一眼看懂
封面预览
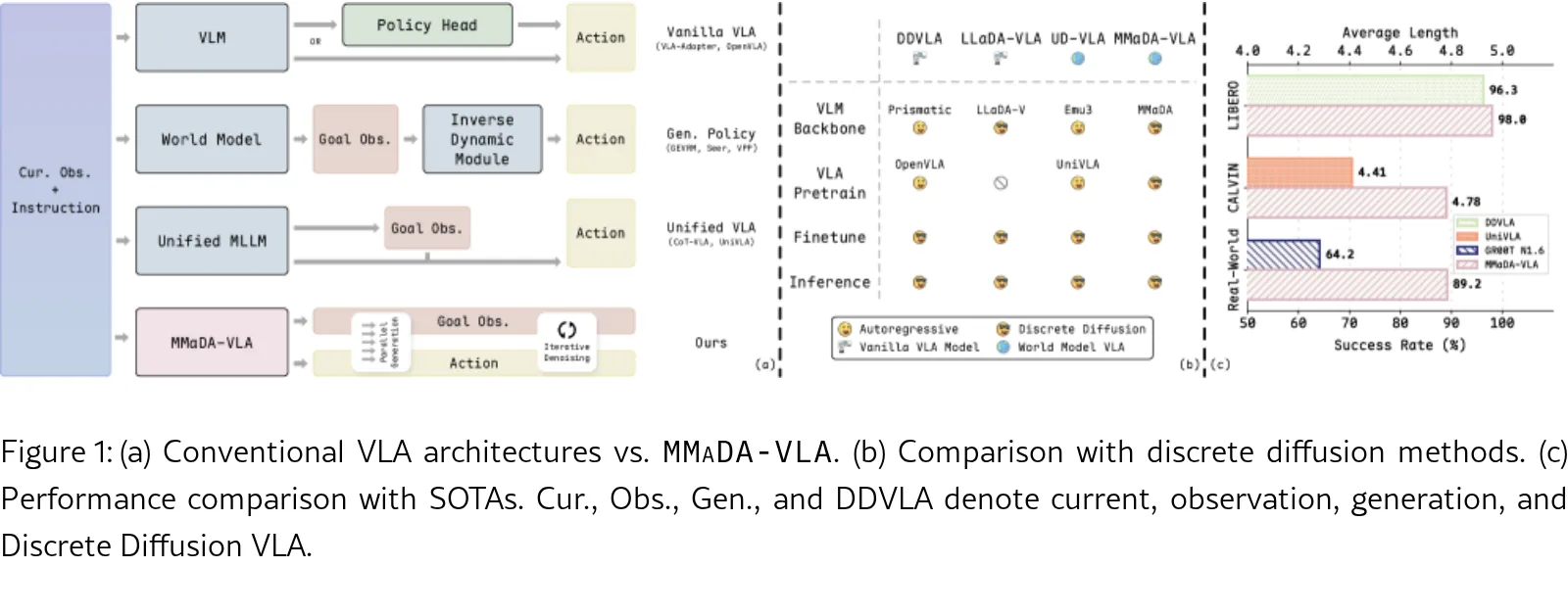
提出了 MMaDA-VLA,一个原生预训练的大型扩散视觉-语言-动作模型,旨在统一多模态理解和生成。
- 提出了 MMaDA-VLA,一个原生预训练的大型扩散视觉-语言-动作模型,旨在统一多模态理解和生成。
- 解决了现有分层或自回归 VLA 模型存在的架构冗余、时间不一致性、长序列误差累积以及缺乏环境动力学建模能力等问题。
- 通过原生离散扩散公式,在一个离散 Token 空间中联合生成未来目标观测和动作块,无需额外的世界模型模块。
Card 01
研究单位
研究单位
- Westlake University
- Zhejiang University
- East China University of Science and Technology
- Huawei Celia Team
- The Hong Kong University of Science and Technology (Guangzhou)
- OpenHelix Robotics
Card 02
论文概述
论文概述
- 提出了 MMaDA-VLA,一个原生预训练的大型扩散视觉-语言-动作模型,旨在统一多模态理解和生成。
- 解决了现有分层或自回归 VLA 模型存在的架构冗余、时间不一致性、长序列误差累积以及缺乏环境动力学建模能力等问题。
- 通过原生离散扩散公式,在一个离散 Token 空间中联合生成未来目标观测和动作块,无需额外的世界模型模块。
Card 03
核心贡献
核心贡献
- 提出了一种新颖的原生离散扩散 VLA 架构,将语言、图像和连续机器人动作统一映射到共享的离散 Token 空间。
- 设计了混合注意力机制,结合模态内的双向全注意力和模态间的因果注意力,以增强特征解耦和动作预测的稳定性。
- 引入了基于置信度重掩码的迭代去噪推理策略,支持动作块的并行解码以减少误差累积,并利用 Key-Value Cache 优化推理效率。
- 在仿真基准和真实世界任务中实现了最先进的性能,验证了模型在多任务和长序列操作中的有效性。
Card 04
方法描述
方法描述
- 使用 LLaDA 文本分词器、MAGVIT-v2 图像量化器以及动作离散化策略,将所有模态输入转换为离散 Token 序列。
- 模型骨干基于单一 Transformer 架构,通过掩码 Token 预测目标进行训练,联合预测未来的目标图像和动作序列。
- 采用混合注意力机制:模态内使用双向全注意力以捕捉全局依赖,模态间使用因果注意力以确保信息流的定向性。
- 推理阶段通过迭代去噪过程逐步恢复被掩码的 Token,并使用 Key-Value Cache 缓存指令部分的中间表示以加速生成。
Card 05
数据集与资源
数据集与资源
- 预训练数据集:包含 DROID, BC-Z, Bridge V2, Language Table 等 28 个大规模跨具身机器人操作数据集,总计约 6100 万步训练数据。
- 评估基准:LIBERO 仿真基准和 CALVIN 仿真基准(ABC→D 设置)。
- 模型骨干:MMaDA-8B-Base。
- 训练资源:使用 8 个 Nvidia H800 GPU 节点,预训练耗时约 30 小时。
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 多任务基准、CALVIN 长序列基准以及真实世界机器人操作任务。
- 评估指标:任务成功率(%)和平均完成长度。
- 在 LIBERO 基准上达到 98.0% 的平均成功率,超越了 OpenVLA 和 VLA-Adapter 等现有方法。
- 在 CALVIN 基准(ABC→D)上实现了 4.78 的平均完成长度,显著优于现有的离散和连续动作基线。
- 在真实世界机器人(AgileX Piper)实验中,该模型在抓取、堆叠和存储等任务上均表现出优异的成功率,优于 GR00T-N1 基线。