一眼看懂
封面预览
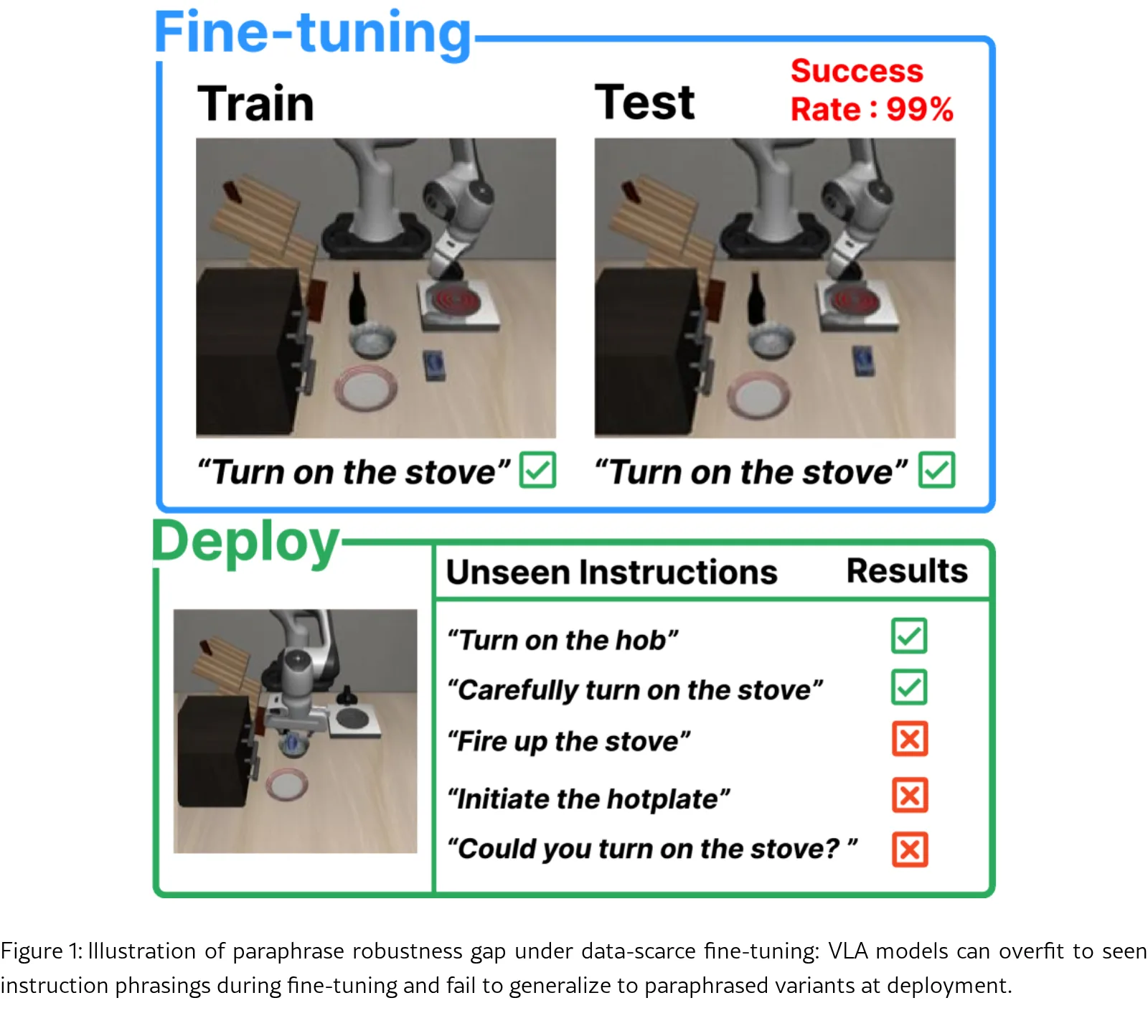
论文研究视觉语言行动(VLA)模型在处理改写指令时的鲁棒性,发现模型在少量数据微调后易过度拟合特定指令表述,对改写指令泛化能力不足。
- 论文研究视觉语言行动(VLA)模型在处理改写指令时的鲁棒性,发现模型在少量数据微调后易过度拟合特定指令表述,对改写指令泛化能力不足。
- 论文提出 LIBERO-Para 基准测试和 PRIDE 指标,用于诊断和量化VLA模型对改写指令的鲁棒性。
- 论文揭示了VLA模型普遍存在的改写脆弱性,并分析了性能下降的根本原因。
Card 01
研究单位
研究单位
- Soongsil University(首尔大学)
- Chung-Ang University(中央大学)
Card 02
论文概述
论文概述
- 论文研究视觉语言行动(VLA)模型在处理改写指令时的鲁棒性,发现模型在少量数据微调后易过度拟合特定指令表述,对改写指令泛化能力不足。
- 论文提出 LIBERO-Para 基准测试和 PRIDE 指标,用于诊断和量化VLA模型对改写指令的鲁棒性。
- 论文揭示了VLA模型普遍存在的改写脆弱性,并分析了性能下降的根本原因。
Card 03
核心贡献
核心贡献
- 提出 LIBERO-Para,一个受控的基准测试,独立地改变指令中的动作表达和对象引用,实现细粒度的语言泛化分析。
- 提出 PRIDE(Paraphrase Robustness Index in Robotic Instructional DEviation)指标,结合关键词相似性和结构相似性,量化改写难度并补足二元成功指标的不足。
- 揭示三个关键发现:改写脆弱性在多种架构和训练策略中普遍存在;对象层词汇变化是性能下降的主要瓶颈;大部分失败源于规划层面的轨迹偏离,而非执行错误。
Card 04
方法描述
方法描述
- LIBERO-Para 基于机器人操作指令的语言结构(动作动词和对象引用),采用双轴设计,独立地引入变化。
- 改写类型基于 Extended Paraphrase Typology 和 Directive Types 等语言学分类学,共定义了43种细粒度变化类型。
- PRIDE 指标通过关键词相似度($S_K$,基于内容词的语义匹配)和结构相似度($S_T$,基于依存树的编辑距离)计算改写距离,并与任务成功情况结合。
Card 05
数据集与资源
数据集与资源
- 基于 LIBERO 基准(特别是 LIBERO-Goal 设置)构建改写指令,保持其他因素不变,仅改写文本指令。
- 生成总计 4,092 条改写指令,每种变化类型约100个样本。
- 评估了 7 种VLA模型配置,参数规模从 0.6B 到 7.5B,涵盖四种架构家族。
Card 06
评估与结果
评估与结果
- 在 LIBERO-Para 基准上,所有VLA模型在改写指令下的成功率均下降 22–52 个百分点,表明脆弱性普遍存在。
- PRIDE 指标进一步揭示,部分模型的成功主要来自容易的改写,对困难改写系统性失败,显示出性能被高估。
- 分析表明,对象层词汇变化(如简单同义词替换)是性能下降的主要驱动因素,且 80–96% 的失败源于规划层面的轨迹偏离(Far-GT),而非执行错误。