一眼看懂
封面预览
提出 CLaD 框架,通过跨模态潜在动态模型学习本体感知和语义状态在动作下的共同演变
- 提出 CLaD 框架,通过跨模态潜在动态模型学习本体感知和语义状态在动作下的共同演变
- 解决现有规划方法未明确对齐跨模态过渡导致的轨迹物理或逻辑不一致问题
- 预测接地潜在远见并用于条件化扩散策略,实现高效机器人操作规划
Card 01
研究单位
研究单位
- KAIST(韩国科学技术院)
Card 02
论文概述
论文概述
- 提出 CLaD 框架,通过跨模态潜在动态模型学习本体感知和语义状态在动作下的共同演变
- 解决现有规划方法未明确对齐跨模态过渡导致的轨迹物理或逻辑不一致问题
- 预测接地潜在远见并用于条件化扩散策略,实现高效机器人操作规划
Card 03
核心贡献
核心贡献
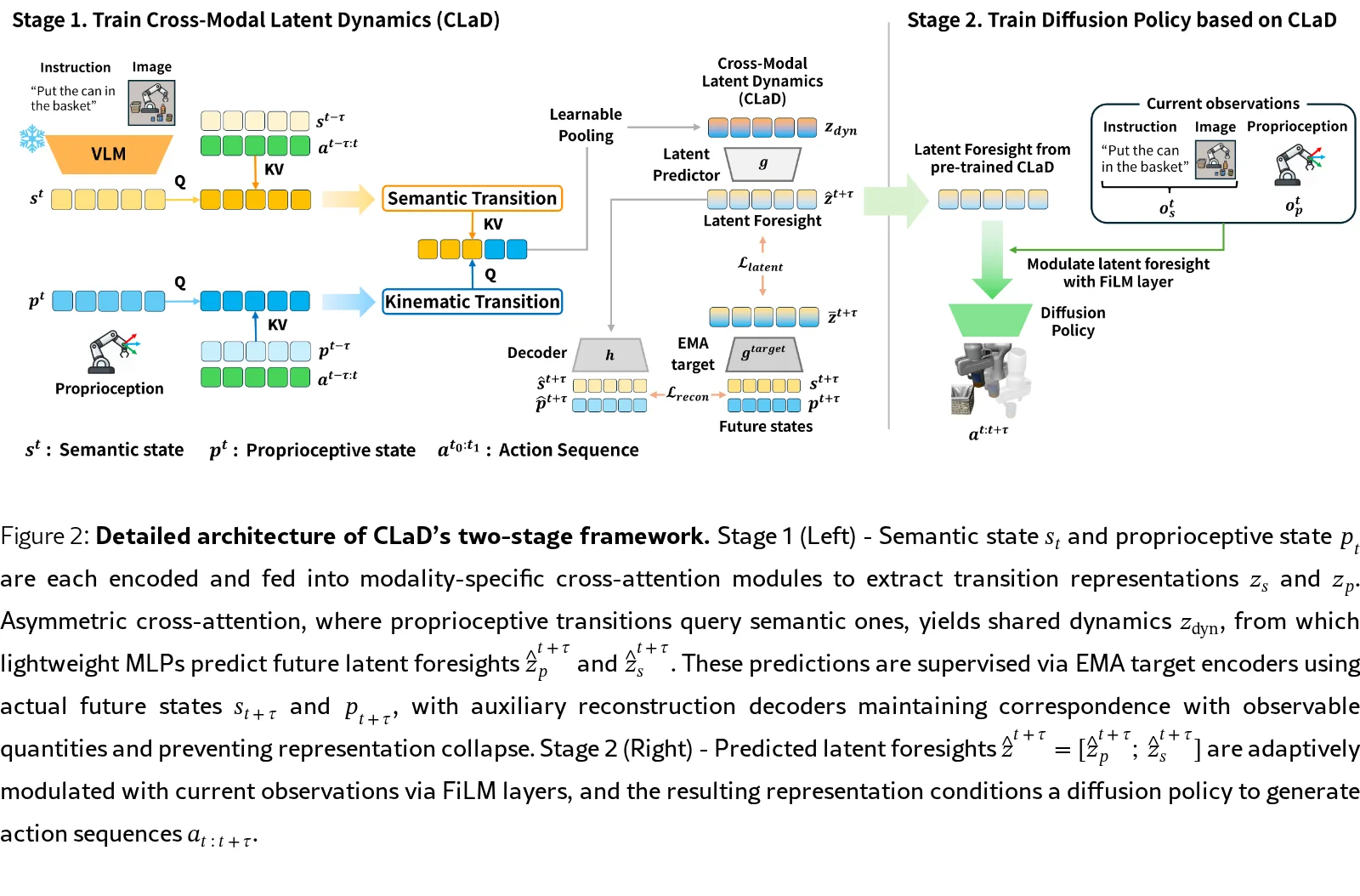
- 提出跨模态潜在动态模型,通过不对称交叉注意力学习运动与语义过渡的关联
- 引入接地潜在远见的两阶段训练框架,使用EMA目标编码器和辅助重建损失防止表示坍塌
- 实现参数高效规划,仅用0.66B参数达到与7B VLA模型竞争的性能
- 在LIBERO-LONG基准达到94.7%成功率,超越同规模方法
- 验证跨模态动态建模对解决感知歧义的关键作用
Card 04
方法描述
方法描述
- 采用两阶段框架:第一阶段学习跨模态动态和潜在远见,第二阶段训练扩散策略
- 使用不对称交叉注意力,让本体感知过渡作为查询查询语义过渡
- 通过过渡嵌入压缩状态和动作序列为紧凑表示
- 使用自监督目标:EMA目标编码器的潜在预测损失+辅助重建损失
- 通过FiLM调制将潜在远见与当前观察结合,条件化扩散策略生成动作序列
- 关键创新:过渡级跨模态建模而非静态状态对齐
Card 05
数据集与资源
数据集与资源
- 使用LIBERO-LONG基准,包含10个需要2-3子任务的长期操作任务
- 总模型参数:0.66B(VLM: 0.1B,CLaD: 0.33B,策略: 0.23B)
- 使用DecisionNCE作为冻结的预训练VLM
- 训练硬件:NVIDIA RTX 4090 GPU
- 第一阶段训练:25K步,批大小128,约2小时
- 第二阶段训练:200K步,批大小128,约20小时
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO-LONG基准的10个长期操作任务
- 主要指标:平均成功率(Avg. SR)
- 关键结果:达到94.7%平均成功率,超越OpenVLA(7B, 93.8%)和π₀.₅(3.3B, 93.2%)
- 计算效率:推理频率25Hz,内存占用4GB,规划延迟0.012秒
- 消融实验验证:跨模态远见优于单模态(语义单独91.5%,本体感知单独50.4%),重建损失防止8.6%性能下降,本体查询语义的注意力配置最优