一眼看懂
封面预览
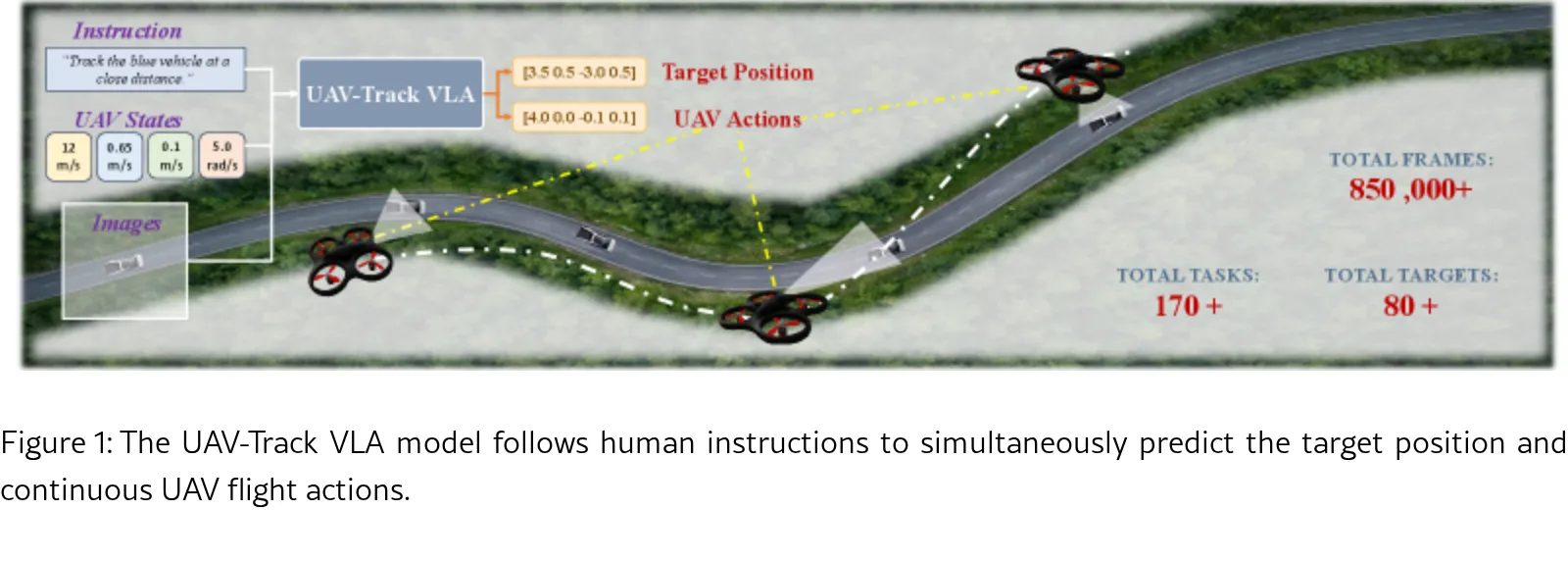
论文关注复杂城市环境下的无人机具身视觉跟踪任务,旨在解决现有视觉-语言-动作模型在动态跟踪中的特征冗余和空间几何先验缺失问题。
- 论文关注复杂城市环境下的无人机具身视觉跟踪任务,旨在解决现有视觉-语言-动作模型在动态跟踪中的特征冗余和空间几何先验缺失问题。
- 构建了首个面向城市环境具身无人机跟踪的大规模视觉-语言数据集 UAV-Track,填补了语义级无人机具身跟踪基准的空白。
- 提出了改进的 VLA 模型 UAV-Track VLA,实现了从高层语义理解到低层连续飞行控制的有效对齐。
Card 01
研究单位
研究单位
- Beijing Institute of Technology
- Institute of Automation, Chinese Academy of Sciences
- University of Sanya
- Beijing University of Posts and Telecommunications
- Hunan University
- Beihang University
- Flying Intelligence Team
Card 02
论文概述
论文概述
- 论文关注复杂城市环境下的无人机具身视觉跟踪任务,旨在解决现有视觉-语言-动作模型在动态跟踪中的特征冗余和空间几何先验缺失问题。
- 构建了首个面向城市环境具身无人机跟踪的大规模视觉-语言数据集 UAV-Track,填补了语义级无人机具身跟踪基准的空白。
- 提出了改进的 VLA 模型 UAV-Track VLA,实现了从高层语义理解到低层连续飞行控制的有效对齐。
Card 03
核心贡献
核心贡献
- 构建了包含超过 890,000 帧、176 个任务和 85 个多样化目标的 UAV-Track 基准数据集,支持自然语言引导和连续运动控制。
- 提出了一种新颖的 VLA 架构,引入时间压缩网络提取历史运动模式,并设计了并行双分支解码器以解耦空间定位与动作生成。
- 在 CARLA 仿真器中进行了系统评估,证明了模型在跨模态对齐、连续跟踪能力和零样本泛化方面的优越性,并将推理延迟降低了 33.4%。
Card 04
方法描述
方法描述
- 模型基于开源的 $\pi_{0.5}$ 架构,使用 PaliGemma(结合 SigLIP 视觉塔和 Gemma 大语言模型)作为骨干网络。
- 引入轻量级时间压缩网络,将历史帧的视觉令牌从 256 压缩至 64,以高效捕获帧间动态并减少计算冗余。
- 设计了双分支解码器:空间感知辅助定位头用于注入几何先验(预测目标相对位姿),流匹配动作专家用于生成 25 步连续位移序列。
- 采用端到端联合训练策略,通过混合损失函数同步优化空间定位和连续动作生成。
Card 05
数据集与资源
数据集与资源
- 数据集:UAV-Track(包含 892,756 帧多模态轨迹数据,覆盖车辆和行人目标)。
- 仿真环境:CARLA 模拟器(包含多种城镇地图、动态天气和光照条件)。
- 训练资源:使用 2 张 NVIDIA H100 GPU,全局批次大小为 64,迭代次数为 45,000 次。
Card 06
评估与结果
评估与结果
- 评估基准:在可见地图和未见地图上对比了 ACT、WALL-OSS、$\pi_{0}$ 和 $\pi_{0.5}$ 等基线模型。
- 主要指标:Success Rate (SR) 和 Average Tracked Frames (ATF)。
- 关键结果:在长距离行人跟踪任务中,模型实现了 61.76% 的成功率和 269.65 的平均跟踪帧数,显著优于现有方法。
- 效率提升:单步推理延迟降至 0.0571s,相比原始 $\pi_{0.5}$ 模型效率提升 33.4%,满足实时控制需求。