一眼看懂
封面预览
论文提出了 Seed2Scale,一种针对具身AI的自演化数据引擎,旨在解决数据稀缺瓶颈。
- 论文提出了 Seed2Scale,一种针对具身AI的自演化数据引擎,旨在解决数据稀缺瓶颈。
- 该引擎通过“小模型收集、大模型评估、目标模型学习”的异构协同架构,实现了从极少量种子演示到大规模高质量数据的自动化生成。
- 核心目标是克服现有数据生成方法存在的探索限制、具身差距和低信噪比等问题,防止自迭代过程中的性能退化。
Card 01
研究单位
研究单位
- 所有论文作者均来自 中兴通讯(ZTE Corporation),中国。
Card 02
论文概述
论文概述
- 论文提出了 Seed2Scale,一种针对具身AI的自演化数据引擎,旨在解决数据稀缺瓶颈。
- 该引擎通过“小模型收集、大模型评估、目标模型学习”的异构协同架构,实现了从极少量种子演示到大规模高质量数据的自动化生成。
- 核心目标是克服现有数据生成方法存在的探索限制、具身差距和低信噪比等问题,防止自迭代过程中的性能退化。
Card 03
核心贡献
核心贡献
- 成本高效的自演化引擎:仅需4个人工演示即可启动大规模数据生成,显著降低对人工数据的依赖。
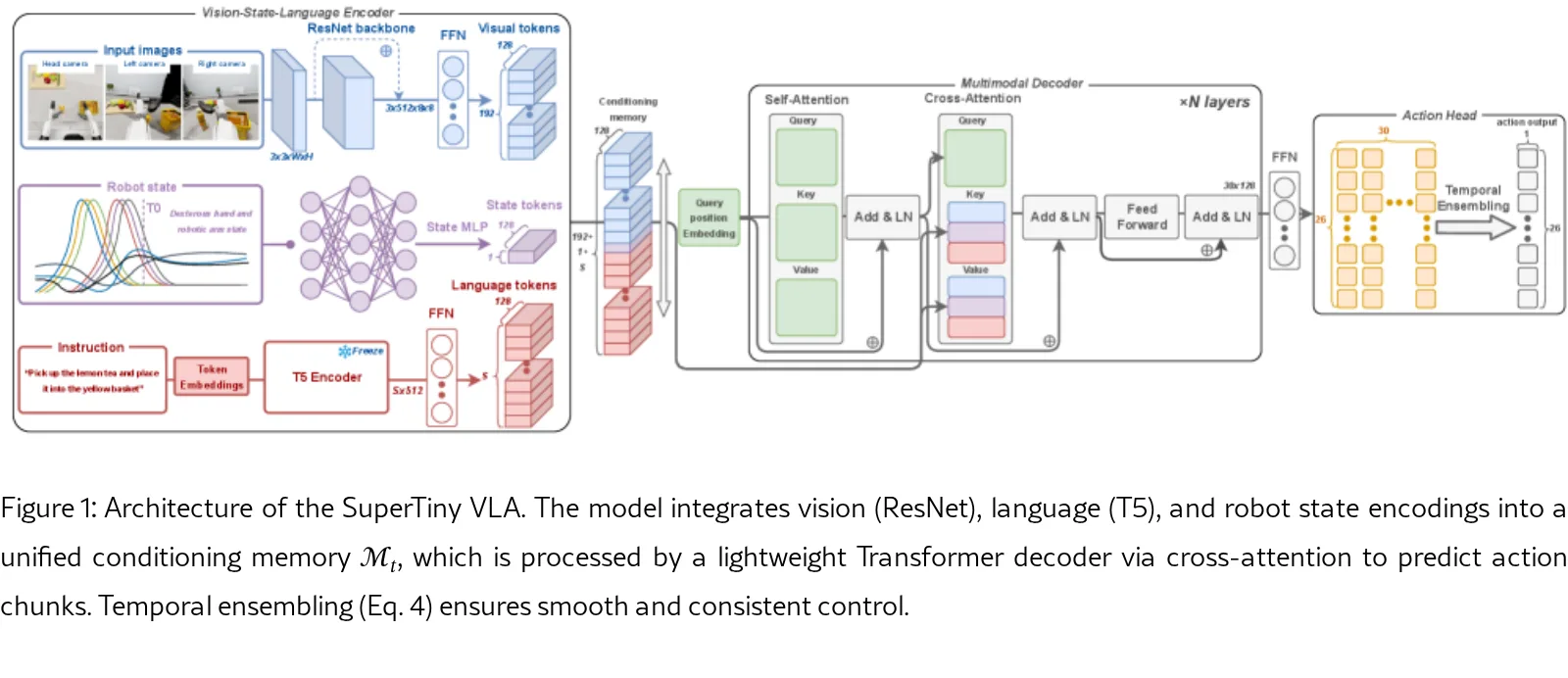
- VLM引导的数据策展流水线:采用轻量级VLA模型 SuperTiny 进行数据收集,并利用预训练VLM作为验证器(VLV)过滤失败和低质量轨迹,有效防止模型崩溃。
- 异构模型协同:整合了“小模型收集、大模型评估、目标模型学习”,解决了探索效率与泛化能力之间的权衡。
- 实验验证与扩展性:验证了目标模型在迭代中性能稳健提升,实现了相对于初始模型209.15%的性能飞跃。
Card 04
方法描述
方法描述
- 采用 SuperTiny 轻量级VLA模型作为专门的数据收集器,利用其强归纳偏置从极少的种子数据中进行稳健探索和并行化轨迹生成。
- 引入 VLM-as-a-Verifier 范式,使用冻结的预训练视觉-语言模型 Qwen3-VL 作为验证器,对生成的轨迹进行成功/失败判断和质量评分,以高信噪比策展数据。
- 设计了 Seed-to-Scale 自举循环,通过迭代式的数据生成、质量筛选和模型训练,实现数据集的自我扩展和目标模型能力的持续提升。
- 目标模型 SmolVLA 通过条件流匹配在策展后的高质量数据集上进行训练,以学习多模态动作分布。
Card 05
数据集与资源
数据集与资源
- 使用 MimicGen 和 RealMirror 作为评估基准和数据来源。
- SuperTiny 收集器包含48M参数,动作块大小K=30;VLV 基于 Qwen3-VL-32B 实现。
- 目标模型 SmolVLA 训练100,000步,使用AdamW优化器(学习率3e-4,批次大小16)。
- 实验采用 NVIDIA H20 GPU进行策略训练,使用 NVIDIA GeForce RTX 5090 GPU部署并行环境进行高效推理和数据生成。
Card 06
评估与结果
评估与结果
- 在 Agibot A2 和 GR-1 机器人的多种操作任务上进行评估,主要指标为 成功率。
- 与仅使用种子数据相比,Seed2Scale将平均成功率从22.18%提升至68.57%,实现 209.15% 的相对性能提升。
- 在GR-1任务上,Seed2Scale在策略成功率和轨迹质量(如总变差、抖动)方面均显著优于现有数据增强方法 MimicGen。
- 自演化机制展现出一致的扩展性能,随着迭代次数增加,目标模型成功率呈稳健上升趋势。
- 消融实验证实,VLV作为成功判别者和质量把关员对于自演化的稳定性至关重要,移除质量过滤会导致性能显著下降。