一眼看懂
封面预览
Mirage2Matter 是一个基于物理的 Gaussian 世界模型,能够从多视角视频生成高保真的具身智能训练数据,解决了现实世界交互数据…
- Mirage2Matter 是一个基于物理的 Gaussian 世界模型,能够从多视角视频生成高保真的具身智能训练数据,解决了现实世界交互数据…
- 现有模拟平台存在显著的视觉和物理差距,需要专业硬件进行数据收集,限制了其规模化应用
- 该方法将 3D Gaussian Splatting (3DGS) 重建的真实感场景与物理模拟器结合,实现视觉-物理一致性,支持 VLA 模型…
Card 01
研究单位
研究单位
- MBZUAI (Mohamed bin Zayed University of Artificial Intelligence, UAE)
- AI²Robotics (China)
- The University of Sydney (Australia)
- Carnegie Mellon University (USA)
- The University of Melbourne (Australia)
Card 02
论文概述
论文概述
- Mirage2Matter 是一个基于物理的 Gaussian 世界模型,能够从多视角视频生成高保真的具身智能训练数据,解决了现实世界交互数据稀缺的问题
- 现有模拟平台存在显著的视觉和物理差距,需要专业硬件进行数据收集,限制了其规模化应用
- 该方法将 3D Gaussian Splatting (3DGS) 重建的真实感场景与物理模拟器结合,实现视觉-物理一致性,支持 VLA 模型的零样本 Sim2Real 迁移
Card 03
核心贡献
核心贡献
- 高保真世界表示:仅使用普通多视角视频重建目标环境和可操作物体的高保真视觉表示
- 物理 grounded 机器人中心建模:利用生成模型高效生成碰撞就绪的几何表示,引入校准管道确保模拟与现实世界的尺度对齐
- 实用且可扩展的具身学习数据生成:构建高效可扩展的世界模型支持大规模数据模拟,使 VLA 模型在各种操纵任务上实现强零样本泛化
Card 04
方法描述
方法描述
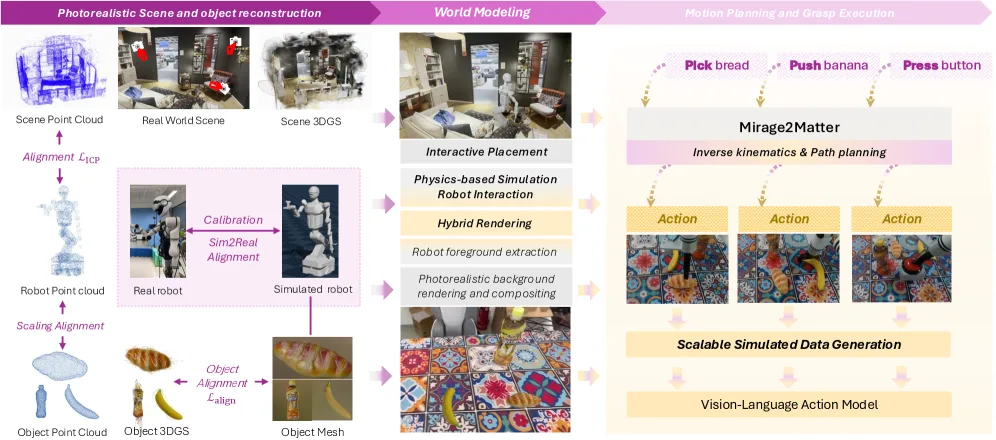
- 3D Gaussian Splatting (3DGS):使用各向异性 3D Gaussian 基元作为照片级真实感表示,通过 rasterization 和 splatting 实现高效新视图渲染
- 场景重建:使用 COLMAP 进行 SfM 重建,获取稀疏点云和相机位姿,训练场景 3DGS
- 物体重建:使用 SAM2 进行物体分割,优化物体级 3DGS;使用 Tripo3D 生成水密 mesh 用于物理模拟
- 跨域对齐:
- 场景对齐:SfM → Genesis 框架,通过 scaled ICP 在校准板区域和机器人基座区域之间进行对齐
- 物体对齐:物体 3DGS ↔ Mesh,通过相似度变换和 ICP 精化对齐
- 数据生成:交互式放置物体 → 合并为统一 3DGS 世界 → Genesis 物理模拟 → 运动规划 (IK + RRT) → 混合渲染 (Genesis 机器人 + 3DGS 背景)
Card 05
数据集与资源
数据集与资源
- 数据集:自采集的多视角视频,包含香蕉、牛角面包等日常物体
- 物理模拟器:Genesis 物理引擎
- 生成模型:Tripo3D 用于 mesh 生成
- VLA 模型:PoSA-VLA (默认),也测试了 π₀.₅ 和 OpenVLA-OFT
- 训练资源:NVIDIA A100 GPU (训练),NVIDIA RTX 4090 (推理)
- 数据规模:每个任务和物体 300 条模拟演示轨迹,每个任务 50 条真实机器人演示
- 机器人平台:AlphaBot 1s,7-DoF 机械臂,头部 RGB 相机
Card 06
评估与结果
评估与结果
- 评估任务:Grasp (抓取)、Press Button (按按钮)、Push/Pull (推拉)
- 基准对比:DISCOVERSE、RoboSimGS、Real-World (真实数据训练)
- 主要指标:成功率 (Success Rate %)
关键实验结果
\|任务/方法 \|Real-World \|DISCOVERSE \|RoboSimGS \|Mirage2Matter \|
\|
--
---\|
--
----\|
--
----\|
--
---\|
--
--
--\|
\|抓取香蕉 \|96.7 \|60.0 \|76.7 \|80.0 \|
\|抓取牛角面包 \|90.0 \|66.7 \|76.7 \|86.7 \|
\|按按钮 \|96.7 \|- \|- \|93.3 \|
\|推拉物体 \|83.3 \|- \|- \|73.3 \|
- 消融实验:使用 3DGS 物体表示 vs 网格表示,平均成功率从 78.4% 提升至 83.4%
- 数据规模影响:50 条 → 53.4%,150 条 → 81.7%,300 条 → 83.4%