一眼看懂
封面预览
arXiv 论文结构化总结
- arXiv 论文结构化总结
- 首次成功将 GRPO 应用于视觉生成任务,提出 Flow-GRPO 框架
- 系统梳理了 Flow-GRPO 之后的七大类方法改进方向:奖励信号设计、信用分配、采样效率、模式崩溃与多样性保持、奖励黑客缓解、ODE vs…
Card 01
论文概述
论文概述
arXiv 论文结构化总结
Card 02
研究单位
研究单位
- Zexiang Liu — SJTU (上海交通大学)
- Xianglong He — THU (清华大学)
- Yangguang Li — CUHK (香港中文大学)
Card 03
论文概述
论文概述
- 论文是关于 Flow-GRPO(流匹配模型的组相对策略优化)的综合survey,介绍了如何将原本用于大语言模型(LLM)的GRPO算法扩展到生成模型(如文本到图像、视频、3D、语音合成等)的对齐训练中。
- 研究的核心问题在于:流匹配模型的采样过程由确定性ODE(常微分方程)驱动,缺乏强化学习所需的随机探索特性,且视觉任务的奖励通常只在最终步骤提供(稀疏奖励问题),导致信用分配困难。
- Flow-GRPO 通过将 ODE 转换为 SDE(随机微分方程)并引入去噪收缩策略来解决这些问题,在文本渲染任务上将 GenEval 准确率从 63% 提升至 95%,角色渲染准确率从 59% 提升至 92%。
Card 04
核心贡献
核心贡献
- 首次成功将 GRPO 应用于视觉生成任务,提出 Flow-GRPO 框架
- 系统梳理了 Flow-GRPO 之后的七大类方法改进方向:奖励信号设计、信用分配、采样效率、模式崩溃与多样性保持、奖励黑客缓解、ODE vs SDE 采样策略、奖励模型设计
- 总结了 GRPO 在九大生成任务领域的应用扩展:文本到图像、视频生成、图像编辑、语音音频、3D生成、VLA与具身智能、统一多模态模型、自回归与掩码扩散模型、图像修复与超分辨率
- 涵盖超过 200 篇 已发表论文,展现了该领域的快速研究增长
Card 05
