一眼看懂
封面预览
本文对最先进的视觉-语言-动作模型和新兴的世界动作模型进行了比较鲁棒性研究。
- 本文对最先进的视觉-语言-动作模型和新兴的世界动作模型进行了比较鲁棒性研究。
- 研究旨在探究WAMs是否因其显式的动态预测能力和从视频预训练中获得的时空先验,而比VLAs具有更好的泛化性能。
- 论文在 LIBERO-Plus 和自建的 RoboTwin 2.0-Plus 基准上,系统评估了多种视觉和语言扰动下两类模型的性能。
Card 01
研究单位
研究单位
- 华为技术有限公司
- 多伦多大学
Card 02
论文概述
论文概述
- 本文对最先进的视觉-语言-动作模型和新兴的世界动作模型进行了比较鲁棒性研究。
- 研究旨在探究WAMs是否因其显式的动态预测能力和从视频预训练中获得的时空先验,而比VLAs具有更好的泛化性能。
- 论文在 LIBERO-Plus 和自建的 RoboTwin 2.0-Plus 基准上,系统评估了多种视觉和语言扰动下两类模型的性能。
Card 03
核心贡献
核心贡献
- 提出了一个新的双臂机器人操作鲁棒性基准 RoboTwin 2.0-Plus,该基准遵循 LIBERO-Plus 的扰动协议。
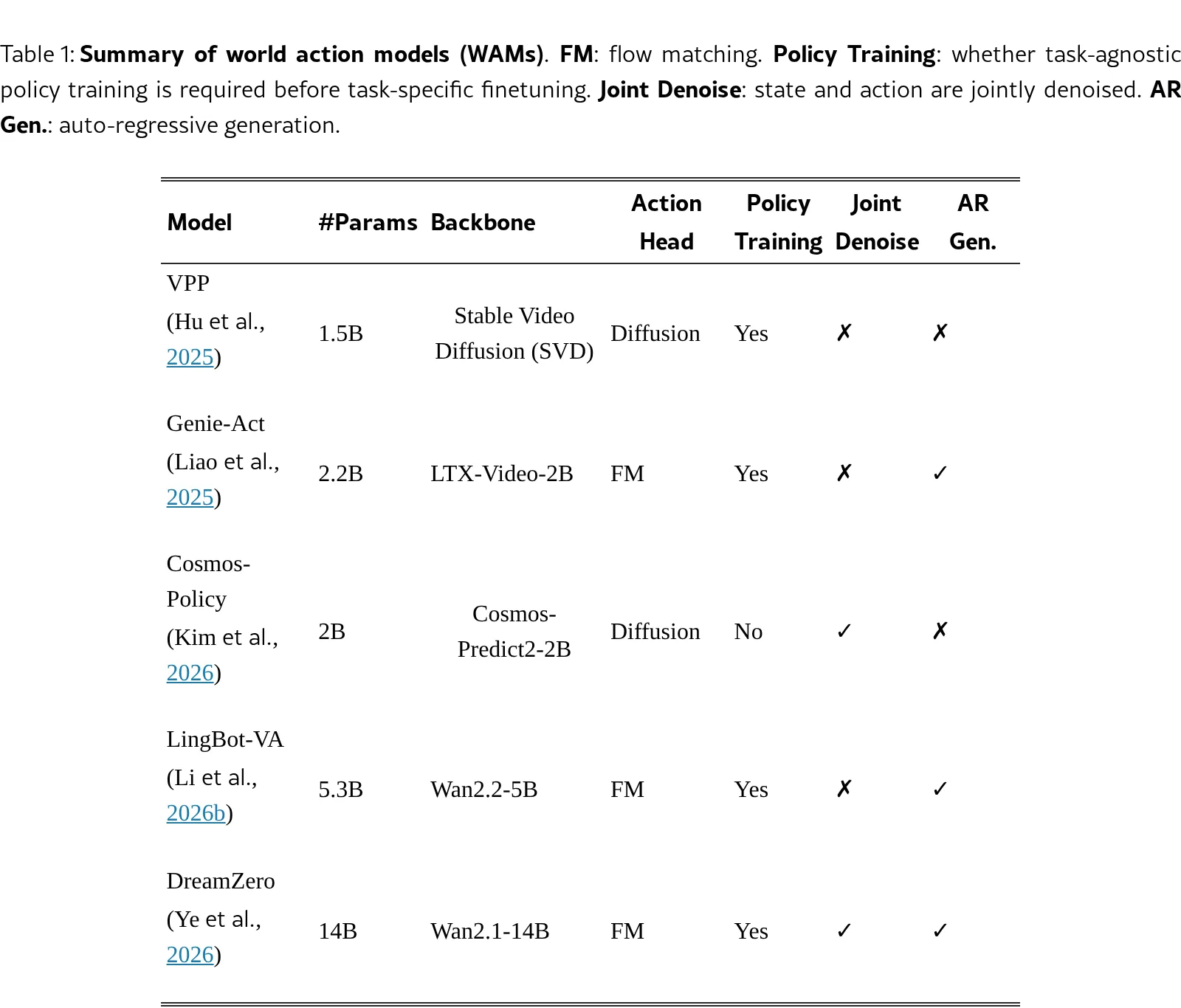
- 对代表性的VLAs(如 π₀.₅)和WAMs(如 LingBot-VA, Cosmos-Policy)进行了全面的性能比较。
- 揭示了WAMs通常对噪声、光照和布局等扰动具有更强的鲁棒性,同时指出VLAs(如 π₀.₅)在经过大量数据训练后可达到可比的鲁棒性。
- 分析了WAMs与VLAs在骨干模型、训练策略和预测方案上的核心差异,并指出WAMs的推理速度慢是其部署的主要挑战。
Card 04
方法描述
方法描述
- 论文通过系统性的实验进行对比研究,而非提出新的技术方法。
- 实验评估在两个不同设置的操作基准上进行:LIBERO-Plus(单臂Franka Panda机器人)和 RoboTwin 2.0-Plus(双臂Aloha-Agilex机器人)。
- 评估协议包括在原始环境上的成功率测试,以及施加七类扰动(相机、机器人初始状态、语言指令、光照、背景、传感器噪声、物体布局)后的性能测试。
Card 05
数据集与资源
数据集与资源
- 主要评估基准:LIBERO-Plus 和 RoboTwin 2.0-Plus。
- 评估模型包括:π₀, π₀.₅, OpenVLA-OFT, X-VLA, VLA-JEPA, MOTUS, GE-Act, Cosmos-Policy, LingBot-VA 等。
- 模型参数规模从 1.5B 到 14B 不等。
- 论文未明确说明评估所用的具体计算资源。
Card 06
评估与结果
评估与结果
- 评估在模拟环境中进行,主要指标为 任务成功率。
- 在 RoboTwin 2.0-Plus 上,WAM LingBot-VA 取得最佳总体成功率 74.2%,并在七类扰动中的五类上排名第一。
- 在 LIBERO-Plus 上,WAM Cosmos-Policy 取得最佳总体成功率 82.2%,而VLA π₀.₅ 也达到了 85.7% 的有竞争力表现。
- 结果表明WAMs通常具有更强的鲁棒性,其优势归因于从视频生成骨干中继承的时空先验;而VLA π₀.₅ 通过大规模多样化数据训练也能达到类似的鲁棒性。