一眼看懂
封面预览
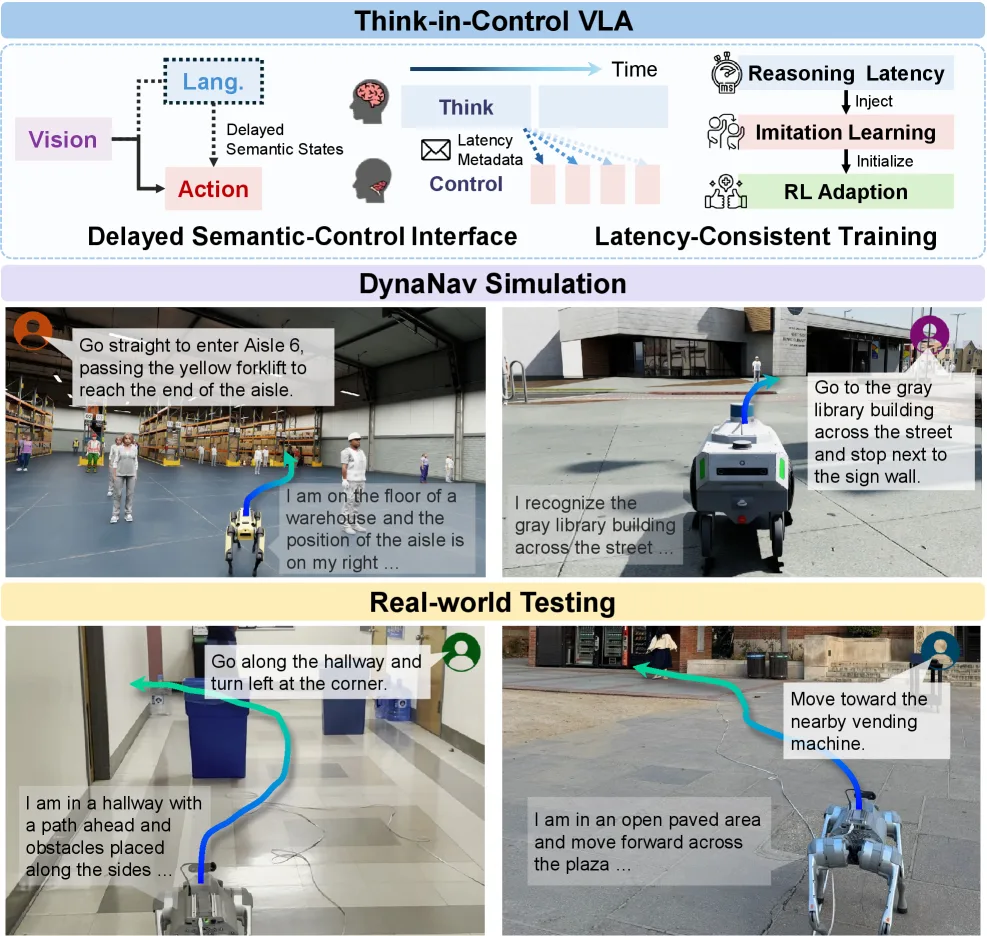
论文旨在解决现有 视觉-语言-动作 (VLA) 模型在动态环境中导航时,假设语义推理与实时控制时间对齐,但实际上推理存在延迟导致不匹配的核心问…
- 论文旨在解决现有 视觉-语言-动作 (VLA) 模型在动态环境中导航时,假设语义推理与实时控制时间对齐,但实际上推理存在延迟导致不匹配的核心问…
- 提出了 TIC-VLA 框架,这是一个延迟感知框架,显式地将推理延迟建模进动作生成过程,以实现稳健的实时控制。
- 引入了 DynaNav 模拟套件,用于在逼真的动态环境中评估语言引导导航,并展示了TIC-VLA在仿真和真实机器人上的优越性能。
Card 01
研究单位
研究单位
- 论文作者隶属于 UCLA (University of California, Los Angeles)。
- 项目主页为 https://ucla-mobility.github.io/TIC-VLA/
Card 02
论文概述
论文概述
- 论文旨在解决现有 视觉-语言-动作 (VLA) 模型在动态环境中导航时,假设语义推理与实时控制时间对齐,但实际上推理存在延迟导致不匹配的核心问题。
- 提出了 TIC-VLA 框架,这是一个延迟感知框架,显式地将推理延迟建模进动作生成过程,以实现稳健的实时控制。
- 引入了 DynaNav 模拟套件,用于在逼真的动态环境中评估语言引导导航,并展示了TIC-VLA在仿真和真实机器人上的优越性能。
Card 03
核心贡献
核心贡献
- 提出了 延迟语义-控制接口,将延迟的视觉-语言语义状态和显式的延迟元数据作为动作生成的条件,使策略能够补偿异步推理。
- 设计了 延迟一致训练管道,在模仿学习和在线强化学习中注入推理延迟,使训练与异步部署保持一致,提升了策略的鲁棒性。
- 开发了 DynaNav,一个物理精确、照片级逼真的动态环境语言导航模拟套件和基准,支持可复现评估。
- 实验证明,TIC-VLA在仿真和真实世界中均持续优于先前的VLA模型,并能保持稳健的实时控制。
Card 04
方法描述
方法描述
- 采用双系统架构,将慢速的VLM语义推理与快速的反应式动作策略解耦。
- 使用 InternVL3-1B 作为VLM骨干进行语义推理,动作策略是一个基于Transformer的专家网络。
- 关键创新在于 延迟语义-控制接口,它将延迟的VLM KV缓存特征和延迟元数据(包括延迟时间和自运动偏移)传递给动作策略。
- 提出 延迟一致训练管道,包含三个阶段:VLM监督微调、基于延迟语义输入的模仿学习、以及带异步引导的在线强化学习,其中显式注入了随机推理延迟。
Card 05
数据集与资源
数据集与资源
- 训练数据集包括 SCAND(8.7小时社交导航数据)、GND(11小时校园导航数据)和自采集的 DynaNav模拟数据集(5.1小时)。
- 模型基于 InternVL3-1B VLM(包含InternViT-300M视觉编码器和Qwen2.5-0.5B语言模型)和6层交叉注意力Transformer的动作专家。
- 训练使用8张 NVIDIA L40S GPU,采用分布式数据并行和AdamW优化器。
Card 06
评估与结果
评估与结果
- 评估基准为论文提出的 DynaNav,包含85个测试用例,涵盖不同人群密度、导航距离和四种场景(仓库、医院、办公室、户外人行道)。
- 评估指标包括:导航误差(NE)、成功率(SR)、路径长度加权成功率和碰撞率(CR)。
- 在DynaNav基准上,TIC-VLA 取得了最高的成功率(55.29%)和最低的碰撞率(28.24%),显著优于Uni-NaVid、NaVILA、DualVLN等基线方法。
- 真实世界测试在四足机器人 Unitree Go2 上进行,TIC-VLA在NVIDIA Jetson Orin NX边缘设备上实现了75%的成功率,证明了其在多秒推理延迟下维持实时控制的能力。