一眼看懂
封面预览
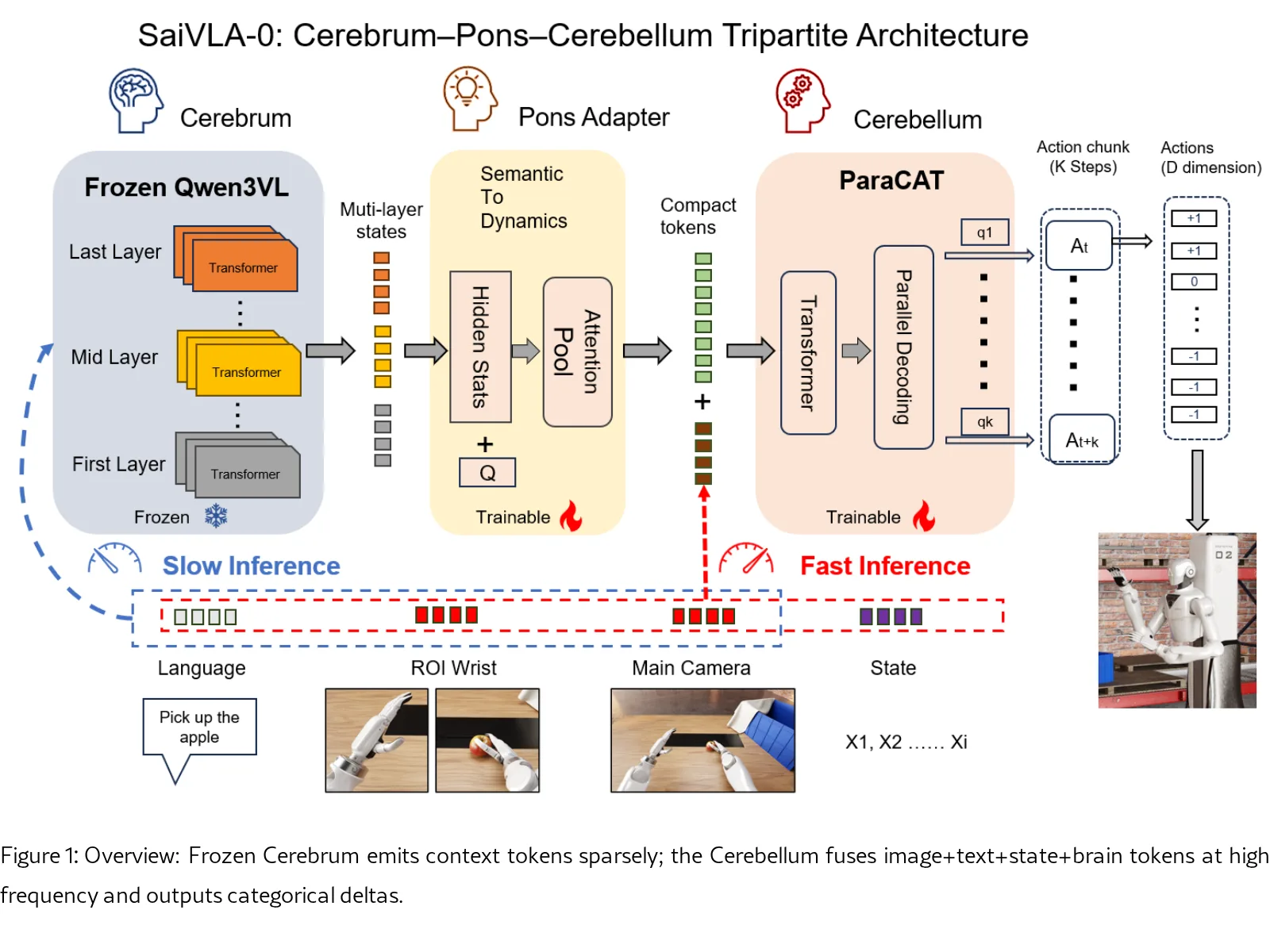
论文提出了 SaiVLA-0,一个受神经科学启发的三层视觉-语言-行动模型架构,将系统分为 Cerebrum(大脑)、Pons Adapter…
- 论文提出了 SaiVLA-0,一个受神经科学启发的三层视觉-语言-行动模型架构,将系统分为 Cerebrum(大脑)、Pons Adapter…
- 核心目标是解决现代VLA模型将语义理解与高频控制纠缠在一起导致高延迟、不稳定的问题,特别是在数据有限的场景下。
- 该设计旨在实现计算感知、可复现且模块化的机器人控制,通过明确分离低频语义理解与高频运动控制来提升效率与稳定性。
Card 01
研究单位
研究单位
- 论文作者均隶属于 Synthoid.ai 研究机构。
Card 02
论文概述
论文概述
- 论文提出了 SaiVLA-0,一个受神经科学启发的三层视觉-语言-行动模型架构,将系统分为 Cerebrum(大脑)、Pons Adapter(脑桥适配器) 和 Cerebellum(小脑) 三个模块化组件。
- 核心目标是解决现代VLA模型将语义理解与高频控制纠缠在一起导致高延迟、不稳定的问题,特别是在数据有限的场景下。
- 该设计旨在实现计算感知、可复现且模块化的机器人控制,通过明确分离低频语义理解与高频运动控制来提升效率与稳定性。
Card 03
核心贡献
核心贡献
- 提出了仿生学的 三层架构:冻结的VLM作为Cerebrum提供高层先验;Pons适配器整合信息并编译意图;Cerebellum(ParaCAT头)执行快速分类动作解码。
- 引入了 几何绑定的ROI机制,通过校准投影将腕部感兴趣区域与末端执行器绑定,提供稳定、高分辨率的视觉线索,模拟了生物的中央凹视觉。
- 设计了 ParaCAT(并行分类动作Transformer) 头部,能够通过一次前向传播输出多步动作,并采用迟滞/EMA等机制提升执行稳定性。
- 提出了 双频调度与两阶段训练策略:离线缓存冻结Cerebrum的特征,在线训练轻量级适配器与小脑,大幅减少训练时间与计算成本。
