一眼看懂
封面预览
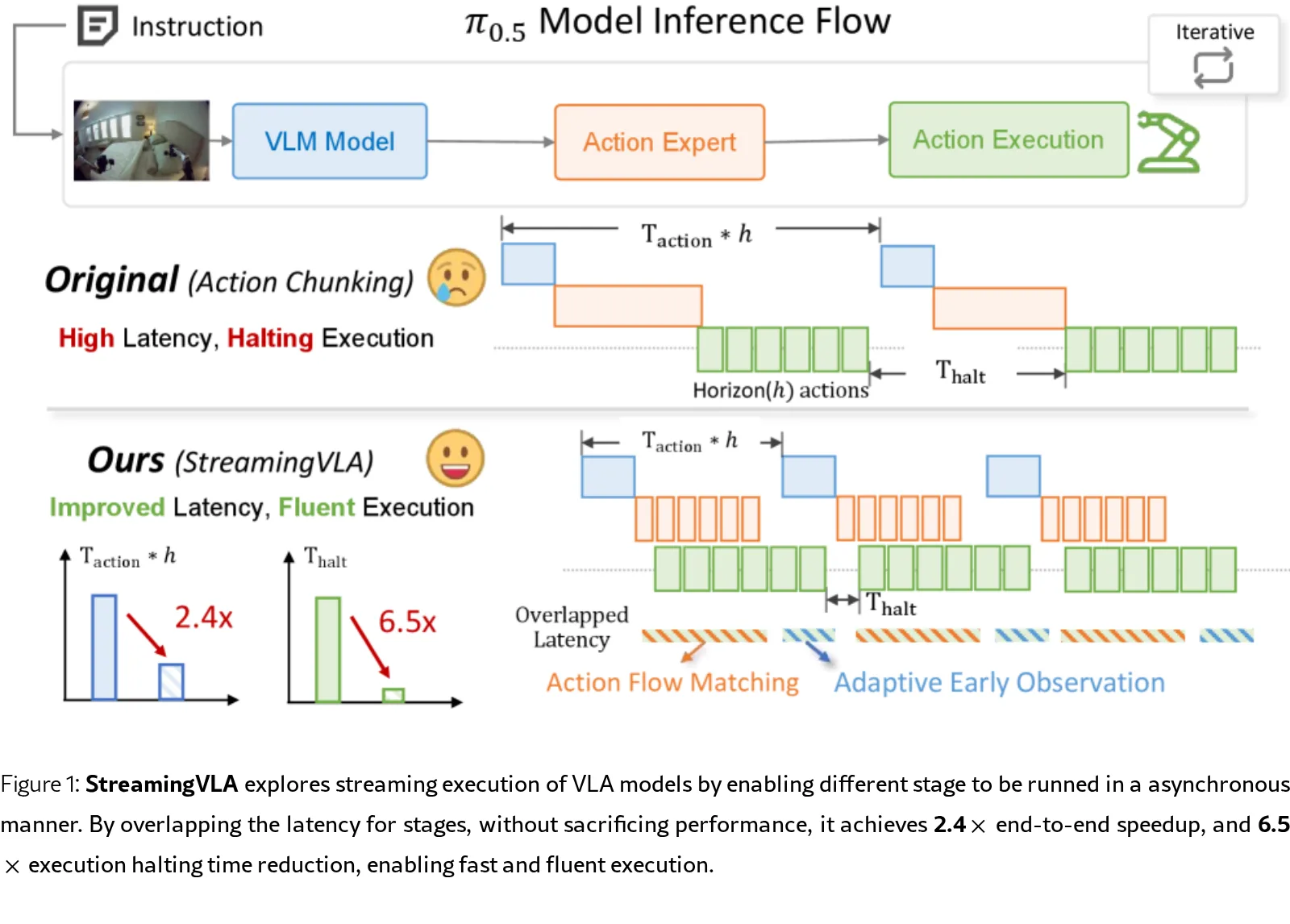
论文针对 Vision-Language-Action (VLA) 模型在真实部署中因顺序执行(观察、生成、执行)导致的高延迟和执行卡顿问题…
- 论文针对 Vision-Language-Action (VLA) 模型在真实部署中因顺序执行(观察、生成、执行)导致的高延迟和执行卡顿问题…
- 该框架旨在通过“流式”方式实现各阶段的异步并行化,以重叠不同阶段的延迟,从而在不牺牲性能的前提下实现快速、流畅的机器人控制。
- 核心目标是通过优化运行时流水线,显著降低每个动作的延迟($T_{action}$)和系统停顿时间($T_{halt}$)。
Card 01
研究单位
研究单位
- Tsinghua University
- Lenovo Group Ltd.
