一眼看懂
封面预览
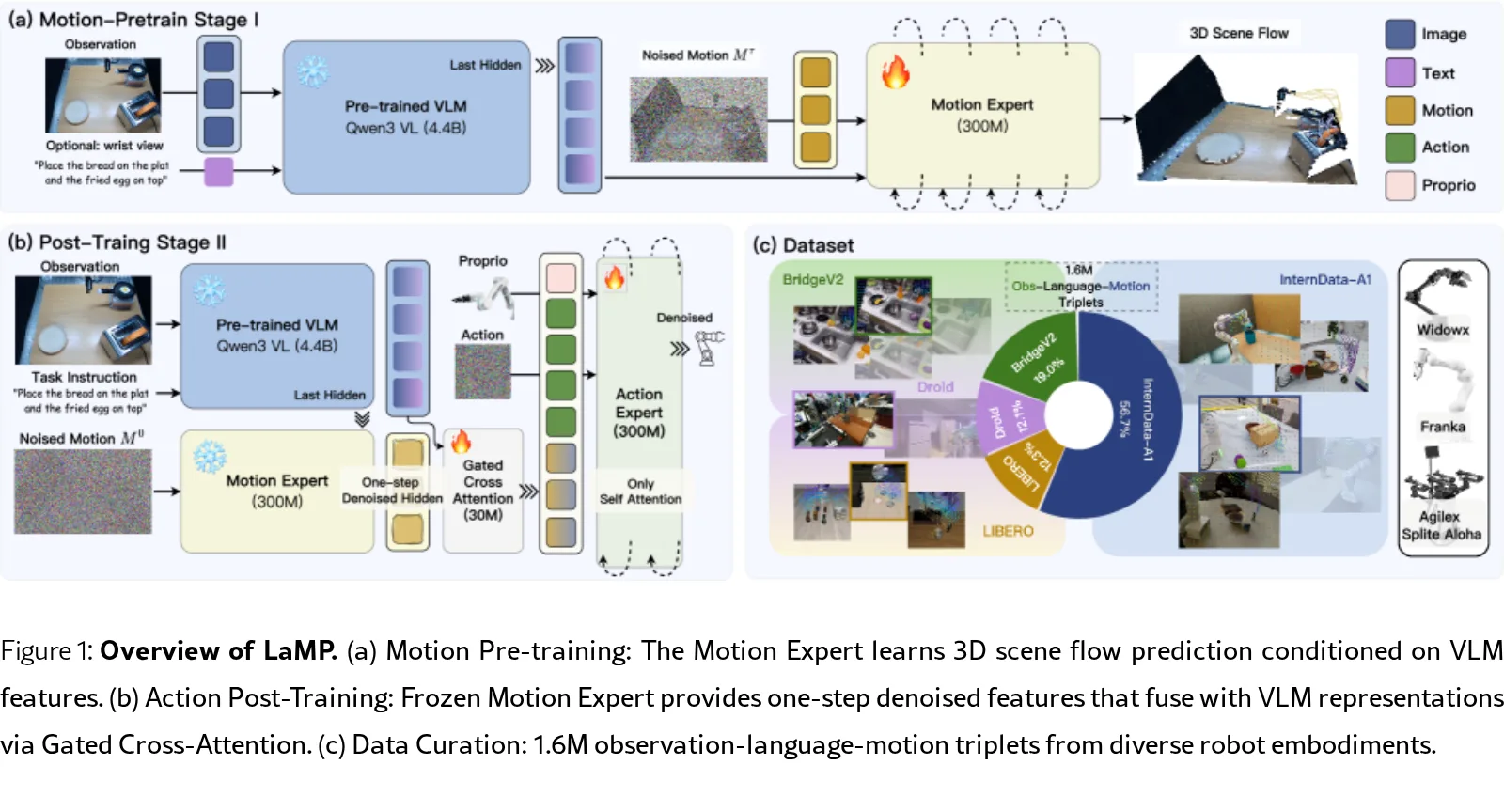
论文提出了LaMP,一个双专家的Vision-Language-Action (VLA) 框架,该框架将密集3D场景流作为潜在运动先验嵌入到机…
- 论文提出了LaMP,一个双专家的Vision-Language-Action (VLA) 框架,该框架将密集3D场景流作为潜在运动先验嵌入到机…
- 论文旨在解决现有VLA模型直接从2D语义视觉特征回归动作,导致必须隐式学习复杂3D物理交互,并在不熟悉空间动态下表现不佳的问题。
- LaMP通过门控交叉注意力将流匹配的Motion Expert与策略预测的Action Expert对齐,使用一步部分去噪的3D场景流作为条件…
Card 01
研究单位
研究单位
- 东南大学、上海交通大学人工智能学院、浙江大学、北京航空航天大学、上海创新研究院
Card 02
论文概述
论文概述
- 论文提出了LaMP,一个双专家的Vision-Language-Action (VLA) 框架,该框架将密集3D场景流作为潜在运动先验嵌入到机器人操作中。
- 论文旨在解决现有VLA模型直接从2D语义视觉特征回归动作,导致必须隐式学习复杂3D物理交互,并在不熟悉空间动态下表现不佳的问题。
- LaMP通过门控交叉注意力将流匹配的Motion Expert与策略预测的Action Expert对齐,使用一步部分去噪的3D场景流作为条件,避免了全多步重建的计算开销。
Card 03
核心贡献
核心贡献
- 提出了LaMP双专家VLA框架,利用密集3D场景流作为潜在运动先验,弥合了2D语义VLM特征与3D物理动态之间的差距。
- 引入了门控运动指导机制,通过门控交叉注意力提取部分去噪的运动状态并自适应地将几何线索注入VLM表示,防止表示坍塌并保持计算效率。
- 在LIBERO、LIBERO-Plus、SimplerEnv-WidowX基准测试及真实世界实验中,LaMP持续优于现有VLA基线,取得了最高的平均成功率。
Card 04
方法描述
方法描述
- LaMP框架包含两个核心专家:Motion Expert 采用条件流匹配学习预测3D场景流,作为隐式运动先验;Action Expert 基于运动指导和视觉语言特征预测机器人动作。
- 创新点在于使用一步部分去噪(从τ=0到τ=0.1)的中间隐藏状态作为运动指导特征,并通过门控交叉注意力机制与VLM特征融合,门控参数从零开始初始化,实现自适应的运动信息注入。
- 采用两阶段训练:阶段一预训练Motion Expert;阶段二冻结Motion Expert和VLM骨干,训练Action Expert和运动指导模块。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括LIBERO、BridgeV2、DROID、InternData-A1,通过TraceForge流程构建了160万 观测-语言-运动三元组。
- 模型基于Qwen3-VL-4B-Instruct作为骨干网络,Motion Expert采用CogVideoX风格的3D Transformer。
- 训练资源为16块 NVIDIA H100 GPU,推理在配备RTX 4090 GPU的工作站上进行。
Card 06
评估与结果
评估与结果
- 评估环境包括LIBERO(四个标准套件)、LIBERO-Plus(七个OOD扰动维度)和SimplerEnv-WidowX仿真基准,以及真实世界机器人平台。
- 主要评估指标为任务成功率 和 平均成功率。
- 关键结果:在LIBERO上平均成功率达98.3%,在LIBERO-Long上达96.7%;在LIBERO-Plus零样本OOD评估中平均成功率达79.3%,比最强基线高9.7%;在SimplerEnv-WidowX上平均成功率达79.2%;真实世界实验中在所有任务类别上都优于π₀ 和 3D FDP 基线。