一眼看懂
封面预览
研究目标: 赋予视觉-语言-动作模型 (VLAs) 主动自我纠正能力,使其能够在执行过程中检测到即将发生的错误并在失败完全显现之前进行恢复
- 研究目标: 赋予视觉-语言-动作模型 (VLAs) 主动自我纠正能力,使其能够在执行过程中检测到即将发生的错误并在失败完全显现之前进行恢复
- 核心问题: 现有机器人失败检测和纠正方法通常是事后处理 (post-hoc),即只有在失败发生后才进行分析和纠正,而人类可以在错误发生时就进行…
- 关键观察: 许多任务失败发生在子任务转换期间,当接近子任务完成时的进度提供了预测失败的强烈线索
Card 01
研究单位
研究单位
- University of Oxford - Department of Computer Science
- Chenyang Ma, Kai Lu, Shitong Xu, Niki Trigoni, Andrew Markham
- University of Cambridge - Department of Engineering
- Guangyu Yang, Bill Byrne
Card 02
论文概述
论文概述
- 研究目标: 赋予视觉-语言-动作模型 (VLAs) 主动自我纠正能力,使其能够在执行过程中检测到即将发生的错误并在失败完全显现之前进行恢复
- 核心问题: 现有机器人失败检测和纠正方法通常是事后处理 (post-hoc),即只有在失败发生后才进行分析和纠正,而人类可以在错误发生时就进行调整
- 关键观察: 许多任务失败发生在子任务转换期间,当接近子任务完成时的进度提供了预测失败的强烈线索
Card 03
核心贡献
核心贡献
- 提出 CycleVLA 系统,通过三个关键组件实现 VLAs 的主动自我纠正能力:
- 微调 pipeline:为 VLAs 扩展子任务进度预测能力 (stop signal 和 progress signal)
- VLM-based 失败预测器和规划器:在子任务边界决定是转换到下一子任务还是回溯
- MBR 解码的测试时扩展策略:在回溯后重试时提高成功率
- 证明 MBR 解码可作为 VLAs 的零样本测试时扩展策略,无需额外训练即可提高策略成功率
- 在 LIBERO 基准上验证,展示了在长期任务上的显著改进,以及对训练不足的 VLAs 仍然有效
Card 04
方法描述
方法描述
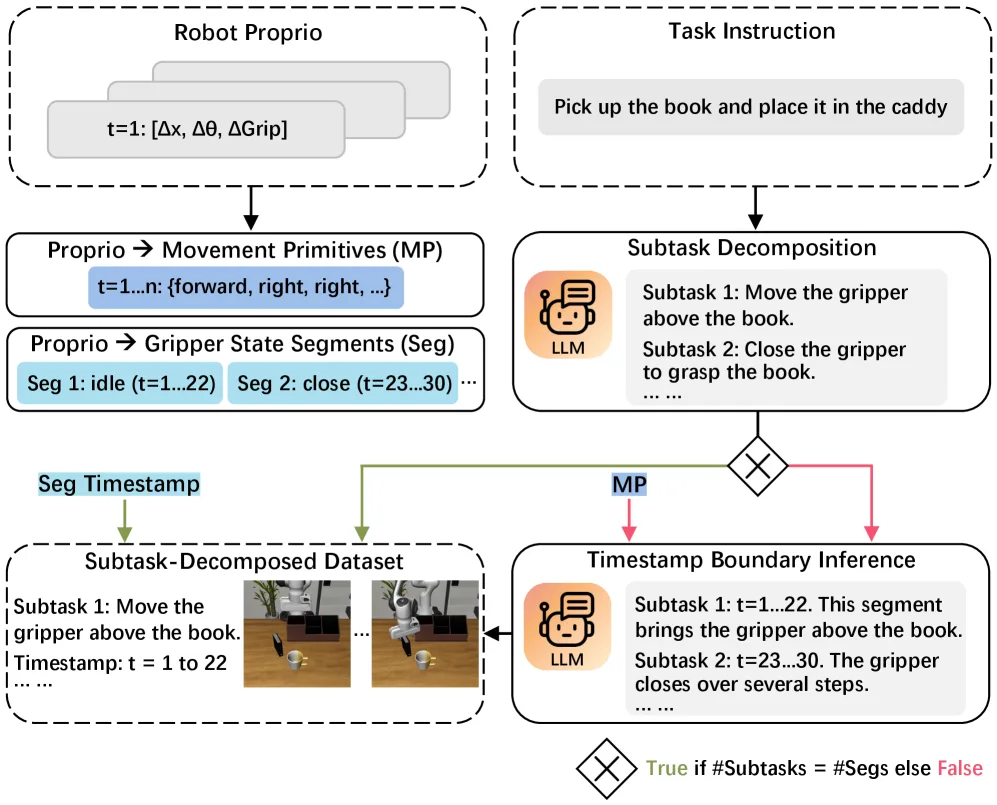
- 子任务分解 pipeline:使用 LLM 将演示分解为带有精确时间戳的子任务,通过夹爪状态转换段落来对齐子任务边界
- 子任务微调:扩展 VLA 的动作维度 (7维 → 9维),添加 stop signal 和 progress signal 的预测,在训练时对每个子任务的最后一步进行过采样以强调终止检测
- 失败预测和规划:VLM 作为零样本失败预测器,当 VLA 预测的进度达到阈值 (τ_p = 0.9) 时触发查询,决定 transit 或 backtrack
- MBR 解码:采样多个动作假设,选择使预期风险最小的动作序列,通过 L2 距离度量选择共识轨迹
Card 05
数据集与资源
数据集与资源
- 基准数据集: **LIBERO (Spatial, Object, Goal, Long 四个任务套件)
- VLA 骨干模型: OpenVLA,采用 diffusion-based action expert
- 训练配置: 4x NVIDIA A100 GPUs (40GB VRAM),500K 训练 steps
- 推理配置: NVIDIA A10 GPU (24GB VRAM)
- 子任务分解: 使用 GPT-4.1 (temperature 0.2)
- 失败预测器: GPT-5.2 (temperature 1.0) 作为 VLM
- MBR 参数: N=8 个采样假设,L2 距离度量
Card 06
评估与结果
评估与结果
- 主要指标: 任务成功率 (success rate ↑)
- 关键结果:
\|任务套件 \|Spatial \|Object \|Goal \|Long \|Average \|
\|
--
-\|
--
--\|
--
\|
---\|
---\|
--
-\|
\|CycleVLA \|97.6% \|98.1% \|91.7% \|93.6% \|95.3% \|
- **关键发现:
- 在 LIBERO-Long 任务套件上提升最为显著 (93.6% vs 之前最好的 82.2%)
- 对训练不足的 VLAs 同样有效:200K checkpoint 通过 CycleVLA 达到了 350K checkpoint 的性能水平