一眼看懂
封面预览
研究 Vision-Language-Action (VLA) 模型在持续学习中的灾难性遗忘问题,发现跨模态信息结构的退化是性能下降的根本原因
- 研究 Vision-Language-Action (VLA) 模型在持续学习中的灾难性遗忘问题,发现跨模态信息结构的退化是性能下降的根本原因
- 提出 Info-VLA 框架,通过两个互补约束保持跨模态信息结构:Replay Anchor Contrastive Learning 和 C…
- 在 LIBERO 基准上验证了方法的有效性,显著优于现有持续学习 baseline,在任务保留和适应效率上达到新 SOTA
Card 01
研究单位
研究单位
- Westlake University, China
- University of Southampton, UK
Card 02
论文概述
论文概述
- 研究 Vision-Language-Action (VLA) 模型在持续学习中的灾难性遗忘问题,发现跨模态信息结构的退化是性能下降的根本原因
- 提出 Info-VLA 框架,通过两个互补约束保持跨模态信息结构:Replay Anchor Contrastive Learning 和 Cross-Modal Mutual Information Maximization
- 在 LIBERO 基准上验证了方法的有效性,显著优于现有持续学习 baseline,在任务保留和适应效率上达到新 SOTA
Card 03
核心贡献
核心贡献
- 首次识别多模态依赖的结构扭曲是 VLA 持续学习中灾难性遗忘的根本原因
- 提出 Info-VLA 统一框架,结合重放锚点对比学习和互信息蒸馏来保持跨模态结构稳定性
- 设计了 Replay Anchor Contrastive (RAC) 模块,利用冻结教师模型提供稳定的表示锚点
- 设计了 Cross-Modal Mutual Information (CMI) 模块,显式保持视觉与语言表示间的统计依赖结构
- 在 LIBERO-Long 和 LIBERO-Goal 基准上建立新 SOTA,AA 指标分别达到 78.7% 和 73.3%
Card 04
方法描述
方法描述
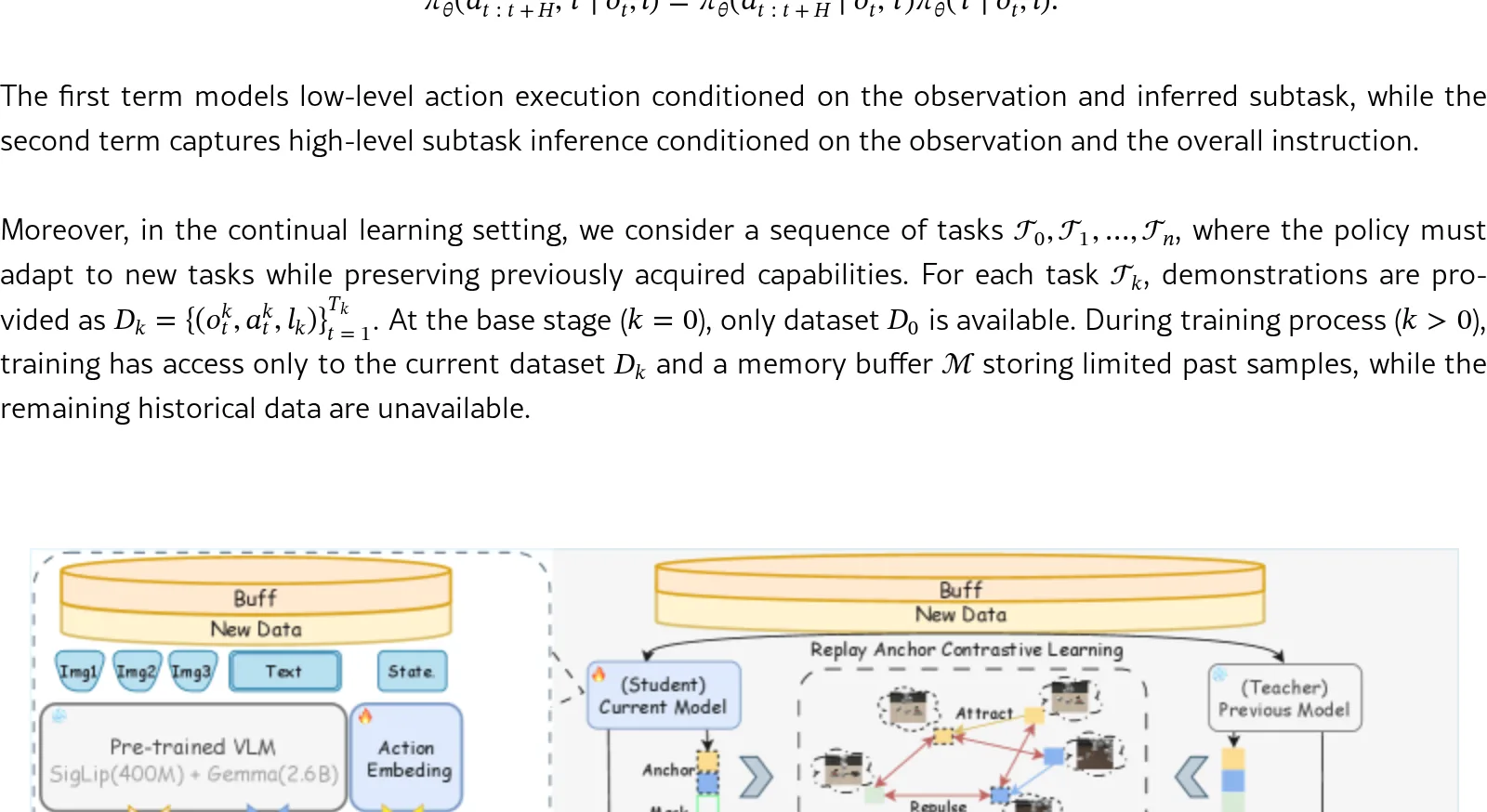
- Replay Anchor Contrastive Learning: 从冻结的教师模型提取历史样本的视觉嵌入作为锚点,学生模型通过对比损失使相同轨迹的表示靠近锚点,同时与不同任务表示分离
- Cross-Modal Mutual Information Maximization: 通过最大化教师和学生模型视觉-语言潜在表示间的互信息,保持跨模态依赖结构;引入边际一致性正则化防止退化解
- 整体目标: L = L_CL + λ₁L_RAC + λ₂L_CMI,其中 L_CL 是 flow-matching 动作预测损失
- 采用 π₀.5 作为预训练基础模型,仅更新动作头参数,保持多模态主干网冻结
Card 05
数据集与资源
数据集与资源
- 数据集: LIBERO 基准,包括 LIBERO-Long (B5-5N1 配置) 和 LIBERO-Goal (B0-5N1 配置)
- 任务设置: 10 个序贯长视野任务,每个任务存储一条轨迹用于重放
- 超参数: λ₁ = λ₂ = 0.1,基础任务训练 3000 步,增量任务每步 600 步
Card 06
评估与结果
评估与结果
- 评估指标: AUC、FWT、NBT、FAA、AA
- 主要结果:
- LIBERO-Long B5-5N1: Info-VLA 达到 AA 78.7%,显著优于 ER 的 72.0%
- LIBERO-Goal B0-5N1: Info-VLA 达到 AA 73.3%,优于 ER 的 67.2%
- 在旧任务保留上提升约 6-9%,NBT 接近 0 或为负值(存在任务间正迁移)
- 消融实验: RAC 显著提升 AUC 和 FAA,CMI 持续提升整体性能,两者互补结合效果最佳