一眼看懂
封面预览
论文提出Action-Sketcher框架,用于解决长时域机器人操作中的空间歧义和时间脆弱性问题
- 论文提出Action-Sketcher框架,用于解决长时域机器人操作中的空间歧义和时间脆弱性问题
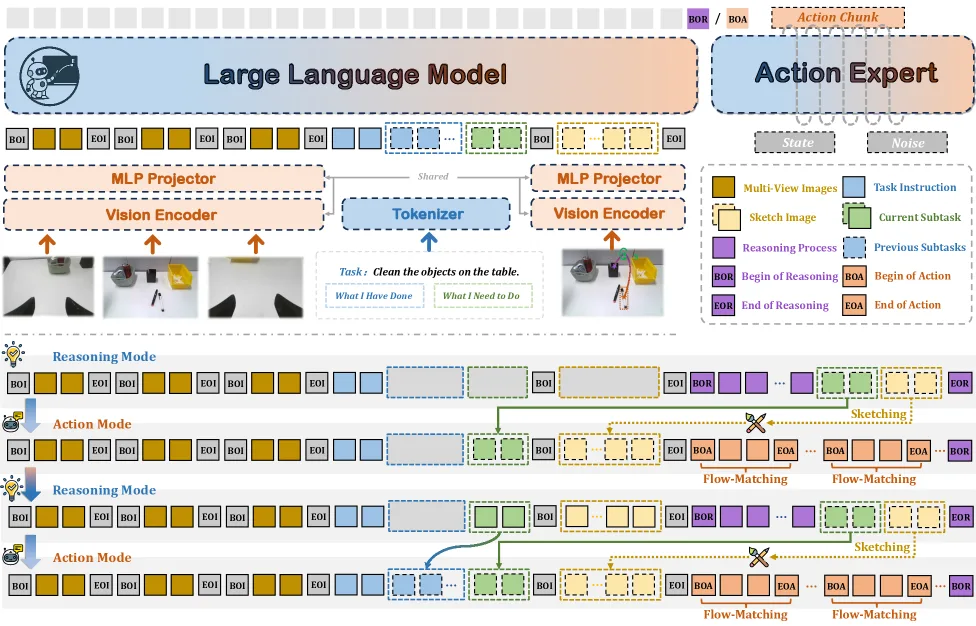
- 核心创新是引入Visual Sketch(视觉草图),一种显示的视觉中间表示,由点、边界框和箭头组成,用于外化空间意图
- 框架采用See-Think-Sketch-Act循环流程,通过自适应token门控策略在推理模式和动作模式之间切换
Card 01
研究单位
研究单位
- 北京大学 - 多媒体信息处理国家重点实验室,计算机科学学院
- 北京人工智能研究院
- 悉尼大学
- 中国科学院 - 自动化研究所
Card 02
论文概述
论文概述
- 论文提出Action-Sketcher框架,用于解决长时域机器人操作中的空间歧义和时间脆弱性问题
- 核心创新是引入Visual Sketch(视觉草图),一种显示的视觉中间表示,由点、边界框和箭头组成,用于外化空间意图
- 框架采用See-Think-Sketch-Act循环流程,通过自适应token门控策略在推理模式和动作模式之间切换
Card 03
核心贡献
核心贡献
- Visual Sketch形式化:将空间意图表示为稀疏的几何原语(点、边界框、箭头),作为高级推理与低级控制之间的可验证契约
- Action-Sketcher框架:实现See-Think-Sketch-Act循环,通过
和 token实现自适应模式切换,支持实时中断处理和草图级修正 - 多阶段课程训练:结合时空基础学习、推理到草图增强、草图到动作强化,使用模式平衡采样策略防止模式偏差
- 人类在环交互:由于Visual Sketch是可解释的,人类可以暂停执行并修正生成的草图,显著提升成功率
Card 04
方法描述
方法描述
- Visual Sketch定义:S_t = (B_t, P_t, A_t),其中B_t是目标区域边界框,P_t是关键点集合,A_t是运动箭头(包括平移和旋转箭头)
- See-Think-Sketch-Act管道:模型在推理模式(生成子任务和草图)和动作模式(生成动作块)之间自适应切换
- 模型结构:基于π_0作为骨干,结合自回归文本生成和flow-matching动作预测
- 训练策略:Stage 1时空基础学习(3.4M样本),Stage 2推理到草图增强(21k样本),Stage 3草图到动作和模式适应
Card 05
数据集与资源
数据集与资源
- 训练数据:3.4M空间理解样本,870k时序学习序列,2.6k真实世界长时域任务 episodes,1.7k标注轨迹
- 评估基准:LIBERO(lifelong skills benchmark),RoboTwin 2.0(增强版仿真)
- 真实机器人平台:Agilex和Galaxea双臂机器人平台
- 测试任务:整理杂乱桌面、倒茶、通用抓取放置
Card 06
评估与结果
评估与结果
- LIBERO基准:Action-Sketcher在Long类别达到96.0%成功率,平均96.9%,显著优于基线方法
- RoboTwin 2.0仿真:Stack Blocks任务34.5%,Place A2B Left任务43.0%,Place A2B Right任务28.0%
- 真实世界任务:Tidy Table 52.0%,Pour Tea 27.6%,Pick & Place 67.0%
- 人类在环修正:Tidy Table从52.0%提升至75.0%,Pick & Place从67.0%提升至85.5%
- 消融实验:移除Visual Sketch降至9.8%(仿真),移除Stage 3完全失败(0.0%),证明各组件的必要性