一眼看懂
封面预览
论文提出 PEAfowl,一个用于双手操作(bimanual manipulation)的感知增强多视角视觉-语言-动作(VLA)模型,旨在解…
- 论文提出 PEAfowl,一个用于双手操作(bimanual manipulation)的感知增强多视角视觉-语言-动作(VLA)模型,旨在解…
- 现有 VLA 模型的局限性:多视角特征通过视角无关的 token 拼接融合,缺乏 3D 空间一致性理解;语言以全局条件注入,导致指令定位粗糙
- 研究目标:在存在遮挡、视角和场景变化的情况下,保持双手操作的稳定性和泛化能力
Card 01
研究单位
研究单位
- 中国科学院自动化研究所:Qingyu Fan, Yinghao Cai, Tao Lu, Shuo Wang
- 南京大学:Qingyu Fan, Zhaoxiang Li, Yi Lu, Wang Chen, Qiu Shen, Xiao-xiao Long, Xun Cao
- 通讯作者:Xiao-xiao Long (xxlong@nju.edu.cn) 和 Yinghao Cai (yinghao.cai@ia.ac.cn)
Card 02
论文概述
论文概述
- 论文提出 PEAfowl,一个用于双手操作(bimanual manipulation)的感知增强多视角视觉-语言-动作(VLA)模型,旨在解决复杂场景中的鲁棒性问题
- 现有 VLA 模型的局限性:多视角特征通过视角无关的 token 拼接融合,缺乏 3D 空间一致性理解;语言以全局条件注入,导致指令定位粗糙
- 研究目标:在存在遮挡、视角和场景变化的情况下,保持双手操作的稳定性和泛化能力
Card 03
核心贡献
核心贡献
- 几何引导的多视角感知模块:从多视角 RGB-D 观测构建空间感知表示,结合深度蒸馏方案用于真实部署
- Perceiver 风格的文本查询读取机制:替代全局文本条件,通过冻结 CLIP 特征上的文本感知查询,生成紧凑的指令条件化 token
- 跨视图 3D 邻域聚合:在共享基坐标系中基于几何邻近性聚合信息,提高对遮挡和视角变化的鲁棒性
- 深度蒸馏技术:训练时使用预训练的 Camera Depth Model (CDM) 监督深度分布预测,推理时仅使用原始深度,无推理开销
Card 04
方法描述
方法描述
- 几何引导多视角融合 (GGMVF):对每个 token 预测离散深度分布,执行可微 3D 提升,在共享基坐标系中进行跨视图邻域聚合,使用门控残差更新
- 语言引导多视角读取:使用 Perceiver 风格的文本查询机制,迭代更新文本潜在向量以交叉注意力到 CLIP patch token,生成视觉定位的文本潜在向量
- 策略骨干:采用 SEM 风格的扩散动作解码器,预测 H 步双臂关节轨迹,使用关节中心状态编码器
- 训练目标:扩散模仿损失 + 前向运动学一致性损失 + 深度蒸馏损失的加权组合
Card 05
数据集与资源
数据集与资源
- 数据集:RoboTwin 2.0 双手操作基准,9 个任务(短/中/长视野交互),每个任务 50 条演示
- 模型规模:300M 可训练参数
- 评估环境:
- 模拟:Clean 设置和 Domain-Randomized (DR) 设置,Aloha-AgileX 平台,4 摄像头 RGB-D 设置
- 真实机器人:AgileX Piper 双手平台,6 个任务,100 条演示/任务
Card 06
评估与结果
评估与结果
- 模拟结果 (RoboTwin 2.0):
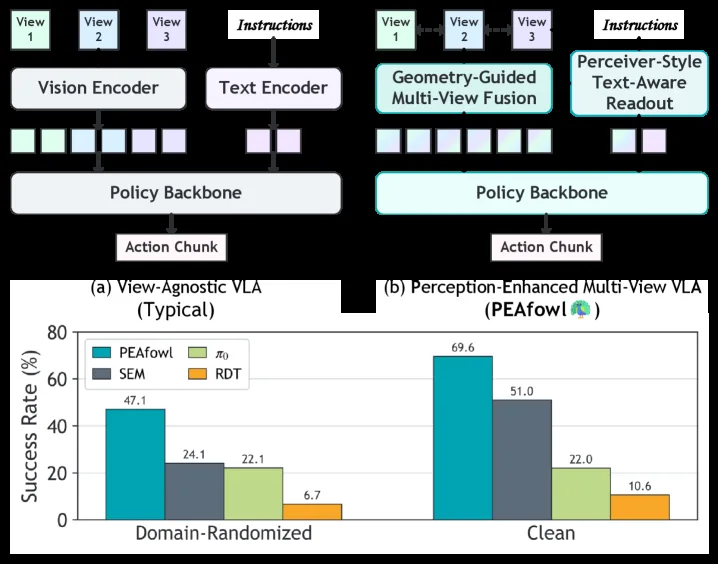
- Clean 设置:PEAfowl 平均成功率 69.6%,比最强基线 SEM (51.0%) 高出 18.6 pp
- DR 设置:PEAfowl 平均成功率 47.1%,比最强基线 (24.1%) 高出 23.0 pp
- 泛化到新任务:在 2 个未见过任务上,PEAfowl 在 Clean 和 DR 设置下均显著优于基线
- 消融实验:深度蒸馏显著改善了深度预测质量,使模型在低重叠视场等困难真实场景中保持良好性能