一眼看懂
封面预览
论文旨在解决当前 Vision-Language-Action (VLA) 模型领域研究碎片化、设计选择缺乏系统性评估的问题。
- 论文旨在解决当前 Vision-Language-Action (VLA) 模型领域研究碎片化、设计选择缺乏系统性评估的问题。
- 研究在统一的框架和评估设置下,系统性地重新审视VLA的设计空间,提炼出构建强VLA模型的实用“配方”。
- 最终提出了一个简单而有效的模型 VLANeXt,在仿真基准和真实机器人实验中均展现出卓越的性能和泛化能力。
Card 01
研究单位
研究单位
- 论文作者包括 Xiao-Ming Wu、Bin Fan、Kang Liao、Jian-jian Jiang、Runze Yang、Yihang Luo、Zhonghua Wu、Wei-Shi Zheng、Chen Change Loy。原文未明确标注作者所属机构。
Card 02
论文概述
论文概述
- 论文旨在解决当前 Vision-Language-Action (VLA) 模型领域研究碎片化、设计选择缺乏系统性评估的问题。
- 研究在统一的框架和评估设置下,系统性地重新审视VLA的设计空间,提炼出构建强VLA模型的实用“配方”。
- 最终提出了一个简单而有效的模型 VLANeXt,在仿真基准和真实机器人实验中均展现出卓越的性能和泛化能力。
Card 03
核心贡献
核心贡献
- 系统性地剖析了VLA设计的三个核心维度:基础组件、感知要领、动作建模视角,并从中提炼出 12个关键发现,形成构建强VLA模型的实用配方。
- 基于研究提出的配方,提出了 VLANeXt 模型,在 LIBERO 和 LIBERO-plus 基准测试中取得了超越先前最先进方法的性能。
- 在真实世界的机器人操纵任务上进行了广泛评估,验证了 VLANeXt 出色的泛化能力。
- 计划发布一个 统一、易用的代码库,作为社区探索VLA设计空间和构建新模型变体的共享基础。
Card 04
方法描述
方法描述
- 研究从类似 RT-2 和 OpenVLA 的基线模型出发,通过消融实验逐步演进设计。
- 提出并验证了多项关键创新:采用独立的、更大的 策略模块 并通过“软连接”与VLM交互;使用 流匹配 作为动作学习目标;引入 频域损失 作为辅助任务。
- 在感知层面,发现使用 多视角输入(第三人称+手腕摄像头) 和将 本体感觉 条件注入VLM(而非策略模块)能显著提升性能。
- 最终的 VLANeXt 模型整合了上述所有有效的设计选择。
Card 05
数据集与资源
数据集与资源
- 主要使用 LIBERO 和 LIBERO-plus 基准数据集进行训练和评估,其中LIBERO-plus包含多种未见过的扰动以测试鲁棒性。
- 最终 VLANeXt 模型的规模为 2.5B 参数。
- 原文未明确说明训练所使用的具体GPU/TPU等计算资源。
Card 06
评估与结果
评估与结果
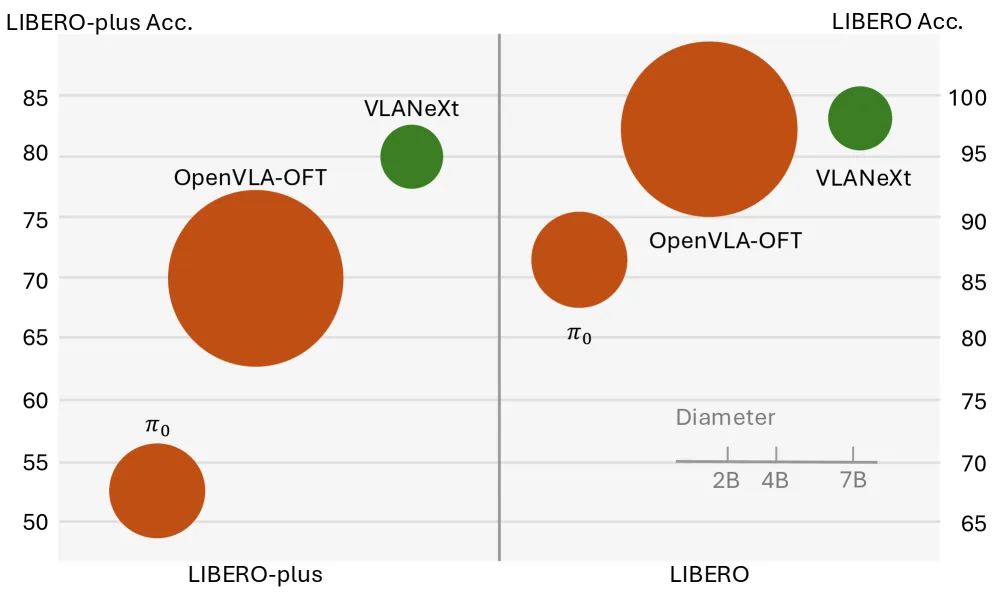
- 评估在 LIBERO(测试标准任务性能)和 LIBERO-plus(测试鲁棒性和泛化能力)两个基准上进行。
- 主要评估指标为 任务成功率。
- 在 LIBERO 基准上,VLANeXt 在四个测试套件上的平均成功率达到了 97.4%,超越了 OpenVLA-OFT (97.1%) 等先前最优模型。
- 在更具挑战性的 LIBERO-plus 基准上,VLANeXt 展现了强大的鲁棒性,相较于其他方法有显著提升,特别是在相机视角、光照和背景变化等扰动下表现优异。