一眼看懂
封面预览
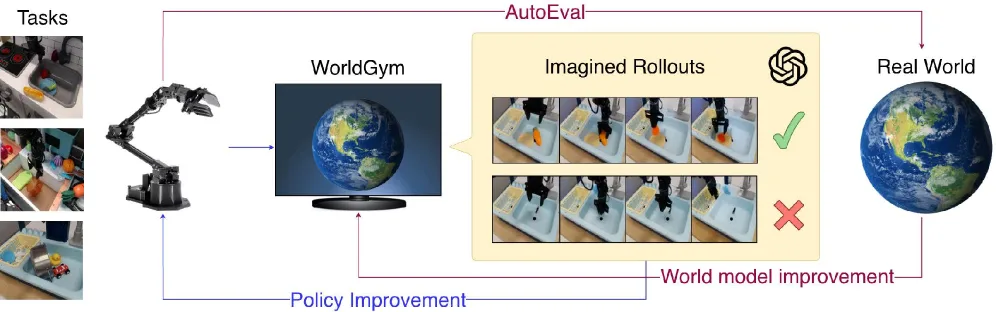
提出 World-Gymnast 框架,在学习到的世界模型(WorldGym)中通过强化学习微调 VLA(视觉-语言-动作)策略,解决机器人从…
- 提出 World-Gymnast 框架,在学习到的世界模型(WorldGym)中通过强化学习微调 VLA(视觉-语言-动作)策略,解决机器人从…
- 旨在克服两种替代方案的局限性:监督微调(SFT)受限于专家演示数据量,软件模拟器存在 sim-to-real 差距
- 核心问题:能否在世界模型中训练策略,比监督学习或传统模拟器获得更好的真实机器人性能
Card 01
研究单位
研究单位
- 作者 affiliations 在 HTML 正文中未明确显示具体机构名称
- 论文来自 arXiv (arXiv:2602.02454)
Card 02
论文概述
论文概述
- 提出 World-Gymnast 框架,在学习到的世界模型(WorldGym)中通过强化学习微调 VLA(视觉-语言-动作)策略,解决机器人从物理交互中学习成本过高的问题
- 旨在克服两种替代方案的局限性:监督微调(SFT)受限于专家演示数据量,软件模拟器存在 sim-to-real 差距
- 核心问题:能否在世界模型中训练策略,比监督学习或传统模拟器获得更好的真实机器人性能
Card 03
核心贡献
核心贡献
- 提出在视频世界模型中进行 RL 训练的方法,使用动作条件视频生成模型(WorldGym)作为环境,VLM 作为奖励模型
- 在 Bridge 机器人平台上,World-Gymnast 性能超越 SFT 最高达 18 倍,超越软件模拟器(SIMPLER)最高达 2 倍
- 展示了世界模型 RL 的独特能力:从任意帧训练、新颖语言指令泛化、测试时训练、迭代式世界模型与策略改进
- 利用图像编辑、语言增强等技术扩展训练数据,提高策略在干扰物和分布外场景下的鲁棒性
Card 04
方法描述
方法描述
- 基础模型:使用 OpenVLA-OFT(基于 OpenVLA 7B 在 BridgeData V2 上微调)作为初始策略
- 世界模型:采用 WorldGym(600M 参数变体),基于 Open X-Embodiment 数据预训练的动作条件视频生成模型
- 奖励模型:使用 GPT-4o VLM 对轨迹进行二进制任务完成奖励评估
- RL 算法:采用 GRPO(Group Relative Policy Optimization),通过组内得分归一化估计优势函数
- 训练技巧:丢弃 KL 惩罚项、动态采样过滤无奖励方差的组、高温度采样、较高 clip ratio
Card 05
数据集与资源
数据集与资源
- 评估平台:AutoEval 真实机器人评估框架
- 任务集:基于 BridgeData V2 的 17 个任务,涵盖视觉、运动、物理和语义变化
- 训练数据:可通过图像编辑(Nano Banana)、语言增强、任务扩展进行数据缩放
- 训练资源:4 张 NVIDIA H200 GPU(每张 140GB),全参数微调 1-2 天
- 超参数:学习率 5×10⁻⁶,组大小 8,批次大小 20,动作分块长度 5,温度 1.6
Card 06
评估与结果
评估与结果
- 评估环境:WorldGym(世界模型)+ AutoEval(真实机器人)
- 主要指标:任务成功率(Success Rate)
- 关键结果:
- 与 SIMPLER(软件模拟器)对比:World-Gymnast 在 4 项任务中 3 项获胜(Open drawer: 58% vs 34%;Put eggplant to blue sink: 72% vs 32%;Put eggplant to yellow basket: 78% vs 40%)
- 与 SFT 对比:在 "Put eggplant into blue sink" 任务提升 18 倍(72% vs 4%),在 "Put eggplant into yellow basket" 提升近 10 倍(78% vs 8%)
- 干扰物训练(World-Gymnast-Distract)达到 78% 成功率
- 语言增强训练(World-Gymnast-Language)达到 81% 成功率
- 测试时训练使 "Close drawer" 任务从 62% 提升至 100%
- 迭代式世界模型更新后,"Close drawer" 达到 95% 成功率