一眼看懂
封面预览
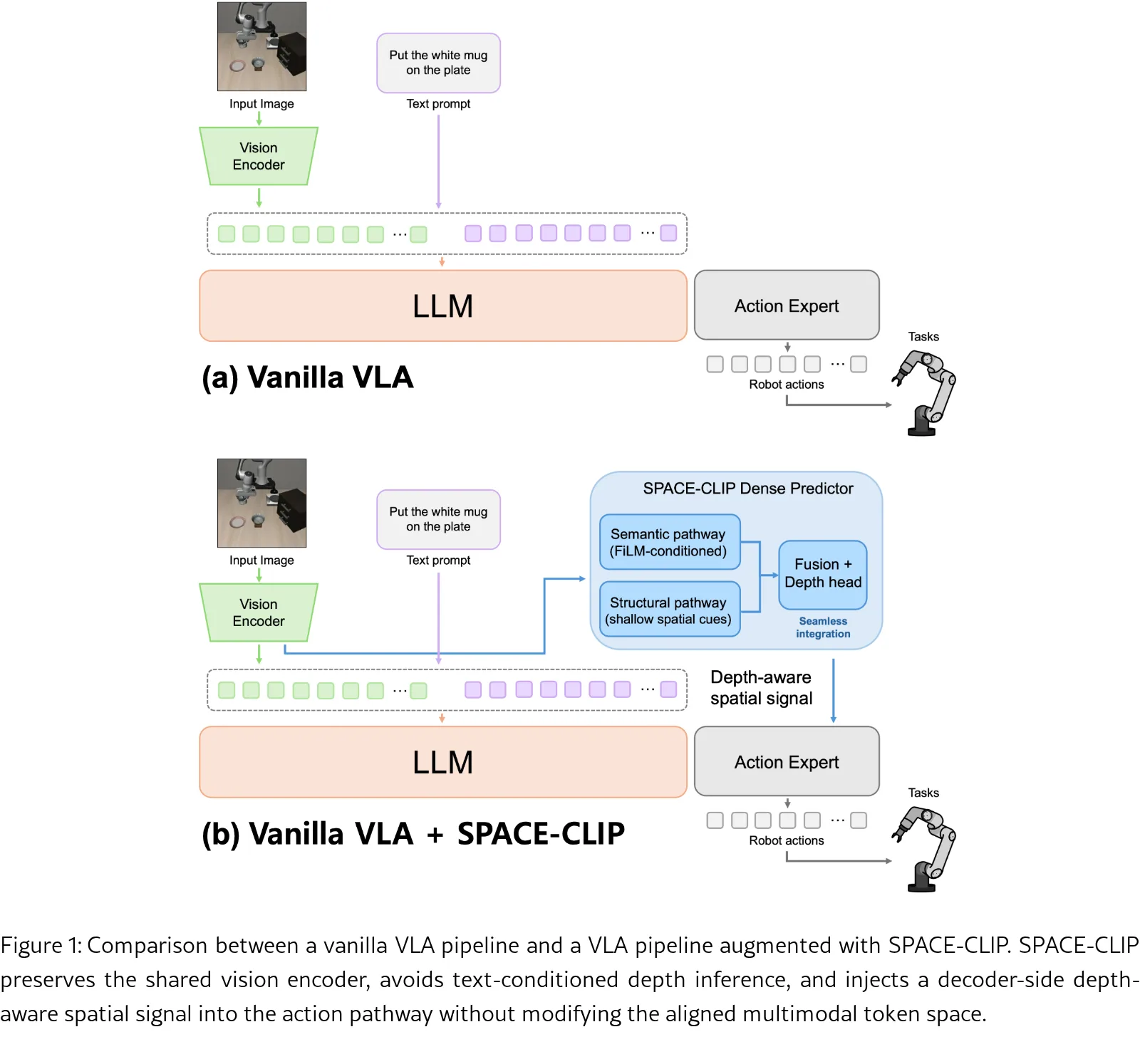
提出 SPACE-CLIP,一种在 TFI-FB 约束(text-free inference + frozen backbone)下的单目深…
- 提出 SPACE-CLIP,一种在 TFI-FB 约束(text-free inference + frozen backbone)下的单目深…
- 核心创新:完全绕过文本编码器,直接从冻结的 CLIP ViT-B/16 视觉编码器解码几何信息
- 解决的问题:现有 CLIP 深度方法依赖文本提示和图像-文本匹配,导致间接推理和计算开销
Card 01
研究单位
研究单位
- Gachon University (Republic of Korea), School of Computing
- 通讯作者:Andrew Jaeyong Choi (andrewjchoi@gachon.ac.kr)
Card 02
论文概述
论文概述
- 提出 SPACE-CLIP,一种在 TFI-FB 约束(text-free inference + frozen backbone)下的单目深度估计方法
- 核心创新:完全绕过文本编码器,直接从冻结的 CLIP ViT-B/16 视觉编码器解码几何信息
- 解决的问题:现有 CLIP 深度方法依赖文本提示和图像-文本匹配,导致间接推理和计算开销
Card 03
核心贡献
核心贡献
- 提出双路径解码器架构:语义路径(使用 FiLM 调制深层特征 L12, L9, L6, L3)+ 结构路径(使用浅层特征 L2, L1, L0 保留局部几何细节)
- 采用分层融合解码器逐步上采样并融合语义与结构特征
- 在 TFI-FB 约束下达到 SOTA 性能:KITTI AbsRel 0.0901,NYU Depth V2 AbsRel 0.1042
- 为具身 AI(如 VLA 模型)提供模块化感知蓝图,可作为即插即用的深度估计模块
Card 04
方法描述
方法描述
- 冻结骨干网络:使用预训练 CLIP ViT-B/16(openai/clip-vit-base-patch16),完全不更新参数
- 语义路径:提取深层 CLIP 特征(L12, L9, L6, L3),使用 FiLM 通过全局 [CLS] token 生成 scale γ 和 shift β 参数进行调制
- 结构路径:提取浅层 CLIP 特征(L2, L1, L0),保留高分辨率边缘和纹理信息
- 分层融合:每阶段 2× 上采样语义特征,与对应结构特征 concat 逐步细化
- 损失函数:SILog 损失 + SSIM 损失(λ_ssim=0.5)
Card 05
数据集与资源
数据集与资源
- 数据集:KITTI(Eigen split,22,600 训练图像,697 测试图像)、NYU Depth V2
- 模型:CLIP ViT-B/16(冻结)+ 可学习 Dense Predictor(解码器通道 [256, 128, 64, 32])
- 训练环境:单卡 NVIDIA GPU,AdamW 优化器,lr=1e-4,weight_decay=0.01,20 epochs,cosine warmup
Card 06
评估与结果
评估与结果
- KITTI(TFI-FB 约束下):AbsRel 0.0901,SqRel 0.4701,RMSE 3.8451,δ<1.25 0.9088
- NYU Depth V2:AbsRel 0.1042,RMSE 0.3848,log10 0.0446,δ<1.25 0.8958
- 消融实验:Baseline(无 FiLM/结构路径)AbsRel 0.1165;仅 FiLM:0.1142;仅结构路径:0.1094;两者结合(SPACE-CLIP):0.0901
- 结论:结构路径贡献更大,FiLM 提供场景级上下文,两者协同效果最佳