一眼看懂
封面预览
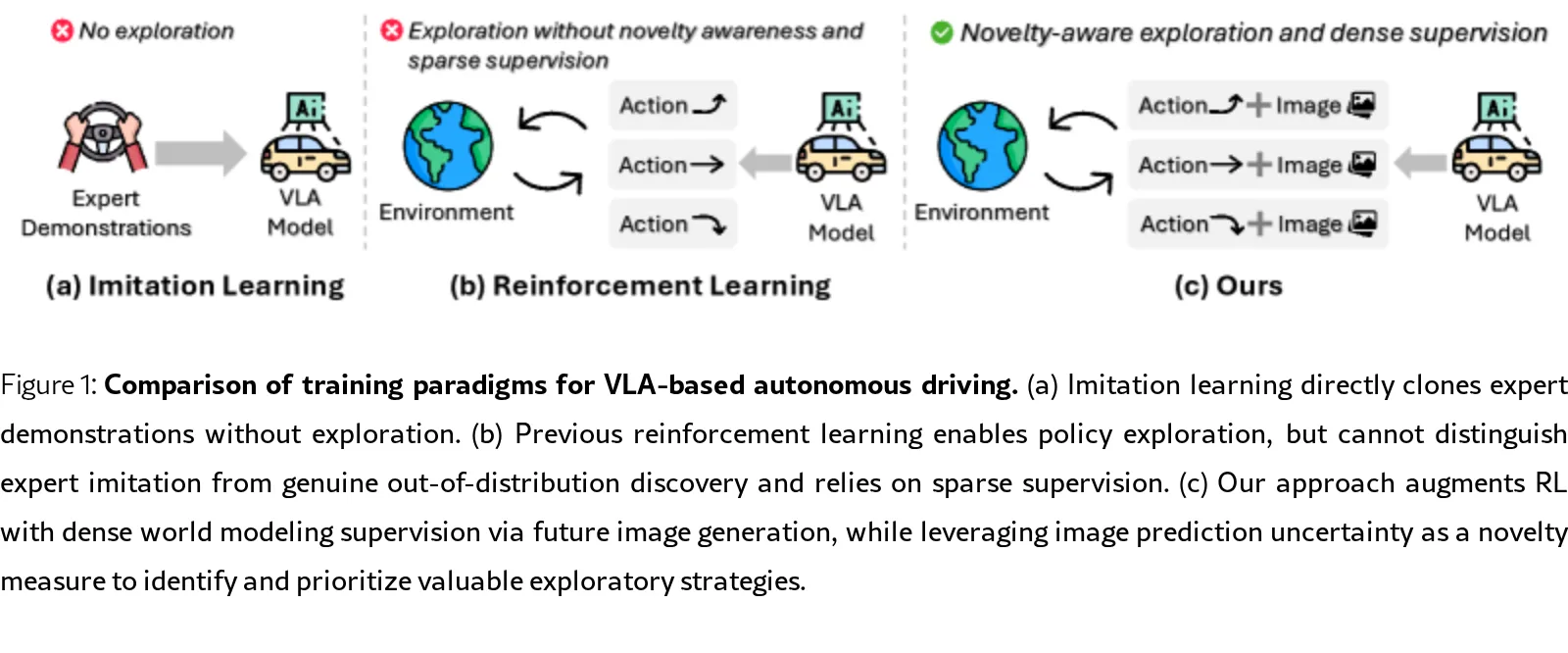
论文提出了 ExploreVLA,一个统一的“理解-生成”框架,旨在解决端到端自动驾驶中现有VLA模型缺乏策略探索和监督信号稀疏的核心问题。
- 论文提出了 ExploreVLA,一个统一的“理解-生成”框架,旨在解决端到端自动驾驶中现有VLA模型缺乏策略探索和监督信号稀疏的核心问题。
- 核心方法是通过密集的世界建模,即联合预测未来轨迹、RGB图像和深度图像,为规划骨干网络提供丰富的视觉与几何监督。
- 同时,利用世界模型的图像预测不确定性作为内在奖励信号,引导策略在专家演示之外探索新颖且安全的驾驶策略。
Card 01
研究单位
研究单位
- Bosch Research North America & Bosch Center for Artificial Intelligence (BCAI)
- University of Wisconsin–Madison
Card 02
论文概述
论文概述
- 论文提出了 ExploreVLA,一个统一的“理解-生成”框架,旨在解决端到端自动驾驶中现有VLA模型缺乏策略探索和监督信号稀疏的核心问题。
- 核心方法是通过密集的世界建模,即联合预测未来轨迹、RGB图像和深度图像,为规划骨干网络提供丰富的视觉与几何监督。
- 同时,利用世界模型的图像预测不确定性作为内在奖励信号,引导策略在专家演示之外探索新颖且安全的驾驶策略。
Card 03
核心贡献
核心贡献
- 提出了一种新颖的探索机制,利用世界模型的图像预测不确定性作为内在新颖度度量,结合安全门控奖励,鼓励有益的分布外探索。
- 提出了一个统一VLA框架,能够联合预测未来轨迹、RGB图像和深度图像,利用密集世界建模为规划骨干网络提供丰富的视觉和几何监督。
- 在 NAVSIM 基准上取得了state-of-the-art性能,PDMS 达到 93.7,EPDMS 达到 88.8,并在 nuScenes 数据集上验证了方法的泛化性。
Card 04
方法描述
方法描述
- 模型基于 Show-o 架构,构建了一个统一的VLM骨干,支持自回归文本建模和离散图像生成。
- 引入未来 RGB 和 深度 图像生成作为辅助世界建模目标,通过掩码令牌预测损失提供token级的密集监督。
- 利用世界模型在预测未来图像时的不确定性(通过预测概率分布的熵计算)作为内在奖励,量化轨迹相对于训练分布的新颖性。
- 采用 Group Relative Policy Optimization (GRPO) 算法,结合安全门控的内在奖励(由 PDMS 分数阈值控制)优化策略,引导其发现多样且安全的驾驶行为。
Card 05
数据集与资源
数据集与资源
- 主要评估基准为 NAVSIM (v1 和 v2) 和 nuScenes 数据集。
- 模型骨干为 Show-o,图像tokenizer为 MAGVIT-v2。
- 训练使用 4×H200 GPU。
- 输入图像尺寸调整为 256×448,深度图由 Metric3D 模型生成。
Card 06
评估与结果
评估与结果
- 在 NAVSIM v1 上,模型达到 PDMS 93.7 (使用best-of-N策略),超越所有现有方法;单次预测 PDMS 90.4。
- 在 NAVSIM v2 上,模型达到 EPDMS 88.8,较之前最佳结果提升 2.7 分,并在九个子指标中六项取得最佳。
- 消融实验证明了密集视觉监督(RGB和深度生成)对提升规划性能的贡献,以及结合 PDMS 奖励和图像探索奖励对策略优化的有效性。
- 定性分析显示,经过第二阶段强化学习训练后,模型能修正第一阶段模型出现的碰撞、危险接近行人或闯红灯等安全关键错误。