一眼看懂
封面预览
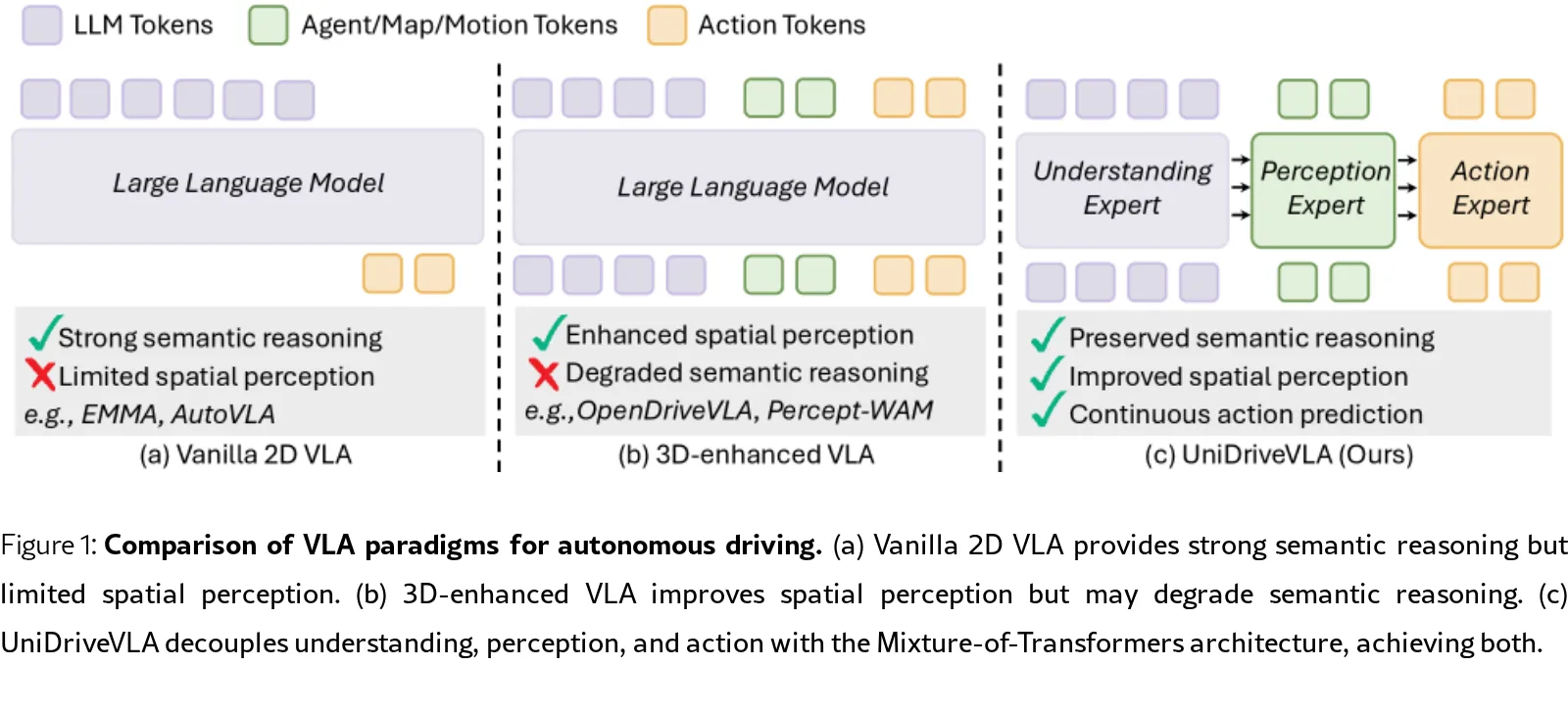
提出了 UniDriveVLA,一个基于混合专家架构的统一自动驾驶视觉-语言-动作(VLA)模型。
- 提出了 UniDriveVLA,一个基于混合专家架构的统一自动驾驶视觉-语言-动作(VLA)模型。
- 解决了现有 VLA 模型中空间感知与语义推理之间的优化冲突,现有方法往往在增强 3D 空间感知时牺牲了 VLM 的原生推理能力。
- 核心思想是通过 Mixture-of-Transformers 架构将驾驶理解、场景感知和动作规划任务解耦为三个独立的专家网络,避免参数空间内…
Card 01
研究单位
研究单位
- Huazhong University of Science and Technology
- Xiaomi EV
- SKL-IOTSC, University of Macau
Card 02
论文概述
论文概述
- 提出了 UniDriveVLA,一个基于混合专家架构的统一自动驾驶视觉-语言-动作(VLA)模型。
- 解决了现有 VLA 模型中空间感知与语义推理之间的优化冲突,现有方法往往在增强 3D 空间感知时牺牲了 VLM 的原生推理能力。
- 核心思想是通过 Mixture-of-Transformers 架构将驾驶理解、场景感知和动作规划任务解耦为三个独立的专家网络,避免参数空间内的特征干扰。
Card 03
核心贡献
核心贡献
- 提出了基于 Mixture-of-Transformers 的统一架构,通过专家解耦机制缓解了空间感知与语义推理之间的冲突。
- 引入了稀疏感知范式,直接从 2D VLM 特征中提取空间先验,并设计了三阶段渐进式训练策略,在提升感知能力的同时保留了模型的语义推理能力。
- 在 nuScenes 开环评估和 Bench2Drive 闭环评估中均取得了 SOTA 性能,并在 3D 检测、在线建图等多种任务上表现出广泛的适用性。
Card 04
方法描述
方法描述
- 模型架构包含三个专家模块:理解专家(负责语义推理)、感知专家(负责空间感知)、动作专家(负责轨迹规划)。
- 采用 Masked Joint Attention 机制控制专家间的信息流,理解专家保持因果掩码以保护 VLM 原生能力,感知和动作专家聚合语义与空间信息。
- 利用统一查询驱动机制从多视图图像特征中提取稀疏空间感知结果(检测、建图、运动预测等),避免了密集 BEV 表示带来的干扰。
- 实施三阶段训练策略:第一阶段锚定语义能力,第二阶段引入感知和规划监督,第三阶段冻结 VLM 并微调感知与动作专家。
Card 05
数据集与资源
数据集与资源
- 主要数据集包括 nuScenes(用于开环规划与感知评估)和 Bench2Drive(用于闭环驾驶评估)。
- 模型基于 Qwen3-VL 构建,提供了 UniDriveVLA-Base(Qwen3-VL-2B)和 UniDriveVLA-Large(Qwen3-VL-8B)两个版本。
- 输入图像尺寸调整为 960x544,训练过程中使用了 LoRA 技术和 EMA 策略。
Card 06
评估与结果
评估与结果
- 在 Bench2Drive 基准上,UniDriveVLA 在非 PDM-Lite 训练的方法中取得了最高的 Driving Score (78.37) 和最高的 Efficiency (198.86)。
- 在驾驶技能评估中,模型在 Merging (38.75%) 和 Overtaking (80.00%) 场景表现最佳,平均能力得分达到 51.53%。
- 在 nuScenes 开环规划任务中,UniDriveVLA-Large 在 ST-P3 协议下的平均碰撞率低至 0.10%,表现优于同类 VLA 方法。