一眼看懂
封面预览
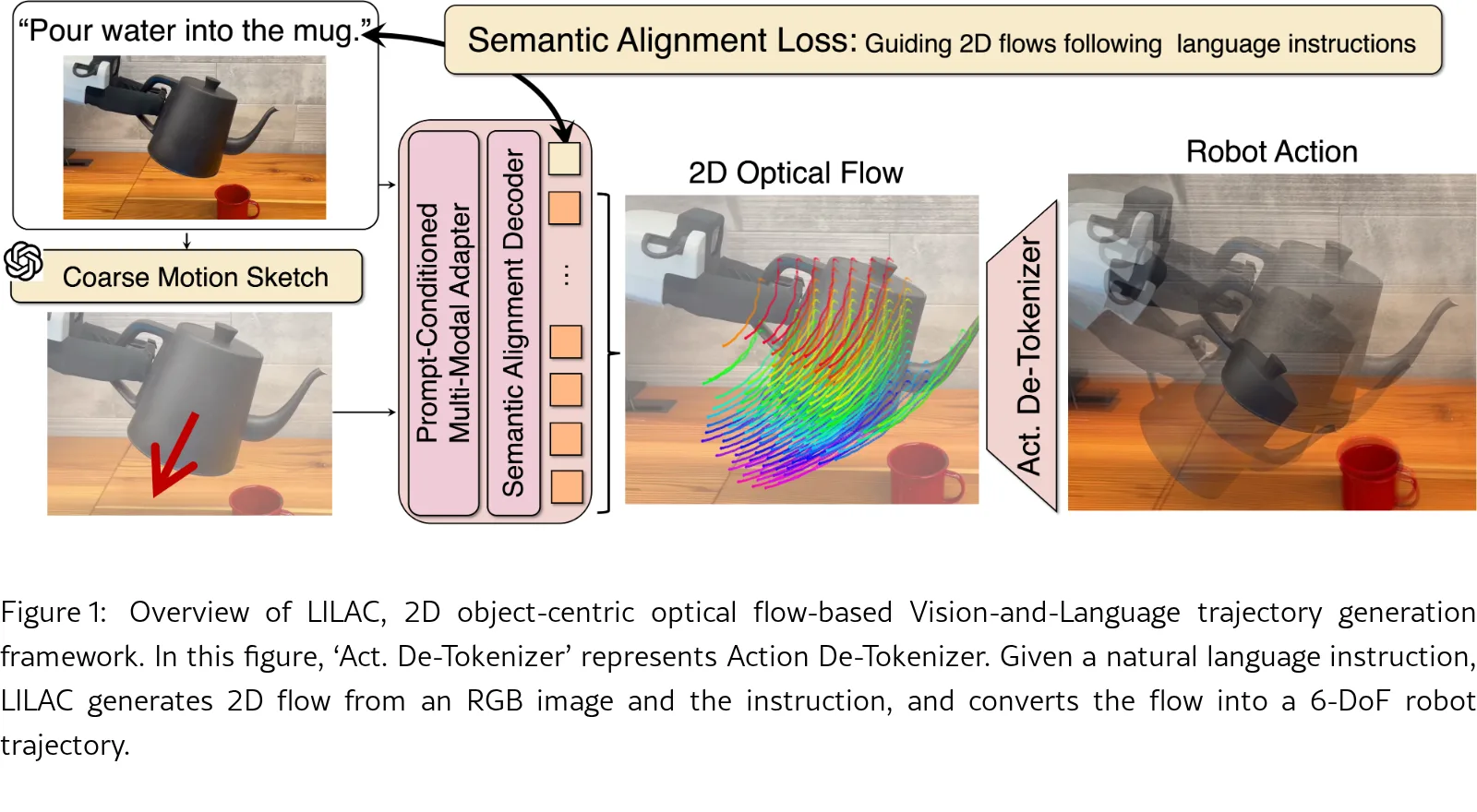
提出一种基于光流的语言条件机器人操作轨迹生成方法 LILAC,可利用人类和网络视频进行训练,仅需少量具身特定数据
- 提出一种基于光流的语言条件机器人操作轨迹生成方法 LILAC,可利用人类和网络视频进行训练,仅需少量具身特定数据
- 解决了从操作前图像和自然语言指令生成目标轨迹的问题,需要实现指令与光流的对齐
- 不同于现有闭环方法,LILAC 采用开环轨迹生成,在单次前向传播中生成整个操作轨迹,降低推理成本并避免误差累积
Card 01
研究单位
研究单位
- Keio University(庆应义塾大学)- 作者 Motonari Kambara, Koki Seno, Komei Sugiura
- KDDI Research Inc. - 作者 Tomoya Kaichi, Yanan Wang
Card 02
论文概述
论文概述
- 提出一种基于光流的语言条件机器人操作轨迹生成方法 LILAC,可利用人类和网络视频进行训练,仅需少量具身特定数据
- 解决了从操作前图像和自然语言指令生成目标轨迹的问题,需要实现指令与光流的对齐
- 不同于现有闭环方法,LILAC 采用开环轨迹生成,在单次前向传播中生成整个操作轨迹,降低推理成本并避免误差累积
Card 03
核心贡献
核心贡献
- 提出 LILAC 框架,从 RGB 图像和自然语言指令生成以目标为中心的 2D 光流,并将其转换为 6-DoF 机械臂轨迹
- 引入 Prompt-Conditioned Multi-Modal Adapter,整合图像、语言指令和视觉提示,实现任务自适应的光流生成
- 引入 Semantic Alignment Loss,明确鼓励模型学习语言指令的语义表示,提升指令与生成光流的对齐程度
Card 04
方法描述
方法描述
- 流生成模块:使用 MLLM(如 GPT-4o)生成视觉提示(箭头形式),通过跨模态适配器融合 RGB 图像、指令和视觉提示,生成 2D 光流序列
- 语义对齐解码器:基于 Transformer 解码器自回归生成光流,将最终 token 与语言特征对齐,确保光流编码基于语言指令的条件化运动表示
- 动作去分词器:两阶段将 2D 光流转换为 6-DoF 轨迹(粗粒度变换估计 + 细粒度 Transformer 细化)
- 损失函数:结合语义对齐损失( L1 损失)和流预测损失(交叉熵损失)
Card 05
数据集与资源
数据集与资源
- Robot Flow 基准:基于 Fractal 和 BridgeData V2 数据集构建
- Fractal 子集:23,866 训练 / 1,325 验证 / 1,325 测试
- BridgeData V2 子集:9,605 训练 / 533 验证 / 534 测试
- 物理实验平台:Toyota HSR 人 support 机器人
- 训练硬件:NVIDIA H200 GPU
- 视觉提示生成:GPT-4o / Qwen-2.5-VL
- 光流跟踪:CoTracker-3
Card 06
评估与结果
评估与结果
- 评估指标:Average Distance Error (ADE)、Precision@K (P@K)、Area Under Curve (AUC)
- 基准测试结果:在 Robot Flow 基准上,LILAC 相比最强基线 FLIP,在 Fractal 子集上 ADE 降低 17.43 点,AUC 提升 0.244;在 BridgeData V2 子集上 ADE 降低 12.51 点
- 物理实验结果:在 5 个操作任务(Mobile Replacing/Moving/Pouring/Tissue Picking/Drawer Opening)上,LILAC 平均成功率比最佳基线 FLIP 高 14 个百分点
- 推理速度:LILAC 推理速度约为 π0 的 1.4 倍