- 实现了系统的 模块化与可升级性:升级Cerebrum只需重训Pons;更换机器人只需重训Cerebellum,提高了泛化与可维护性。
Card 04
方法描述
方法描述
- 整体架构遵循“大脑-脑桥-小脑”分工。Cerebrum 是冻结的大型视觉语言模型(如 Qwen-VL-8B),稀疏运行并输出多层隐藏状态。
- Pons Adapter 是一个可训练的模块,通过层间投影、融合和注意力池化,将Cerebrum的多层特征压缩成固定长度的上下文令牌。
- Cerebellum 是一个高频运行的系统,包含一个ViT编码器、文本编码器和 ParaCAT 动作头。它融合当前图像、指令、机器人状态及大脑上下文令牌,输出每维度的三分类增量({-1, 0, +1})。
- 采用 固定比率调度(Cerebrum每N个块调用一次)和 微视野复用(一次前向预测K步),以摊薄计算成本并提升有效动作速率。
- 通过 两阶段训练 实现效率最大化:阶段A离线缓存Cerebrum特征;阶段B在线训练Pons与Cerebellum。
Card 05
数据集与资源
数据集与资源
- 主要在 LIBERO 基准上进行评估,包含LIBERO-Spatial、Object、Goal和Long四个子集,每个子集10个任务,500个回合。
- 计划扩展至真实机器人任务,包括 叠衣服、将物体放入锅中 和 按固定距离移动物体。
- 模型主干使用 Qwen-VL-8B(并在缩放研究中测试4B/32B版本),Cerebellum采用6层Transformer,维度为1024。
- 初步LIBERO实验在 8块GPU 上训练 20,000步,批次大小为80。
Card 06
评估与结果
评估与结果
- 评估遵循LIBERO官方协议,报告平均成功率、抖动/加加速度、延迟分解、有效动作频率以及 计算归一化成功率(SR_cn)。
- 关键结果表明:采用分层特征缓存的两阶段训练,在官方N1.5仅头部训练下,将训练时间从7.5小时缩短至4.5小时,并将平均成功率从86.5%提升至92.5%。
- SaiVLA-0 在LIBERO基准上达到了 99.0%的平均成功率。
- 论文作为一篇概念与协议论文,提供了详细的评估协议、缓存架构和成功标准,旨在促进独立验证,而非宣称决定性优势。