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在真实部署中因顺序执行(观察、生成、执行)导致的高延迟和执行卡顿问题,提出了 StreamingVLA 框架。
- 该框架旨在通过“流式”方式实现各阶段的异步并行化,以重叠不同阶段的延迟,从而在不牺牲性能的前提下实现快速、流畅的机器人控制。
- 核心目标是通过优化运行时流水线,显著降低每个动作的延迟($T_{action}$)和系统停顿时间($T_{halt}$)。
Card 03
核心贡献
核心贡献
- 对 VLA 模型的推理和执行过程进行了系统的运行时分析,明确了实现快速流畅执行的具体优化目标。
- 提出了 State-based Action Flow Matching 技术,通过学习动作轨迹流代替传统的去噪块生成,消除了对 Action Chunking 的依赖,实现了动作生成与执行的并行化。
- 设计了 Action Saliency-aware Adaptive Early Observation 机制,利用轻量级预测器识别高显著性动作,自适应地调整观察时机,实现了观察处理与动作执行的并行化。
- 在保持任务成功率几乎不变的情况下,实现了 2.4倍 的端到端加速和 6.5倍 的执行停顿减少。
Card 04
方法描述
方法描述
- State-based Modeling of Action Flow Matching: 将动作建模从预测噪声映射的绝对值转变为预测基于历史动作的特征状态更新。引入“动作空间状态”概念并修改归一化层(去除偏移项),解决了主流基准中复杂控制器的非线性问题和大规模 VLA 训练中的可加性破坏问题。
- Adaptive Early Observation: 提出动作显著性概念,描述动作对后续观察的影响程度。通过训练一个轻量级 Transformer 预测器来估计执行剩余动作后的特征空间变化,采用阈值策略避免在高显著性动作期间进行早期观察,从而在重叠执行与观察延迟的同时保证性能。
Card 05
数据集与资源
数据集与资源
- 仿真环境:LIBERO 基准,包含 Spatial、Object、Goal、Long 四个任务套件。
- 真实世界环境:包含桌面工作空间和 Franka Panda 机械臂的真实机器人平台。
- 基础模型:基于 $\pi_{0.5}$-Libero 模型架构进行改进。
- 训练资源:使用 4 张 NVIDIA A800-SXM4-80GB GPU。
- 训练时长:模型训练约 10-20 GPU 小时,预测器训练约 54,000 次迭代。
Card 06
评估与结果
评估与结果
- 评估指标:成功率、每个动作的耗时 ($T_{action}$)、停顿间隙 ($T_{halt}$)。
- 仿真结果:StreamingVLA 平均成功率达到 94.9%(对比原始基线 95.1%,性能损失小于 0.5%);$T_{action}$ 从 74.5ms 降低至 31.6ms;$T_{halt}$ 从 232.3ms 大幅降低至 36.0ms。
- 真实世界结果:在真实机器人抓取放置任务中,平均动作延迟从 271.49ms 降低至 170.88ms,验证了其实际部署的高效性。
- 对比实验:相比 RTC、SmolVLA、VLASH 等基线方法,StreamingVLA 在速度与性能的权衡上表现更优,有效解决了早期观察导致的性能下降问题。