一眼看懂
封面预览
研究目标:解决自回归视觉-语言-动作(VLA)模型中视觉信息利用效率低下的问题,提升机械臂操作的精准度和鲁棒性
- 研究目标:解决自回归视觉-语言-动作(VLA)模型中视觉信息利用效率低下的问题,提升机械臂操作的精准度和鲁棒性
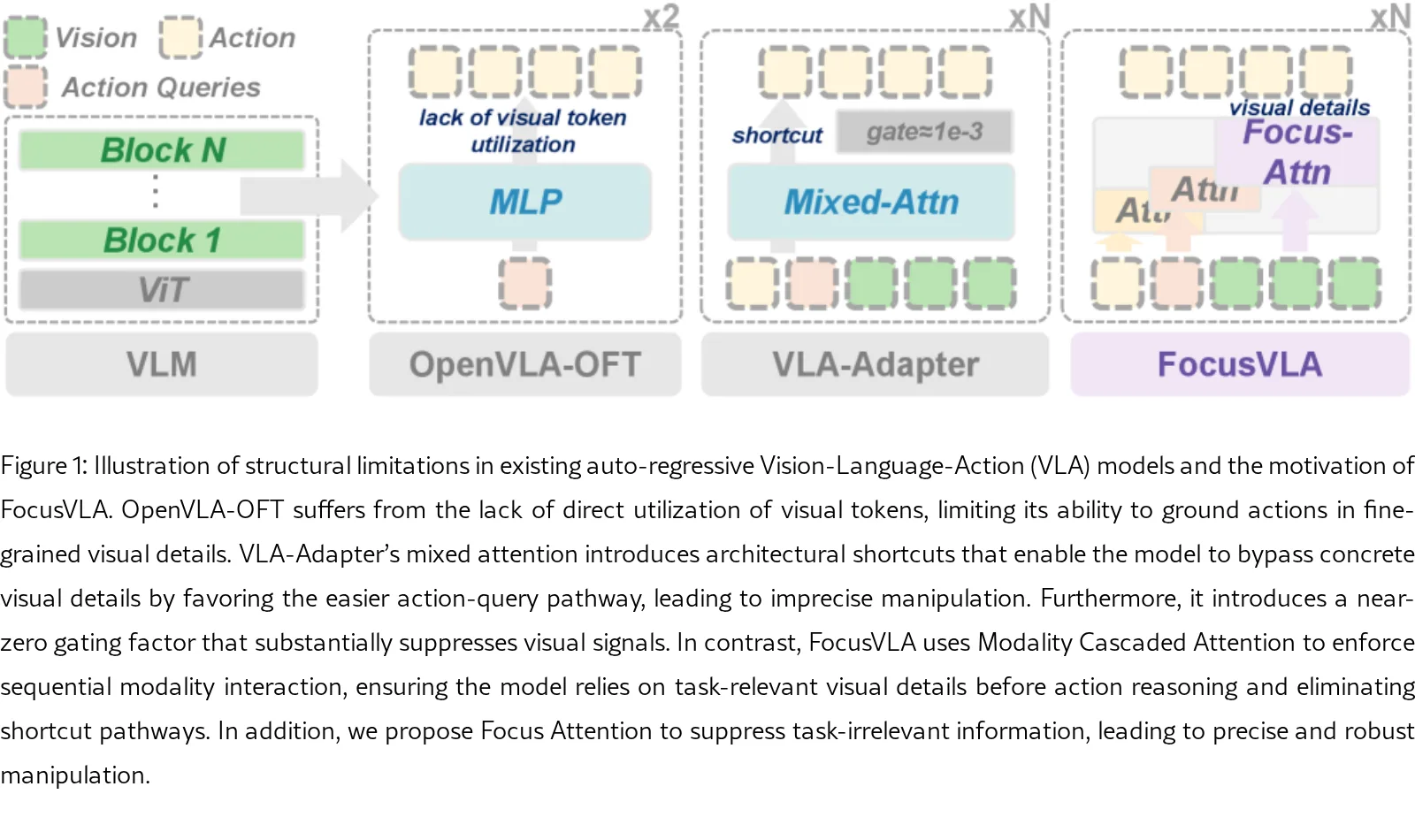
- 核心问题:识别出三个关键瓶颈——架构偏差(混合注意力产生结构捷径)、信息过载(过多视觉token稀释注意力)、任务无关噪声(背景信息降低信噪比)
- 解决思路:提出 FocusVLA 范式,通过引导模型关注任务相关的视觉区域,同时抑制无关干扰,从而实现更精确的动作生成
Card 01
研究单位
研究单位
- 哈尔滨工业大学(深圳) (Harbin Institute of Technology, Shenzhen, China)
- DaiMon Robotics, China
- 南京大学 (Nanjing University, Nanjing, China)
- 中国人民大学 (Renmin University of China, Beijing, China)
Card 02
论文概述
论文概述
- 研究目标:解决自回归视觉-语言-动作(VLA)模型中视觉信息利用效率低下的问题,提升机械臂操作的精准度和鲁棒性
- 核心问题:识别出三个关键瓶颈——架构偏差(混合注意力产生结构捷径)、信息过载(过多视觉token稀释注意力)、任务无关噪声(背景信息降低信噪比)
- 解决思路:提出 FocusVLA 范式,通过引导模型关注任务相关的视觉区域,同时抑制无关干扰,从而实现更精确的动作生成
Card 03
核心贡献
核心贡献
- 识别并验证了自回归策略中视觉利用的三个基础瓶颈,揭示性能主要受限于视觉信息的利用方式而非表示质量本身
- 提出 Modality Cascaded Attention(模态级联注意力):消除策略网络中的结构偏差,使动作能够独立检索任务相关的视觉信息,将注意力模式从分散转变为聚焦
- 提出 Focus Attention(聚焦注意力):双层机制,包括 Patch-level Focus(裁剪冗余视觉块)和 Channel-level Focus(抑制背景噪声),为精准操作提供更丰富、任务相关的视觉细节
- 在模拟和真实机器人基准上实现 state-of-the-art 性能,显著提升训练收敛速度(1.5× 整体加速,5× 在 LIBERO-Spatial 上)
Card 04
