一眼看懂
封面预览
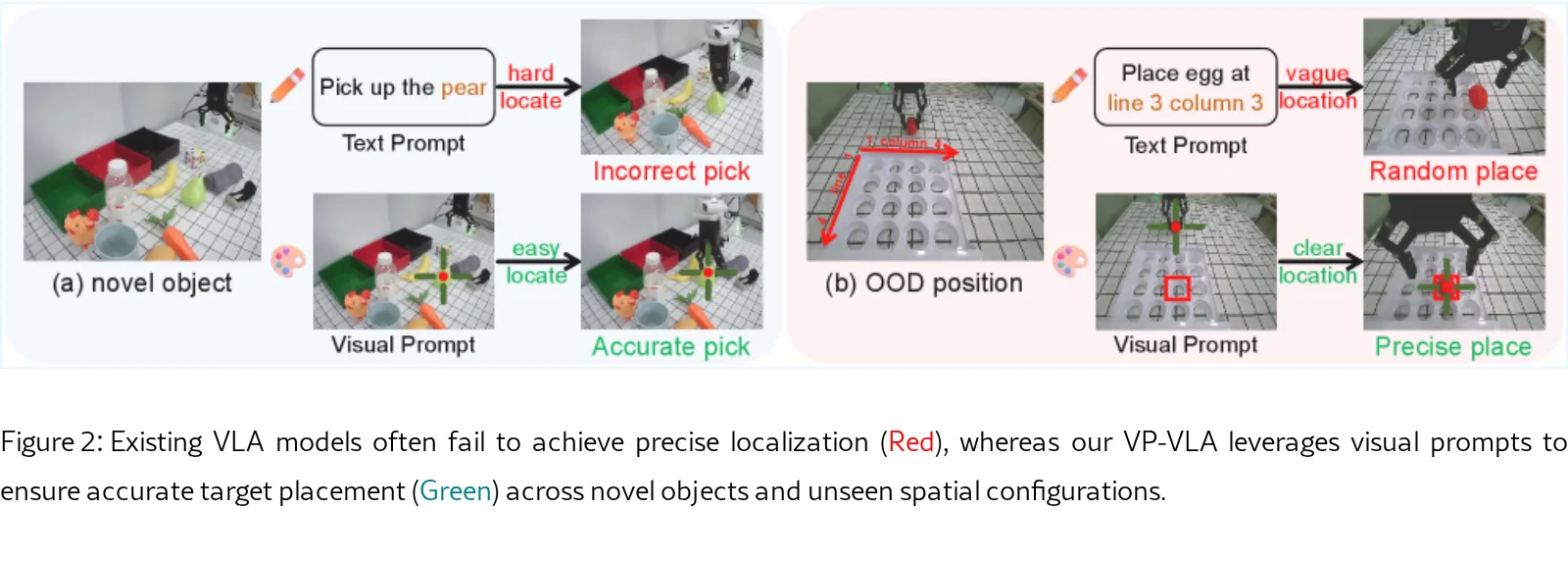
论文提出 VP-VLA,一种解耦的双系统视觉-语言-动作框架,旨在解决现有VLA模型在空间定位精度和分布外场景鲁棒性不足的问题。
- 论文提出 VP-VLA,一种解耦的双系统视觉-语言-动作框架,旨在解决现有VLA模型在空间定位精度和分布外场景鲁棒性不足的问题。
- 核心思想是利用结构化视觉提示作为接口,连接高层推理(系统2规划器)与底层执行(系统1控制器),将复杂语言指令转化为精确的空间锚点。
- 通过该框架,避免了端到端模型中指令解释、空间定位与运动控制耦合导致的性能瓶颈。
Card 01
研究单位
研究单位
- 香港科技大学 (HKUST)
- 香港中文大学 (CUHK)
- SmartMore
Card 02
论文概述
论文概述
- 论文提出 VP-VLA,一种解耦的双系统视觉-语言-动作框架,旨在解决现有VLA模型在空间定位精度和分布外场景鲁棒性不足的问题。
- 核心思想是利用结构化视觉提示作为接口,连接高层推理(系统2规划器)与底层执行(系统1控制器),将复杂语言指令转化为精确的空间锚点。
- 通过该框架,避免了端到端模型中指令解释、空间定位与运动控制耦合导致的性能瓶颈。
Card 03
核心贡献
核心贡献
- 提出一种新颖的双系统VLA框架,通过视觉提示接口解耦高层推理与底层控制。
- 引入一个视觉接地损失函数,在训练中显式增强模型对视觉提示的空间感知能力。
- 在仿真基准和真实世界场景中进行了广泛验证,证明了方法在空间精度和泛化能力上的一致性提升。
Card 04
方法描述
方法描述
- 系统2规划器:基于预训练VLM,采用事件驱动循环。当检测到机器人状态变化(如夹爪开合)时,分解当前子任务,识别目标物体与位置,并调用分割模型生成视觉提示(十字准星和边界框)。
- 系统1控制器:一个标准VLA模型,以原始观测、语言指令和叠加了视觉提示的图像为输入,生成动作序列。
- 训练目标:在关键帧上增加辅助视觉接地任务,要求VLM预测提示坐标,使用交叉熵损失,促使策略内化视觉提示的空间信息。
Card 05
数据集与资源
数据集与资源
- 仿真基准:Robocasa-GR1-Tabletop 数据集(24,000视频)和 SimplerEnv (BridgeDataV2, Fractal子集)。
- 真实世界数据:自建的垃圾分类、颜色拾取、鸡蛋盒放置任务数据集。
- 模型规模:基于 Qwen3-VL-4B-Instruct 架构。
- 训练资源:使用8个GPU进行训练。
Card 06
评估与结果
评估与结果
- 评估环境:Robocasa仿真(GR1机器人)、SimplerEnv仿真(WidowX机器人)、真实世界(Franka机器人)。
- 主要评估指标:任务成功率。
- 关键实验结果:
- 在 Robocasa-GR1-Tabletop 基准上,平均成功率相比基线QwenOFT提升5.0%(53.8% vs. 48.8%)。
- 在 SimplerEnv 基准上,平均成功率相比基线提升8.3%(58.3% vs. 50.0%),超越了π0.5和GR00T-N1.6等强基线。
- 在真实世界任务中,VP-VLA在分布内(ID)和分布外(OOD)场景下均显著优于基线,展现出更小的泛化差距(如垃圾分类任务OOD成功率85.0% vs. 63.3%)。