一眼看懂
封面预览
论文提出了 视觉前瞻规划 框架,旨在引导视觉-语言-动作(VLA)模型逐步执行复杂任务。
- 论文提出了 视觉前瞻规划 框架,旨在引导视觉-语言-动作(VLA)模型逐步执行复杂任务。
- 核心目标是解决现有VLA模型难以将高级语言指令转化为具体、可执行动作序列的问题。
- 通过生成想象中的未来观测图像作为视觉指导,使VLA模型专注于视觉运动推理,提升准确性与泛化能力。
Card 01
研究单位
研究单位
- 作者来自 麻省理工学院(MIT)、NVIDIA 和 加州理工学院。
Card 02
论文概述
论文概述
- 论文提出了 视觉前瞻规划 框架,旨在引导视觉-语言-动作(VLA)模型逐步执行复杂任务。
- 核心目标是解决现有VLA模型难以将高级语言指令转化为具体、可执行动作序列的问题。
- 通过生成想象中的未来观测图像作为视觉指导,使VLA模型专注于视觉运动推理,提升准确性与泛化能力。
Card 03
核心贡献
核心贡献
- 提出了一个通用、高效的视觉前瞻规划器,通过想象未来观测和子任务描述来逐步指导VLA模型。
- 设计了一个极其高效的远见图像生成模块,能在 H100 GPU 上仅需 0.33秒 生成高质量的 640×480 未来观测图像。
- 实现了与现有最先进VLA模型(如 π₀、π₀.₅)的无缝集成,无需修改模型架构。
- 通过在超过 100万 条多任务、跨具身数据上的预训练,使远见生成器学习了稳健的具身动力学。
- 在真实世界和模拟基准测试中均取得了显著性能提升,并展示了出色的分布外泛化能力和数据效率。
Card 04
方法描述
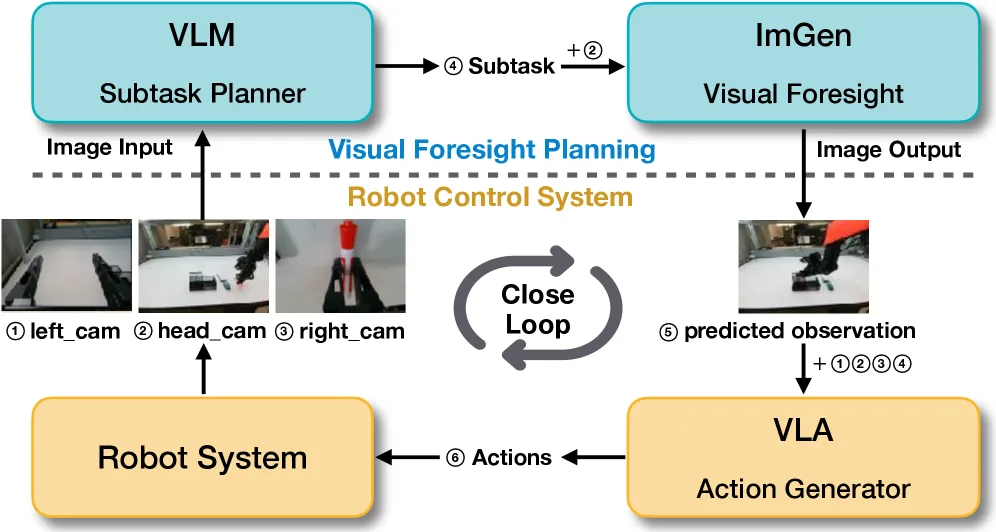
方法描述
- ForeAct框架 采用“推理-执行-监控”的闭环工作模式。
- 核心组件 包括一个高效的远见图像生成器 和一个用于推理与监控的 视觉-语言模型(VLM)。
- 远见图像生成器 基于 SANA 架构进行改进,采用深度压缩自编码器和线性DiT架构以实现高效的高分辨率生成,并将当前观测图像作为条件输入。
- VLM模块(使用 Qwen-3-VL-8B-Instruct)负责将复杂任务分解为可执行的子任务描述,并监控任务进展。
- 集成方式简单,仅通过将生成的未来观测图像与当前观测拼接,作为增强的视觉输入馈送给VLA模型。
Card 05
数据集与资源
数据集与资源
- 预训练数据:整合自 AgiBot-World Colosseo、RoboMind、Galaxea Open-World 和 Bridge 等开源数据集,包含约 116万 个子任务,最终形成约 1000万 数据对。
- 评估数据:自建了一个包含 11 个多样化、多步骤真实世界任务的基准数据集,涵盖厨房、工作区和工厂场景。
- 模型规模:远见图像生成器模型初始化自 SANA-1.6B。
- 训练资源:在 64个H100 GPU 上进行预训练。
- 部署资源:采用云边协同部署,视觉前瞻规划器部署于云端 H100 GPU,VLA策略部署于边缘端 RTX 5090 GPU。
Card 06
评估与结果
评估与结果
- 评估环境:真实世界双臂移动操作机器人平台 Galaxea R1 Lite 和仿真基准 LIBERO。
- 主要指标:任务成功率,基于“原子动作”完成率进行细粒度评分。
- 真实世界基准结果:在11项任务中平均成功率达 87.4%,相比 π₀ 基线(46.5%)绝对提升 40.9%,相比 VLM增强的π₀ 基线(57.1%)绝对提升 30.3%。
- 模拟基准结果:在LIBERO基准上,集成ForeAct的 π₀.₅ 模型平均成功率从96.8%提升至 97.5%,达到最佳性能。
- 泛化性与效率:在分布外任务中表现稳健,且在使用仅 20% 训练数据时仍能达到 79% 的成功率,展现了卓越的数据效率。