一眼看懂
封面预览
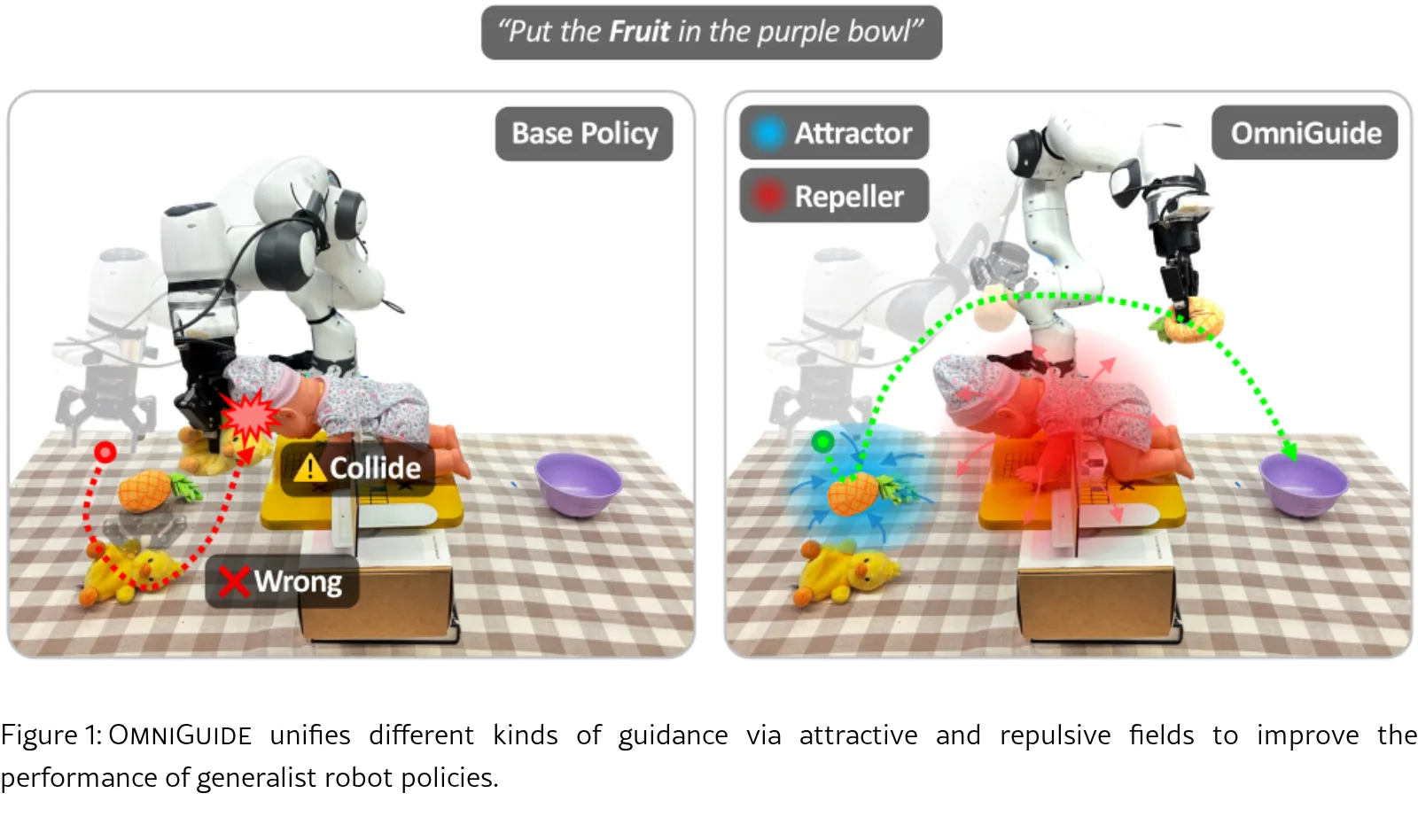
论文提出了 OmniGuide,一个通过利用任意指导源(如3D基础模型、语义推理VLM和人体姿态模型)来提升视觉-语言-动作(VLA)模型性能…
- 论文提出了 OmniGuide,一个通过利用任意指导源(如3D基础模型、语义推理VLM和人体姿态模型)来提升视觉-语言-动作(VLA)模型性能…
- 研究旨在解决当前VLA模型在复杂空间理解、杂乱环境操作和精确操作等任务上表现不佳的问题。
- 框架将多种指导信号自然地表达为三维空间中的可微能量函数,通过吸引和排斥场在推理时引导VLA的动作采样,无需重新训练。
Card 01
研究单位
研究单位
- University of Pennsylvania
Card 02
论文概述
论文概述
- 论文提出了 OmniGuide,一个通过利用任意指导源(如3D基础模型、语义推理VLM和人体姿态模型)来提升视觉-语言-动作(VLA)模型性能的灵活框架。
- 研究旨在解决当前VLA模型在复杂空间理解、杂乱环境操作和精确操作等任务上表现不佳的问题。
- 框架将多种指导信号自然地表达为三维空间中的可微能量函数,通过吸引和排斥场在推理时引导VLA的动作采样,无需重新训练。
Card 03
核心贡献
核心贡献
- 提出了一个统一的推理时指导框架,适用于任何基于扩散或流匹配的可微生成策略,与模型训练方式无关。
- 框架能够表达吸引场(语义目标、人类演示)和排斥场(障碍物避让),并支持两者的协同,所有能量及梯度均可在实时计算。
- 验证了框架的通用性,展示了多种感知基础模型可单独或协同引导最先进的VLA策略,显著提升了其在挑战性任务上的成功率和安全性。
- 实验证明,该统一框架的性能匹配或超越了以往为融合特定指导源而设计的专用方法。
Card 04
方法描述
方法描述
- 技术基础是 流匹配 的VLA策略,其动作生成过程是一个从噪声到数据的连续向量场。
- 核心思想是将任务约束(如避障、语义目标)建模为定义在干净笛卡尔轨迹上的能量函数。
- 在每个去噪步骤中,首先估计干净的行动块,然后通过可微的运动学模型预测笛卡尔轨迹,计算任务能量并反向传播梯度至行动空间,从而引导生成过程。
- 框架支持在初始噪声分布(通过蒙特卡洛采样选择最优初始噪声)和中间去噪步骤(通过梯度修正)两个层面施加指导。
Card 05
数据集与资源
数据集与资源
- 仿真实验使用 RoboCasa 基准。
- 真实世界实验在 DROID 平台上进行,使用 Franka Research 3 机械臂。
- 使用的基础VLA模型包括 GR00T N1.6-3B(仿真)和 π0.5(真实世界)。
- 真实世界实验使用 NVIDIA RTX 5090 GPU 进行推理。
Card 06
评估与结果
评估与结果
- 在仿真和真实世界环境中,评估了三种指导模态:碰撞避免、语义定位 和 人类模仿。
- 主要评估指标为 成功率 和 安全率(碰撞避免率)。
- 在仿真中,OmniGuide将基线模型的成功率从24.2%提升至92.4%,安全率从7.0%提升至93.5%。
- 消融实验表明,结合初始噪声优化和去噪指导能带来最大的性能提升。
- 在真实世界实验中,OmniGuide在所有九项任务上均显著优于基线VLA和专门设计的对比方法。
- 尽管引入了额外的计算开销,系统控制频率仍能保持在约15 Hz,满足实时部署要求。