一眼看懂
封面预览
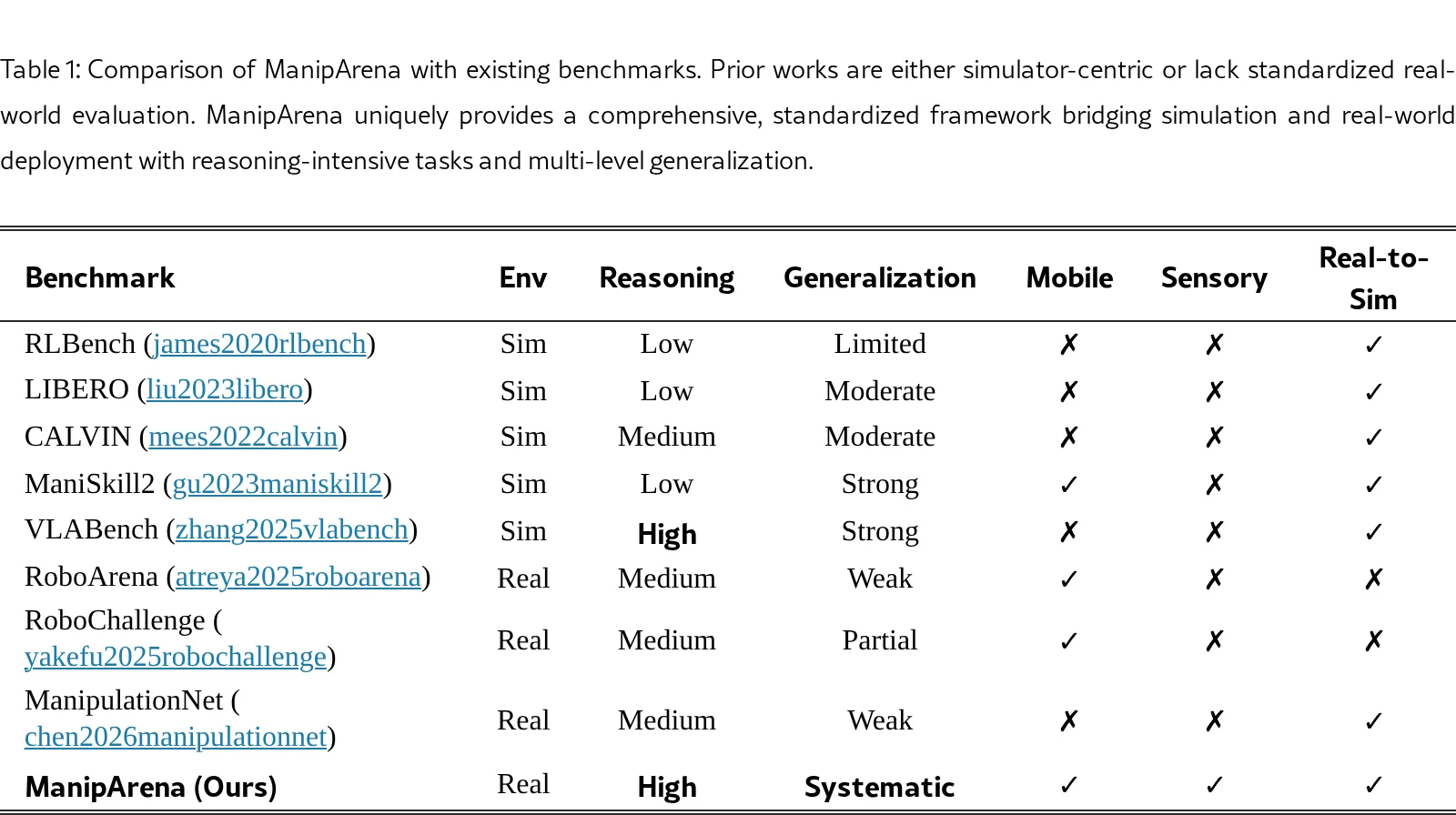
论文提出了 ManipArena,一个标准化的真实世界评估框架,旨在弥合模拟与真实执行之间的差距。
- 论文提出了 ManipArena,一个标准化的真实世界评估框架,旨在弥合模拟与真实执行之间的差距。
- 该框架针对 视觉-语言-动作 (VLA) 模型 和 世界模型 的评估瓶颈,解决了现有基准以模拟器为中心、缺乏可复现真实世界评估的问题。
- ManipArena 包含20个多样化任务、10,812条专家轨迹,强调需要语义和空间推理的推理导向型操作任务,并支持多级泛化和长期视野的移动…
Card 01
研究单位
研究单位
- SYSU
- X SQUARE ROBOT
- MBZUAI
- Tsinghua University
Card 02
论文概述
论文概述
- 论文提出了 ManipArena,一个标准化的真实世界评估框架,旨在弥合模拟与真实执行之间的差距。
- 该框架针对 视觉-语言-动作 (VLA) 模型 和 世界模型 的评估瓶颈,解决了现有基准以模拟器为中心、缺乏可复现真实世界评估的问题。
- ManipArena 包含20个多样化任务、10,812条专家轨迹,强调需要语义和空间推理的推理导向型操作任务,并支持多级泛化和长期视野的移动操作。
Card 03
核心贡献
核心贡献
- 提出了 ManipArena 基准框架,包含 20个任务,覆盖执行推理、语义推理和移动操作三大类别。
- 设计了 “一模型应对所有任务” 的评估协议,强制测试模型的通用推理和泛化能力而非特定任务过拟合。
- 构建了 受控评估环境(绿幕封闭空间),通过固定照明和背景,实现可归因、可复现的泛化测量。
- 提供了 丰富的感官诊断数据,包括56维状态和动作向量,涵盖关节电流和速度等低级信号。
- 创建了 Real-to-Sim (Real2Sim) 同步环境,通过3D扫描和高保真物理模拟,实现跨域的精确诊断和可扩展评估。
Card 04
方法描述
方法描述
- 采用 服务器端推理 架构,参与者通过HTTP端点暴露模型,主办方统一处理机器人控制、数据收集和评分。
- 任务设计分为执行推理(挑战在于“如何执行”)、语义推理(挑战在于“做什么”)和移动操作(长视野导航与操作)三类。
- 通过 分层OOD评估设计,将10次试验分为域内、视觉偏移和语义OOD三个难度级别,以测量泛化曲线。
- 使用 X2Robot 双手系统 作为统一机器人平台,消除具体差异,使性能差异反映策略能力。
Card 05
数据集与资源
数据集与资源
- 使用了自建的 ManipArena 数据集,包含 10,812条遥操作轨迹(约188小时),覆盖20个任务。
- 数据以 LeRobot v2.1 格式 发布,包含三路同步视频流(640×480,20fps)和56/62维本体感受状态。
- 提供了 Real2Sim仿真环境,基于IsaacLab构建,使用3D Gaussian Splatting重建场景和Hunyuan3D生成物体。
Card 06
评估与结果
评估与结果
- 在 15个桌面任务 上评估了三种基线模型:π₀.₅-Single、π₀.₅-OneModel 和 DreamZero。
- 主要评估指标为 任务总分(0-100) 和 成功率(SR),采用部分得分机制以提供细粒度诊断。
- 关键结果:基准远未饱和,最佳总分仅为 640.5/1500(42.7%);无单一模型主导,不同模型在不同任务上各有优势。
- 多任务训练带来权衡:提升了语义识别能力,但牺牲了任务特定的程序性知识记忆。