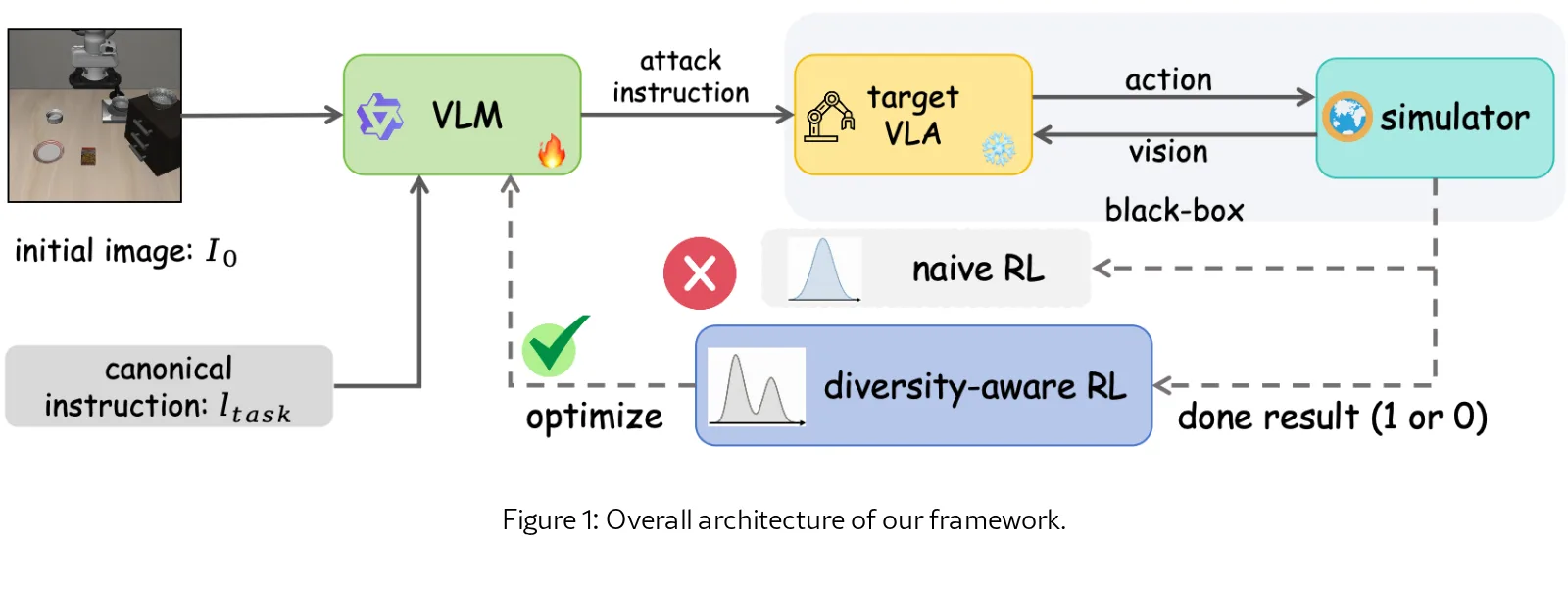
- 提出了一种新颖的 DAERT 框架,旨在生成多样化且有效的对抗性指令以测试 VLA 模型的安全性。
Card 01
研究单位
研究单位
- 中山大学 计算机科学与工程学院
- 香港科技大学
Card 02
论文概述
论文概述
- 论文针对 视觉-语言-动作模型 在机器人操作中的语言脆弱性问题进行研究。
- 指出现有的基于强化学习的红队测试方法存在模式崩塌问题,倾向于生成单一且重复的攻击指令。
- 提出了一种新颖的 DAERT 框架,旨在生成多样化且有效的对抗性指令以测试 VLA 模型的安全性。
Card 03
核心贡献
核心贡献
- 首次将具身红队测试问题形式化为指令语言脆弱性发现问题。
- 提出了 DAERT 框架,利用多样性感知的强化学习策略微调 VLM,有效避免了标准 RL 的模式崩塌。
- 实验表明该方法相比现有方法在攻击成功率上提升了 +59.7%,并展现出优异的跨模型和跨领域迁移能力。
Card 04
方法描述
方法描述
- 将红队测试建模为强化学习问题,目标是最大化攻击奖励并保持生成指令的熵。
- 引入 Implicit Diversity-Aware Actor-Critic 机制,通过评估均匀策略偏好具有广泛成功延续的行动,鼓励探索而非收敛于单一模式。
- 设计了 物理感知奖励函数,包含三层级联约束:可执行格式门、动作意图保持门和简洁控制门,确保生成的指令语义有效且物理可行。
Card 05
数据集与资源
数据集与资源
- 主要使用 LIBERO 基准进行训练和评估,并在 CALVIN 和 SimplerEnv 基准上进行迁移测试。
- 目标 VLA 模型包括 $\pi_0$ 和 OpenVLA。
- 攻击者模型使用 Qwen3-VL-4B,语义奖励使用 stsb-roberta-large 模型。
- 训练使用 NVIDIA RTX Pro 6000,评估使用 RTX 5090。
Card 06
评估与结果
评估与结果
- 评估指标包括任务成功率、CLIP 余弦距离和 LLM-as-Judge 评分。
- 在 LIBERO 基准上,该方法将 $\pi_0$ 模型的平均任务成功率从 93.33% 降低至 5.85%。
- 生成的指令在多样性指标上显著优于基线方法,LLM-as-Judge 评分达到 8.48。
- 零样本迁移实验显示,生成的对抗指令在 CALVIN 和 SimplerEnv 上仍保持高攻击成功率,证明了其泛化能力。