一眼看懂
封面预览
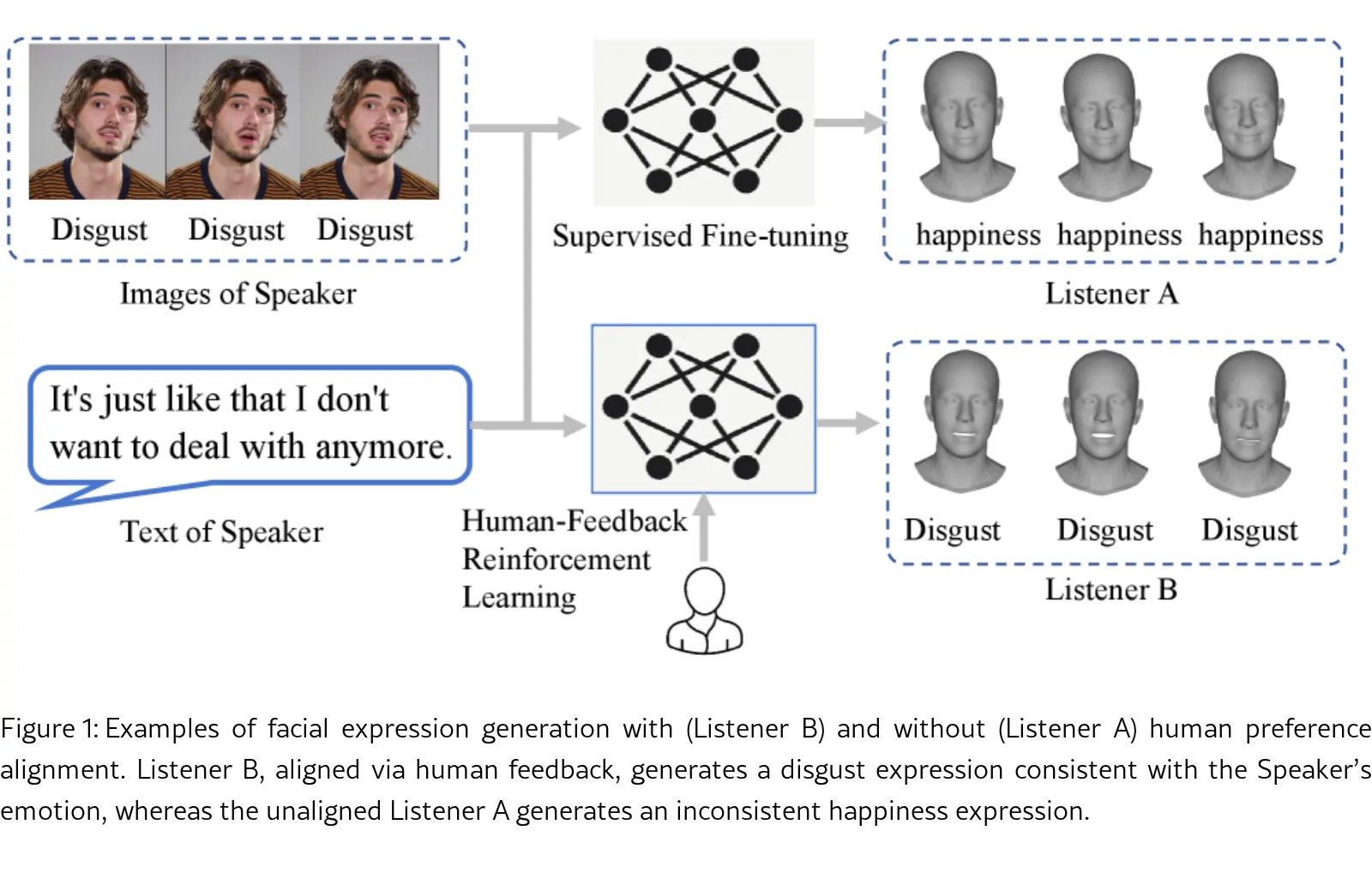
论文研究在自然双人对话交互中,生成符合人类偏好(情感适当且符合社会规范)的听者面部表情。
- 论文研究在自然双人对话交互中,生成符合人类偏好(情感适当且符合社会规范)的听者面部表情。
- 核心目标是解决现有方法忽视表情生成与人类偏好对齐的问题,避免因生成不当表情(如情感不一致)而破坏交互流畅性。
- 提出一种新方法,将人类反馈整合到生成过程中,确保听者表情在上下文和情感上与说话者协调。
Card 01
研究单位
研究单位
- 论文未在提供的HTML正文中明确列出作者所属的具体研究机构信息。
Card 02
论文概述
论文概述
- 论文研究在自然双人对话交互中,生成符合人类偏好(情感适当且符合社会规范)的听者面部表情。
- 核心目标是解决现有方法忽视表情生成与人类偏好对齐的问题,避免因生成不当表情(如情感不一致)而破坏交互流畅性。
- 提出一种新方法,将人类反馈整合到生成过程中,确保听者表情在上下文和情感上与说话者协调。
Card 03
核心贡献
核心贡献
- 首次以闭环方式明确利用人类反馈,将面部表情生成与人类偏好对齐,确保生成的听者反应在视觉自然之外,还具备上下文和情感的适当性。
- 提出一种对齐人类偏好的面部表情生成方法,将表情生成建模为身份无关空间中的动作学习过程,使模型能学习反映人类偏好的表情,而不受视觉或身份偏见影响。
- 建立了一个闭环反馈循环,使听者表情能够动态适应说话者不断演变的多模态对话线索。
- 引入人类反馈强化学习策略,整合对高质量表达反应的模仿与批评家引导的优化。
Card 04
方法描述
方法描述
- 方法分为两个阶段:第一阶段使用视觉-语言-动作模型(VLA) 通过监督微调,将说话者的图像和文本输入映射到可控的、低维的3D可变形模型(FLAME)表达参数。
- 第二阶段采用人类反馈强化学习策略,使用直接偏好优化(DPO) 算法,基于人类评估和排序的偏好数据对策略进行优化。
- 关键创新点包括:将表达生成为身份无关的动作序列,使用双流视觉编码器(DINO 和 SigLIP)捕获细粒度面部动态和全局语义,以及设计动作分词器将连续面部参数离散化为LLM可处理的标记。
Card 05
数据集与资源
数据集与资源
- 使用了两个公开对话数据集进行评估:L2L-trevor 和 Realtalk。
- 模型基于 7B参数的LlaMA 2 大语言模型作为骨干网络。
- 论文HTML正文中未提及具体的GPU/TPU训练资源信息。
Card 06
评估与结果
评估与结果
- 在 L2L-trevor 和 Realtalk 两个基准数据集上与多个基线方法(Random, NN, LM-listener, MMLHG)进行对比。
- 主要评估指标包括:L2距离(重建精度)、Fréchet距离(分布相似度)、成对FD (P-FD)、L2 Affect(情感同步性)、Variation和Diversity。
- 实验结果表明,方法在情感对齐指标(如L2 Affect)上表现最优,其完整的SFT+RL模型在Realtalk数据集上取得最佳的L2 Affect分数(4.3531)。
- 用户研究(25名参与者)显示,方法在适当性、共情、参与度和自然度四个维度上均获得了最高的平均意见分(MOS),适当性得分为4.5,显著超越基线。