方法描述
方法描述
- Flow-GRPO 核心方法:将流匹配模型的确定性 ODE 采样转换为 SDE(引入漂移项和扩散项),使模型能够在采样过程中产生随机性;通过组内相对奖励计算优势(advantage),无需显式价值函数
- 关键技术:
- ODE→SDE 转换公式:$dx_t = v_\theta(x_t,t)dt + \sigma(t)dW_t$
- 去噪过程建模为马尔可夫决策过程(MDP)
- PPO-style 裁剪策略确保训练稳定性
- 每步对数似然计算:$\log\pi_\theta(a_t\|s_t)$
Card 06
数据集与资源
数据集与资源
- 论文为 survey 类型,未提及具体单个模型的参数规模
- 涉及的主要基准数据集:
- GenEval:文本到图像对齐评估基准
- PickScore:人类偏好评分
- HPS v2.1(Human Preference Score v2.1)
- ImageReward
- 训练效率改进:部分方法实现 20-25 倍 加速(如 DiffusionNFT、AWM)
Card 07
评估与结果
评估与结果
- 主要评估指标:PickScore、GenEval、HPS v2.1、ImageReward
- 关键实验结果:
- Flow-GRPO 在文本渲染任务 GenEval:63%→95%
- 角色渲染准确率:59%→92%
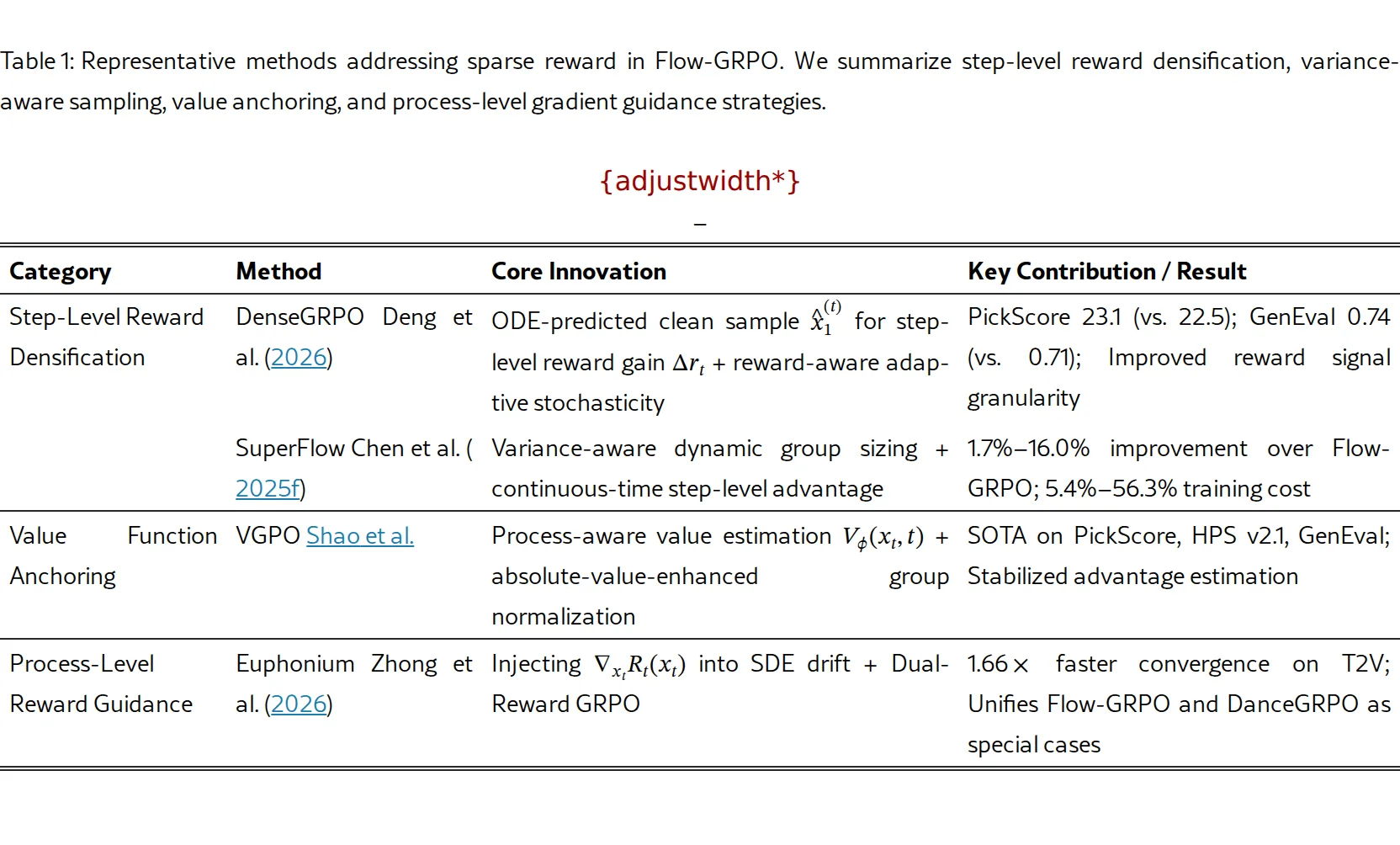
- DenseGRPO:PickScore 23.1(vs 22.5),GenEval 0.74(vs 0.71)
- TreeGRPO:2.4倍训练加速
- BranchGRPO:比 DanceGRPO 提升 16%,训练时间减少 55%
- SuperFlow:比 Flow-GRPO 提升 1.7%-16.0%,训练步骤减少 94.6%-43.7%
- DiffusionNFT:GenEval 0.24→0.98(1000步内)
- AWM:24倍加速
- DGPO:约20倍加速