一眼看懂
封面预览
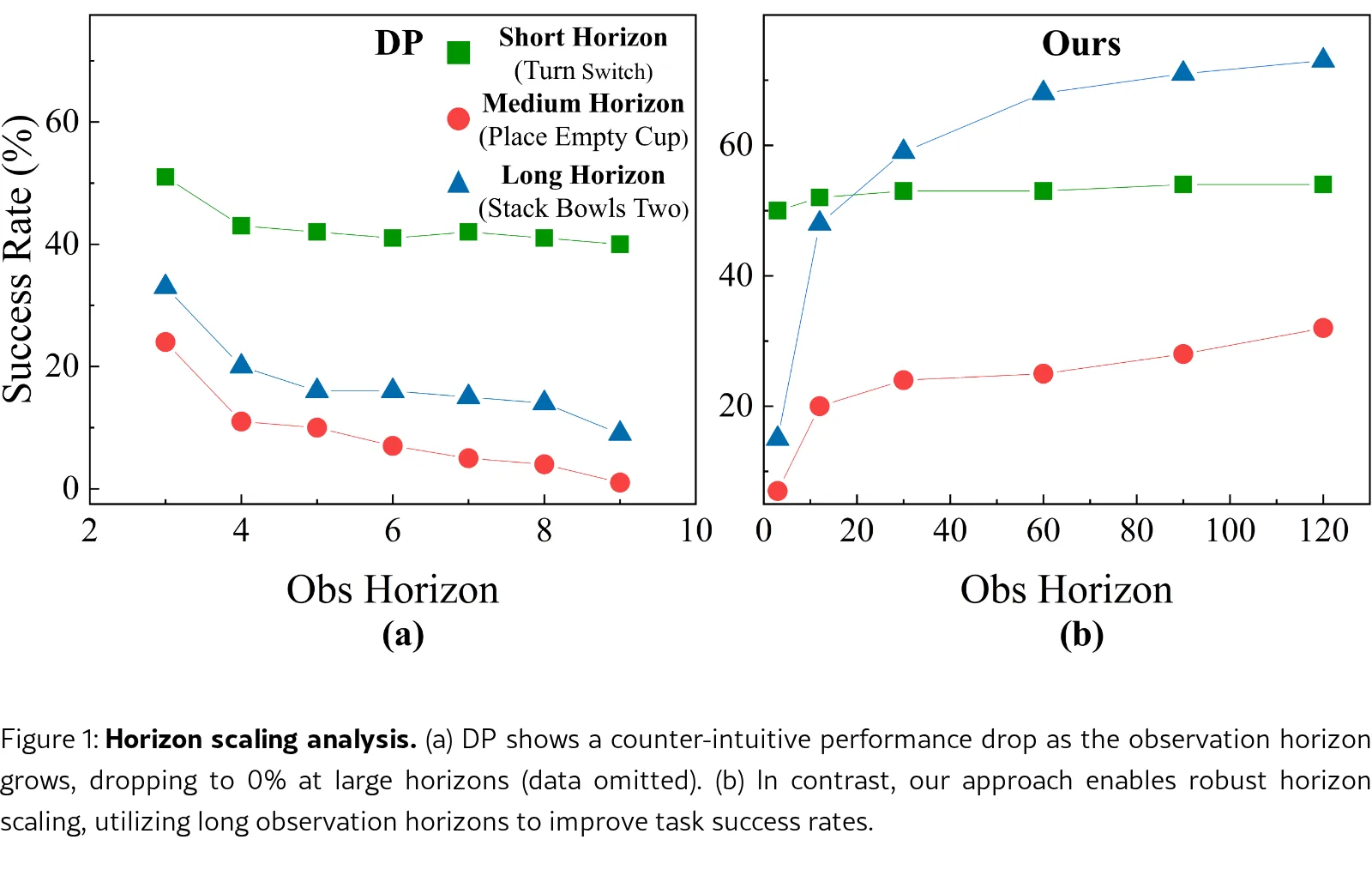
论文旨在解决 Diffusion Policy 在机器人长视野操作任务中,随着观测视野增加导致性能下降的关键问题。
- 论文旨在解决 Diffusion Policy 在机器人长视野操作任务中,随着观测视野增加导致性能下降的关键问题。
- 提出了 SeedPolicy,一种通过集成 自进化门控注意力 模块来增强扩散策略的方法,以实现有效的时序建模和视野扩展。
- 核心目标是让模型能够从长时序历史观测中受益,从而提升在复杂、长流程操作任务中的成功率和鲁棒性。
Card 01
研究单位
研究单位
- 电子科技大学(作者 Youqiang Gui, Xinyang Yuan, Peng Cheng 所属)
- Dexmal Inc.(作者 Shen Cheng, Haoqiang Fan 所属)
- 独立研究者(作者 Yuxuan Zhou)
- 四川大学(作者 Shuaicheng Liu 所属)
Card 02
论文概述
论文概述
- 论文旨在解决 Diffusion Policy 在机器人长视野操作任务中,随着观测视野增加导致性能下降的关键问题。
- 提出了 SeedPolicy,一种通过集成 自进化门控注意力 模块来增强扩散策略的方法,以实现有效的时序建模和视野扩展。
- 核心目标是让模型能够从长时序历史观测中受益,从而提升在复杂、长流程操作任务中的成功率和鲁棒性。
Card 03
核心贡献
核心贡献
- 提出了 自进化门控注意力,一个能通过门控注意力机制维护紧凑、进化潜在状态的时序模块,有效捕获长期依赖并过滤无关干扰。
- 实现了扩散策略的有效视野扩展,扭转了先前方法中视野增长导致性能下降的趋势,成功将更长的观测窗口转化为性能增益。
- 引入了 SeedPolicy,在 RoboTwin 2.0 基准上取得了模仿学习方法中的最优结果,在参数量少一到两个数量级的情况下,性能可媲美大规模视觉-语言-动作模型。
Card 04
方法描述
方法描述
- 方法基于 Diffusion Policy 框架,并集成了所提出的 SEGA 模块。
- SEGA 采用并行双流 Transformer 设计,维护一个时间进化的潜在状态。
- 包含“状态更新”和“状态检索”两个核心流:前者通过门控机制将新观测信息融合到潜在状态中;后者利用历史状态增强当前观测特征。
- 创新性地利用跨注意力图作为动态门控信号,抑制噪声并选择性地保留语义相关信息。
Card 05
数据集与资源
数据集与资源
- RoboTwin 2.0 仿真基准(包含50个操作任务)
- 真实机器人基准(包含 Looping_Place-Retrieval、Sequential_Picking、Bottle_Handover 等任务)
- 模型规模:基于 Transformer 骨干的版本参数量为 33.36M,基于 CNN 骨干的版本参数量为 147.26M。
- 训练资源:使用单张 NVIDIA RTX 4090D GPU。
Card 06
评估与结果
评估与结果
- 评估环境:RoboTwin 2.0 仿真器及真实 Dexmal Dos W1 机器人平台。
- 主要评估指标:任务平均成功率。
- 在仿真实验的“干净”设置下,相比 Diffusion Policy 基线,SeedPolicy 平均取得 36.8% 的相对性能提升;在“随机化”挑战设置下,相对提升高达 169%。
- 在长时域任务中优势显著,任务长度越长,性能提升幅度越大,验证了其卓越的时序建模能力。
- 在真实机器人实验中,成功解决了状态模糊和深度信息缺失导致的执行停滞与空间定位错误问题,显著提升了任务成功率。