一眼看懂
封面预览
论文针对 Vision-Language-Action (VLA) 模型在接触丰富型操作任务中表现不佳的问题,指出现有模型过度依赖高熵的视觉和…
- 论文针对 Vision-Language-Action (VLA) 模型在接触丰富型操作任务中表现不佳的问题,指出现有模型过度依赖高熵的视觉和…
- 提出了 CRAFT 框架,通过 Variational Information Bottleneck (VIB) 模块调节多模态信息流,在训练…
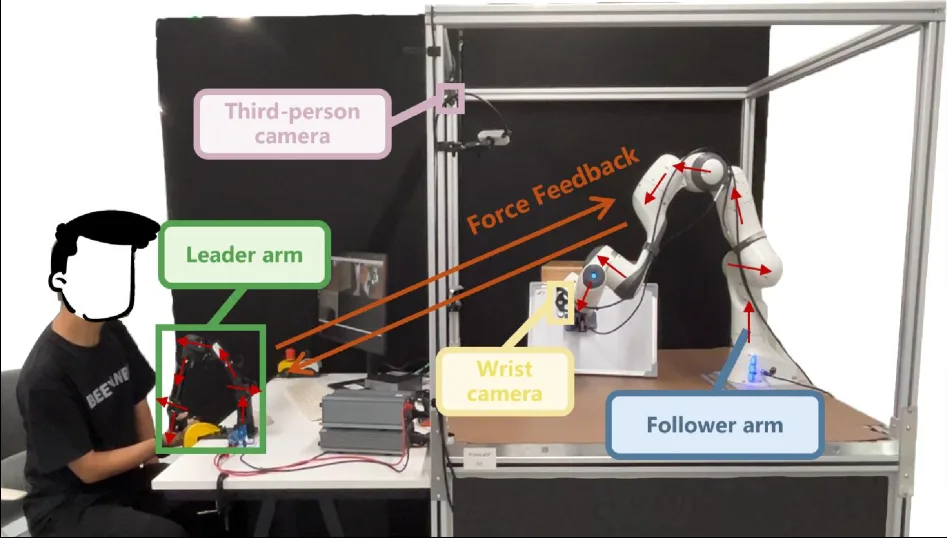
- 设计了一种低成本的同源主从遥操作系统,用于收集包含视觉、语言和力(关节扭矩)的同步高质量数据。
Card 01
研究单位
研究单位
- National Engineering Research Center of Robot Visual Perception and Control Technology, Hunan University(湖南大学)
- Beijing Innovation Center of Humanoid Robotics(北京人形机器人创新中心)
- National University of Singapore(新加坡国立大学)
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在接触丰富型操作任务中表现不佳的问题,指出现有模型过度依赖高熵的视觉和语言输入,而忽略了低熵但关键的力信号。
- 提出了 CRAFT 框架,通过 Variational Information Bottleneck (VIB) 模块调节多模态信息流,在训练初期抑制视觉语言信息以优先学习力信号,随后逐步恢复全模态感知能力。
- 设计了一种低成本的同源主从遥操作系统,用于收集包含视觉、语言和力(关节扭矩)的同步高质量数据。
Card 03
核心贡献
核心贡献
- 提出了 CRAFT 框架,利用信息瓶颈原理和课程学习策略,实现了 VLA 模型对力信号的优先学习与多模态平衡。
- 开发了基于 Franka Emika Panda 机械臂的同源主从遥操作系统,无需额外触觉传感器即可采集同步的力感知演示数据。
- 在五项真实世界的接触丰富型任务中验证了方法的有效性,证明该方法能显著提升任务成功率并泛化至未见物体和新任务变化。
Card 04
方法描述
方法描述
- 引入 Variational Information Bottleneck (VIB) 模块置于视觉-语言编码器之后,通过 KL 散度正则化压缩高熵的视觉和语言嵌入。
- 设计了力感知课程微调策略:训练初期使用较高的 VIB 权重强制模型关注低熵的关节扭矩信号,随后通过指数衰减进度逐步释放视觉语言信息。
- 使用关节扭矩作为本体感知输入,相比传统的关节位置,扭矩编码了更丰富的交互动力学信息(如惯性效应和外部接触力)。
Card 05
数据集与资源
数据集与资源
- 使用自采集数据集:每项任务包含 50 次遥操作演示,物体位姿进行了随机化处理。
- 硬件平台:Franka Emika Panda 机械臂,配备腕部摄像头(第一人称)和静态摄像头(第三人称)。
- 基础模型:$\pi_0$(基于流匹配)和 RDT(基于扩散模型)。
Card 06
评估与结果
评估与结果
- 评估环境为真实世界,任务包括 USB 插入、翻转纸箱、擦白板、揉橡皮泥和轴孔插入。
- 评估指标为任务成功率。
- 实验结果显示,$\pi_0$-base 结合 CRAFT 平均成功率提升了 35.36%,RDT 结合 CRAFT 平均提升了 25.66%。
- 在泛化性测试(OOD)中,CRAFT 将平均成功率从 22.50% 提升至 58.75%,证明了其在新物体和新任务变体上的鲁棒性。