方法描述
方法描述
- Modality Cascaded Attention:将混合注意力替换为级联设计,使动作潜在向量依次整合各模态信息,而非在共享注意力分布中混合所有模态,从而消除结构捷径,强制模型关注任务相关区域
- Patch-level Focus:基于跨注意力分数选择 Top-K 任务相关视觉token,屏蔽其他token;同时使用浅层VLM特征($C^V_0$)作为值、深层特征($C^V_t$)作为键,提取细粒度空间细节
- Channel-level Focus:采用元素级门控(element-wise gate)替代单参数门控,自适应抑制噪声通道,增强模型的指令跟随能力
- 结合 VLM 语义感知与 DINOv2+SigLIP 空间保真度,创建互补协同效应
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO(4个子集:Spatial, Object, Goal, Long)、RoboTwin 2.0(Easy/Hard设置)
- 视觉骨干:DINOv2 + SigLIP(DS)、PrismaticVLM(Qwen2.5-0.5B)、VGGT
- 模型规模:策略模块 0.5B 参数,总可训练参数约 342.7M(VLM: 103.6M + Policy: 239.1M)
- 训练资源:4-8 张 NVIDIA A100 GPU,batch size 64,LIBERO 单任务训练 10k-80k 步,RoboTwin 训练 20k-100k 步
Card 06
评估与结果
评估与结果
- 评估基准:LIBERO(500次试验/任务)和 RoboTwin(100-300次试验/任务),真实机器人实验(Realman平台,25次试验/变体)
- 主要指标:Success Rate (SR%)
- 关键结果:
- LIBERO 多权重设置:平均成功率 98.7%,超越 7B 规模的 OpenVLA-OFT 和 Spatial Forcing
- LIBERO 单权重设置:平均成功率 97.0%,显著优于 VLA-Adapter(95.6%)和 EVO-1(94.8%)
- RoboTwin:在精细操作任务(如 Hugging Mug)显著优于基线模型
- 训练效率:平均 1.5× 加速,LIBERO-Spatial 上 5× 加速(5k vs 25k 步)
- 真实机器人实验:在抓取、叠杯、放置任务中均取得更高成功率,展示对背景变化、空间变化和目标变化的有效泛化