一眼看懂
封面预览
论文针对自动驾驶中视觉-语言-动作(VLA)模型使用思维链推理时存在的推理延迟高的问题,提出了一种加速方法。
- 论文针对自动驾驶中视觉-语言-动作(VLA)模型使用思维链推理时存在的推理延迟高的问题,提出了一种加速方法。
- 介绍了 FastDriveCoT,一种新颖的并行解码方法,通过将推理过程分解为依赖图来加速模板化的思维链生成。
- 该方法能够在单次前向传播中并发生成多个独立的推理步骤,显著减少了顺序计算量,适用于实时自动驾驶应用。
Card 01
研究单位
研究单位
- NVIDIA
- University of Southern California
- Harvard University
- Stanford University
Card 02
论文概述
论文概述
- 论文针对自动驾驶中视觉-语言-动作(VLA)模型使用思维链推理时存在的推理延迟高的问题,提出了一种加速方法。
- 介绍了 FastDriveCoT,一种新颖的并行解码方法,通过将推理过程分解为依赖图来加速模板化的思维链生成。
- 该方法能够在单次前向传播中并发生成多个独立的推理步骤,显著减少了顺序计算量,适用于实时自动驾驶应用。
Card 03
核心贡献
核心贡献
- 提出了 FastDriveCoT 框架,利用自动驾驶推理任务的结构化特性实现并行解码。
- 设计了一种基于依赖图的动态规划算法,能够自动识别并调度可并行生成的推理字段,最小化前向传播次数。
- 实现了高效的推理机制,通过定制注意力掩码和共享 KV 缓存,在零额外计算开销的情况下最大化硬件利用率。
- 在多种模型架构和规模上验证了方法的有效性,实现了 3-4 倍的加速且保持了下游任务性能。
Card 04
方法描述
方法描述
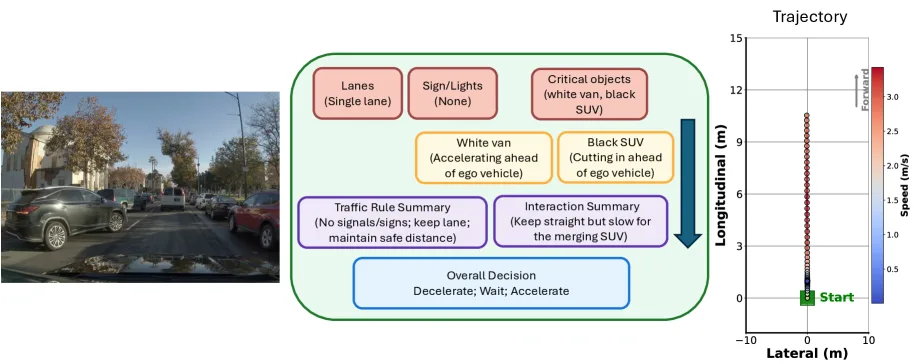
- 模板化思维链:定义了包含照明、路况、关键物体、交通规则等字段的结构化模板,将非结构化的推理转化为结构化字段生成。
- 依赖图构建:将有依赖关系的字段(如交通标志 -> 交通规则总结)建模为有向无环图(DAG),相互独立的字段(如天气、路况)可并行处理。
- 并行解码调度:使用动态规划算法根据依赖图动态调度解码过程,每次前向传播同时生成所有“就绪”字段的 token。
- 推理优化:将所有并行生成的 token 打包在同一个序列中,通过自定义注意力掩码控制依赖关系,并利用共享 KV 缓存减少内存访问瓶颈。
Card 05
数据集与资源
数据集与资源
- 使用了一个包含 20,000 小时驾驶数据的内部数据集,覆盖 2500 多个城市和 25 个国家。
- 利用 Qwen2.5-VL-72B 模型通过自动标注流程生成了结构化的思维链训练数据,共 717,344 个训练样本。
- 实验在单张 NVIDIA A100 80GB SXM GPU 上进行推理评估。
- 测试的基础模型包括 Qwen2-0.5B、Qwen3-1.7B 和 Qwen2.5-VL-3B。
Card 06
评估与结果
评估与结果
- 评估指标包括 CoT 生成时间、端到端延迟、元动作准确率(IOU)和轨迹预测误差(ADE)。
- 实验结果显示,FastDriveCoT 实现了 3.1 到 4.1 倍的思维链生成加速。
- 端到端推理延迟降低了 1.9 到 3.1 倍,使得思维链推理在实时系统中变得可行。
- 在保持原有任务性能提升的同时,部分任务(如元动作预测)的性能甚至略有提升,证明了并行解码策略的有效性。