一眼看懂
封面预览
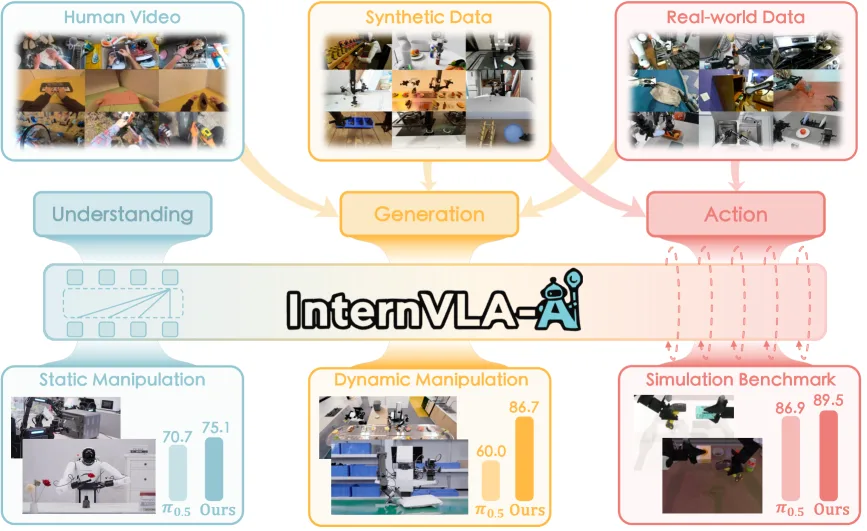
提出 InternVLA-A1,一个统一的视觉-语言-动作(VLA)框架,将场景理解、视觉预见生成和动作执行整合到单一架构中
- 提出 InternVLA-A1,一个统一的视觉-语言-动作(VLA)框架,将场景理解、视觉预见生成和动作执行整合到单一架构中
- 解决现有 VLA 模型的物理世界动态推理能力不足和世界模型缺乏语义基础的问题
- 采用混合 Transformer(MoT)架构协调三个专家,在 692M 帧异构数据上预训练,在动态场景中表现出色
Card 01
研究单位
研究单位
- Shanghai AI Laboratory(上海人工智能实验室)
- Humanoid Robot (Shanghai) Co., Ltd.(上海人形机器人有限公司)
Card 02
论文概述
论文概述
- 提出 InternVLA-A1,一个统一的视觉-语言-动作(VLA)框架,将场景理解、视觉预见生成和动作执行整合到单一架构中
- 解决现有 VLA 模型的物理世界动态推理能力不足和世界模型缺乏语义基础的问题
- 采用混合 Transformer(MoT)架构协调三个专家,在 692M 帧异构数据上预训练,在动态场景中表现出色
Card 03
核心贡献
核心贡献
- 提出统一的三专家架构:理解专家(Understanding Expert)、生成专家(Generation Expert)和动作专家(Action Expert)
- 视觉预见生成模块:使用轻量级 VAE tokenizer(COSMOS CI8×8)和并行解码预测未来帧,推理速度约 13Hz
- 动作预测:采用 Flow Matching 框架处理多模态动作分布
- 异构数据联合训练:结合模拟数据、真实机器人和人类视频,有效减少 sim-to-real gap
- 在 12 项真实机器人任务和模拟基准测试中一致优于现有 SOTA 模型
Card 04
方法描述
方法描述
- 架构:基于 InternVL3-1B(2B 版本)和 Qwen3-VL-2B(3B 版本)的 MoT 架构
- 理解专家:处理多视角图像和文本指令,生成上下文嵌入
- 生成专家:使用 VAE 将图像编码为 32×32 潜在网格,通过 token 压缩(8×8 卷积)降至 4×4(16 tokens),并行解码生成未来帧
- 动作专家:结合本体感知状态和前两个专家的特征,使用 Flow Matching 输出动作块
- 注意力机制:采用分块注意力掩码,实现严格的信息流:理解 → 生成 → 动作
- 训练:两阶段(预训练 700K 步 + 后训练 60K 步),联合优化视觉生成损失和动作预测损失
Card 05
数据集与资源
数据集与资源
- 预训练数据(总计 692M 帧):
- 模拟数据:InternData-A1(396M 帧,64% 采样权重)、RoboTwin(17M 帧,8%)
- 真实机器人数据:AgiBot-World Beta(206M 帧,18%)、RoboMind(5M 帧,2%)
- 人类视频:EgoDex(68M 帧,8%)
- 模型规模:InternVLA-A1(2B):1.8B 参数;InternVLA-A1(3B):3.2B 参数
- 训练资源:使用 Load-balanced Parallel Training(LPT)分布式策略,在 8 张 RTX 4090 GPU 上可生成 209.7 小时/天的模拟数据
- 推理速度:使用 torch.compile 在单张 RTX 4090 上约 13 Hz
Card 06
评估与结果
评估与结果
- 评估环境:三种机器人平台(Agibot Genie-1、ARX Lift-2、ARX AC One),12 项真实任务 + RoboTwin 2.0 模拟基准
- 评估指标:平均成功率(30 次 rollout/任务)
- 主要结果:
- 静态任务:InternVLA-A1(3B)达 75.1%,超越 π₀(60.6%)和 π₀.5(70.7%)
- 动态任务:InternVLA-A1(3B)达 86.7%,Express Sorting 超越 π₀.5 达 +26.7%,In-motion Ingredient Picking 超越 +26.6%
- RoboTwin 2.0:Easy 和 Hard 模式分别达 89.4% 和 89.6%,超越 π₀.5 达 +2.6%
- 消融实验:
- 预训练至关重要:移除后成功率从 77.0% 降至 25.4%
- 异构数据联合训练最优:模拟+真实+人类视频组合效果最好
- 生成专家是关键:移除后在 11/12 任务中性能下降,平均下降 19.4%