一眼看懂
封面预览
论文提出了 FRAPPE 方法,旨在通过多未来表征对齐将世界建模能力注入通用机器人策略中。
- 论文提出了 FRAPPE 方法,旨在通过多未来表征对齐将世界建模能力注入通用机器人策略中。
- 该研究解决了现有世界模型方法过度强调像素级重建限制语义学习,以及推理时依赖预测观察导致误差累积的问题。
- 方法采用两阶段微调策略,使模型能够预测未来观察的潜在表征,并通过并行计算扩展与多个视觉基础模型对齐。
Card 01
研究单位
研究单位
- 浙江大学
- 西湖大学
- 香港科技大学(广州)
- 华南理工大学
- 上海科技大学
- 清华大学
Card 02
论文概述
论文概述
- 论文提出了 FRAPPE 方法,旨在通过多未来表征对齐将世界建模能力注入通用机器人策略中。
- 该研究解决了现有世界模型方法过度强调像素级重建限制语义学习,以及推理时依赖预测观察导致误差累积的问题。
- 方法采用两阶段微调策略,使模型能够预测未来观察的潜在表征,并通过并行计算扩展与多个视觉基础模型对齐。
Card 03
核心贡献
核心贡献
- 提出了一种新颖的训练范式,通过并行扩展计算量和多视觉表征对齐,增强了 VLA 模型的隐式世界建模能力。
- 设计了两阶段训练策略(中间训练和后训练),实现了高效学习并避免了直接应用并行缩放时的收敛缓慢问题。
- 方法能够利用无动作标注的人类自我中心视频数据进行训练,显著降低了对昂贵遥操作数据的依赖。
- 在仿真和真实世界实验中均超越了现有 SOTA 模型,在遥操作数据稀缺时实现了 10-15% 的性能提升。
Card 04
方法描述
方法描述
- 基于 Robotic Diffusion Transformer (RDT) 架构,引入可学习的未来前缀作为输入以预测未来状态。
- 中间训练阶段:模型与从多个视觉基础模型蒸馏出的教师编码器对齐,进行全参数微调以适应世界建模目标。
- 后训练阶段:采用前缀与 LoRA 混合专家架构,在冻结骨干网络的情况下并行对齐 CLIP、DINOv2 和 ViT 等多个视觉模型。
- 推理阶段:保留并行计算图,通过可学习的路由网络聚合多个专家的输出,无需依赖视觉基础模型监督。
Card 05
数据集与资源
数据集与资源
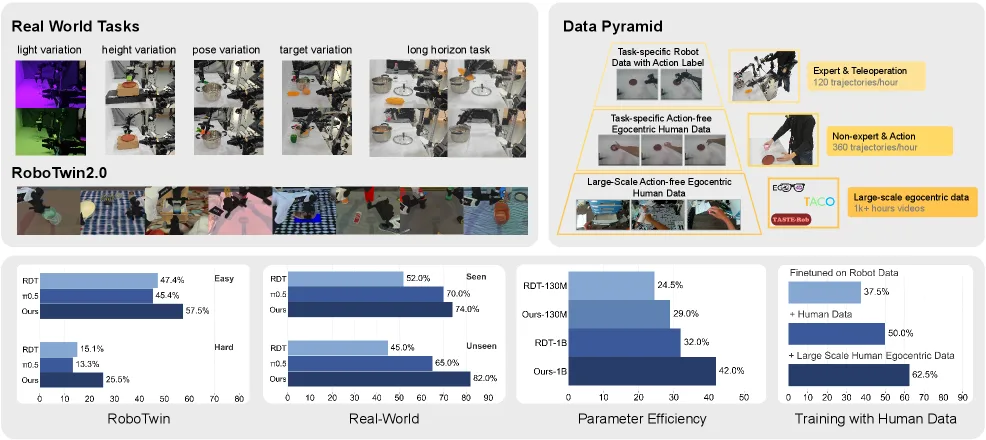
- 仿真基准:RoboTwin 数据集,包含 8 个任务及 Easy 和 Hard 两种设置。
- 真实世界:AgileX 双臂移动机械臂平台,包含 4 个基础泛化任务和 1 个长程任务。
- 辅助数据:大规模人类自我中心视频数据集 TASTE-Rob 及任务特定的人类操作视频。
- 训练资源:使用 2 张 NVIDIA H100 GPU,共训练 20,000 步,Batch Size 为 32。
Card 06
评估与结果
评估与结果
- 评估环境包括 RoboTwin 仿真基准和真实世界双臂操作任务,对比了 DP、VPP、RDT、$\pi_0$ 等模型。
- 仿真实验中,FRAPPE 在 Easy 设置下平均成功率达 57.5%,在 Hard 设置下达 25.5%,均显著优于基线模型。
- 真实世界实验表明,该方法在未见过的场景中具有强泛化能力,且在长程任务中实现了 20% 的成功率(基线模型为 0%)。
- 消融实验验证了结合人类视频数据能显著提升模型在难抓取物体上的表现,证明了数据金字塔策略的有效性。